The Databricks Jobs API allows users to programmatically create, run, and delete Databricks Jobs via their REST API solution. This is an alternative to running Databricks jobs through their console UI system. For access to other Databricks platforms such as SQL warehouses, delta live tables, unity catalog, or others, users will have to implement other API solutions provided by Databricks.
The official Databricks Jobs API reference can be found here.
However, for newcomers to the Jobs API, I recommend starting with the Databricks Jobs documentation which has great examples and more detailed explanations.
Why should I use the Jobs API?
Users may want to use an API, vs. the UI, when they need to dynamically create jobs due to other events, or to integrate with other non-Databricks workflows, for example Airflow or Dagster. Users can implement job tasks using notebooks, Delta Live Tables pipelines, JARS, or Python, Scala, Spark submit, and Java applications.
Another reason to use the Jobs API is to retrieve and aggregate metrics about your jobs to monitor usage, performance, and costs. The information in the Jobs API is far more granular than those present in the currently available System Tables.
So if your organization is looking to monitor thousands of jobs at scale and build dashboards, you will have to use the Jobs API to collect all of the information.
What can I do with the Jobs API?
A full list of the Jobs API PUT and GET requests can be found in the table below, based on the official API documentation.
| Action | Request | Description |
| Get job permissions | /api/2.0/permissions/jobs/{job_id} | Gets the permissions of a job such as ‘user name’, ‘group name’, ‘service principal’, ‘permission level’ |
| Set job permissions | /api/2.0/permissions/jobs/{job_id} | Sets permissions on a job. |
| Update job permissions | /api/2.0/permissions/jobs/{job_id} | Updates the permissions on a job. |
| Get job permission levels | /api/2.0/permissions/jobs/{job_id}/permissionLevels | Gets the permission levels that a user can have on an object |
| Create a new job | /api/2.1/jobs/create | Create a new Databricks Job |
| List jobs | /api/2.1/jobs/list | Retrieves a list of jobs and their parameters such as ‘job id’, ‘creater’, ‘settings’, ‘tasks’ |
| Get a single job | /api/2.1/jobs/get | Gets job details for a single job |
| Update all job settings (reset) | /api/2.1/jobs/reset | Overwrite all settings for the given job. |
| Update job settings partially | /api/2.1/jobs/update | Add, update, or remove specific settings of an existing job |
| Delete a job | /api/2.1/jobs/delete | Deletes a job |
| Trigger a new job run | /api/2.1/jobs/run-now | Runs a job with an existing job-id |
| Create and trigger a one-time run | /api/2.1/jobs/runs/submit | Submit a one-time run. This endpoint allows you to submit a workload directly without creating a job. Runs submitted using this endpoint don’t display in the UI. |
| List job runs | /api/2.1/jobs/runs/list | List runs in descending order by start time. A run is a job that has already historically been run. |
| Get a single job run | /api/2.1/jobs/runs/get | Retrieve the metadata of a single run. |
| Export and retrieve a job run | /api/2.1/jobs/runs/export | Export and retrieve the job run task. |
| Cancel a run | /api/2.1/jobs/runs/cancel | Cancels a job run |
| Cancel all runs of a job | /api/2.1/jobs/runs/cancel-all | Cancels all job runs |
| Get the output for a single run | /api/2.1/jobs/runs/get-output | Retrieve the output and metadata of a single task run. |
| Delete a job run | /api/2.1/jobs/runs/delete | Deletes a job run |
| Repair a job run | /api/2.1/jobs/runs/repair | Repairs a job run by re-running it |
Can I get cost information through the Jobs API?
Unfortunately, users cannot obtain jobs cost directly through the Jobs API. You’ll need to use the accounts API to access billing information, or use System tables. One big note, is the billing information retrieved through either the accounts API or the system tables is only the Databricks DBU costs.
The majority of your Databricks costs could come from your actual cloud usage (e.g. on AWS it’s the EC2 costs). To obtain these costs you’ll need to separately retrieve cost information from your cloud provider.
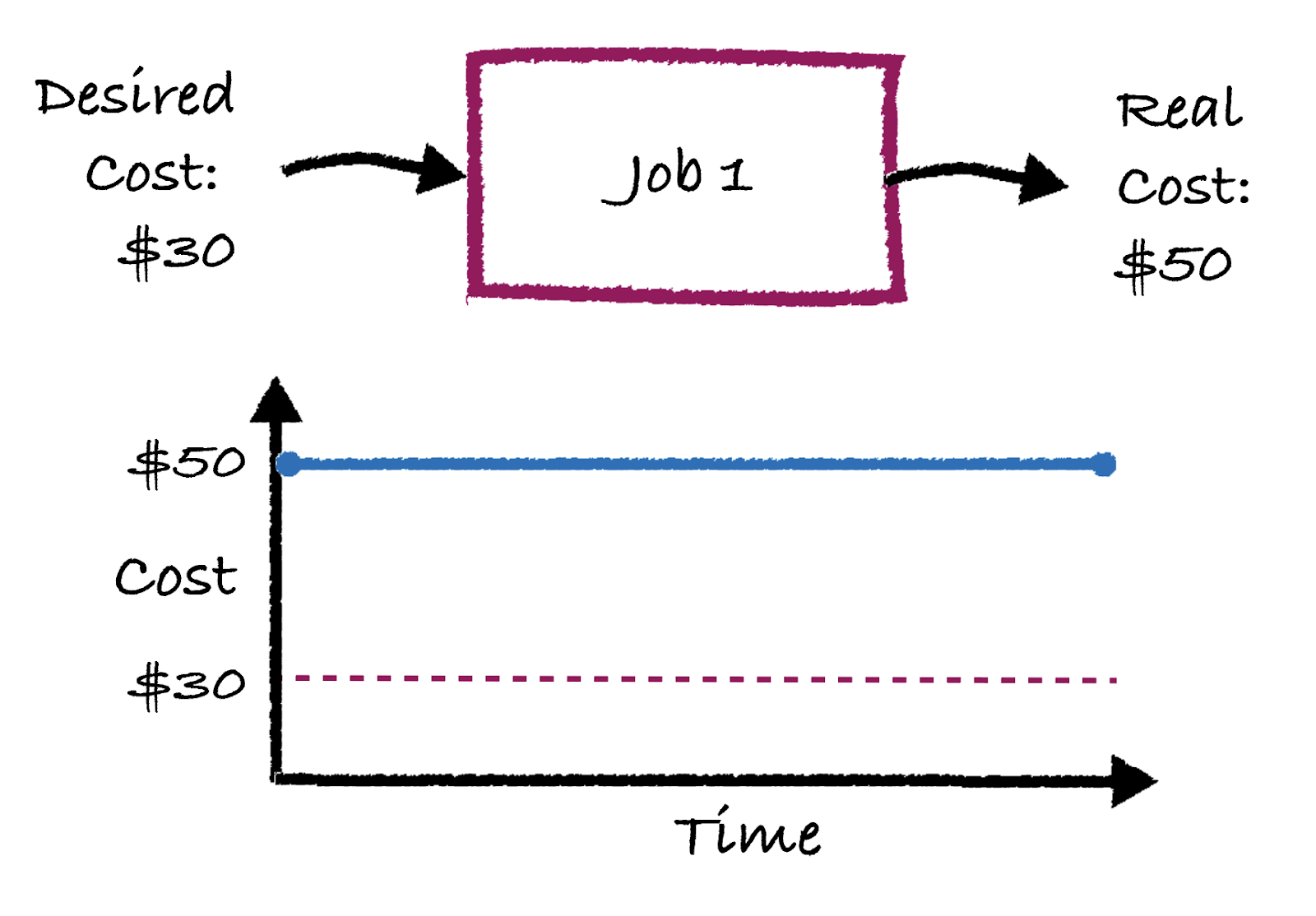
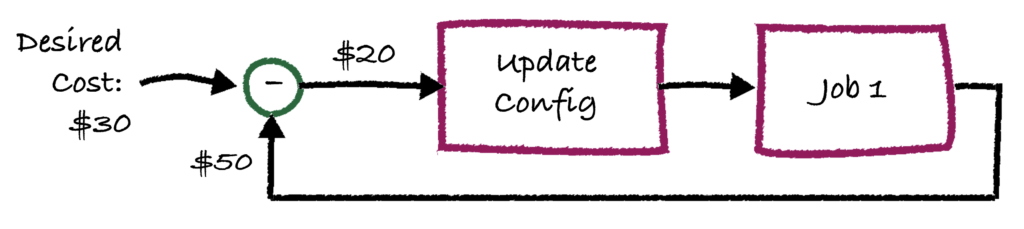
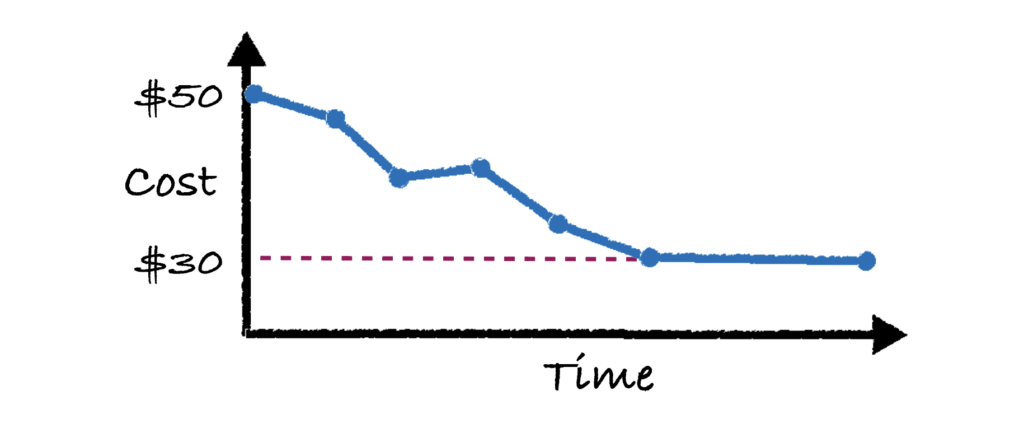
If this sounds painful – you’re right, it’s crazy annoying. Fortunately, Gradient does all of this for you and can retrieve both the DBU and cloud costs for you in a simple diagram to monitor your costs.
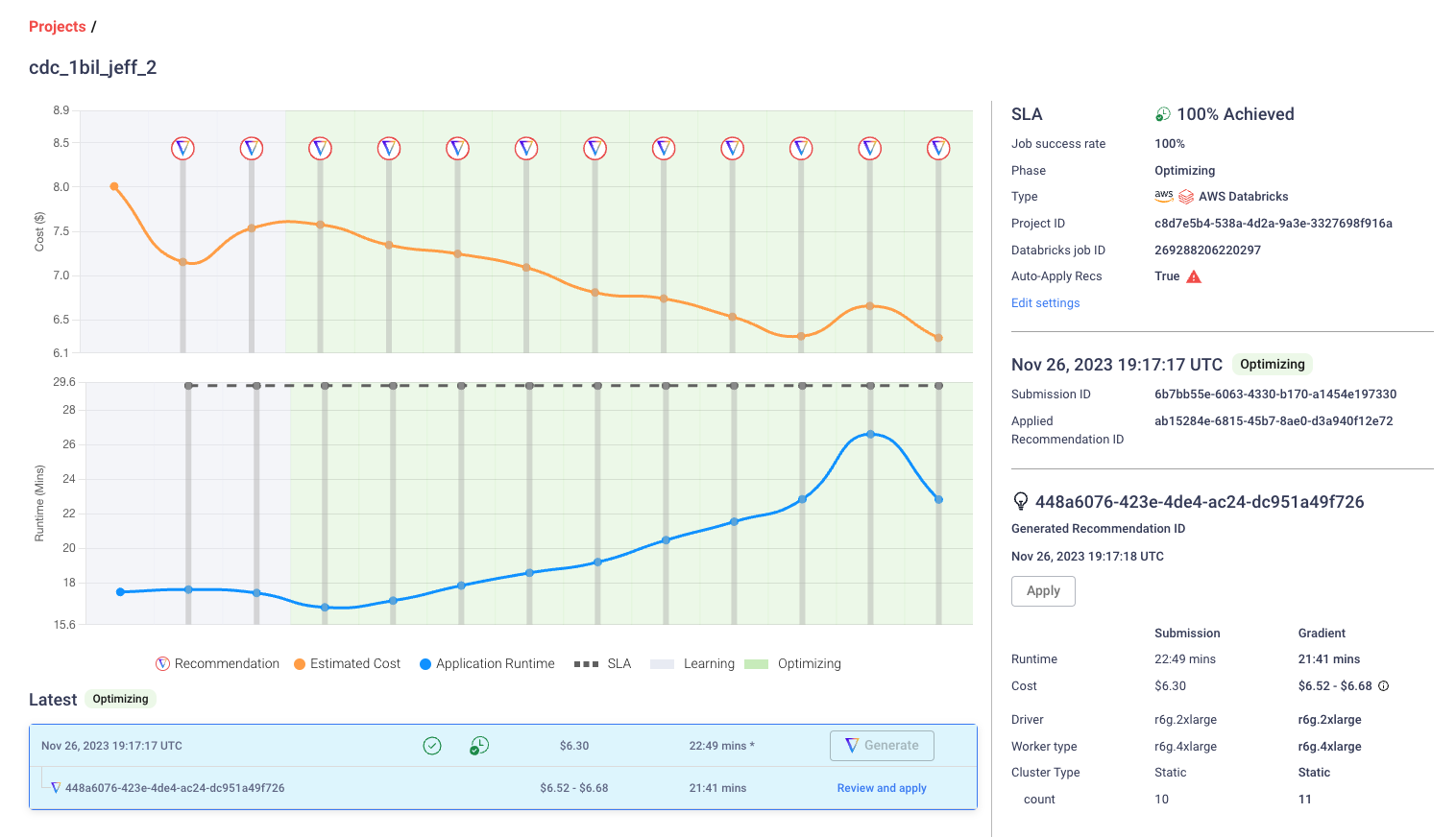
How does someone intelligently control their Jobs clusters with the API?
The Jobs API is an input/output system only. What you do with the information and abilities to control and manage Jobs is entirely up to you and your needs.
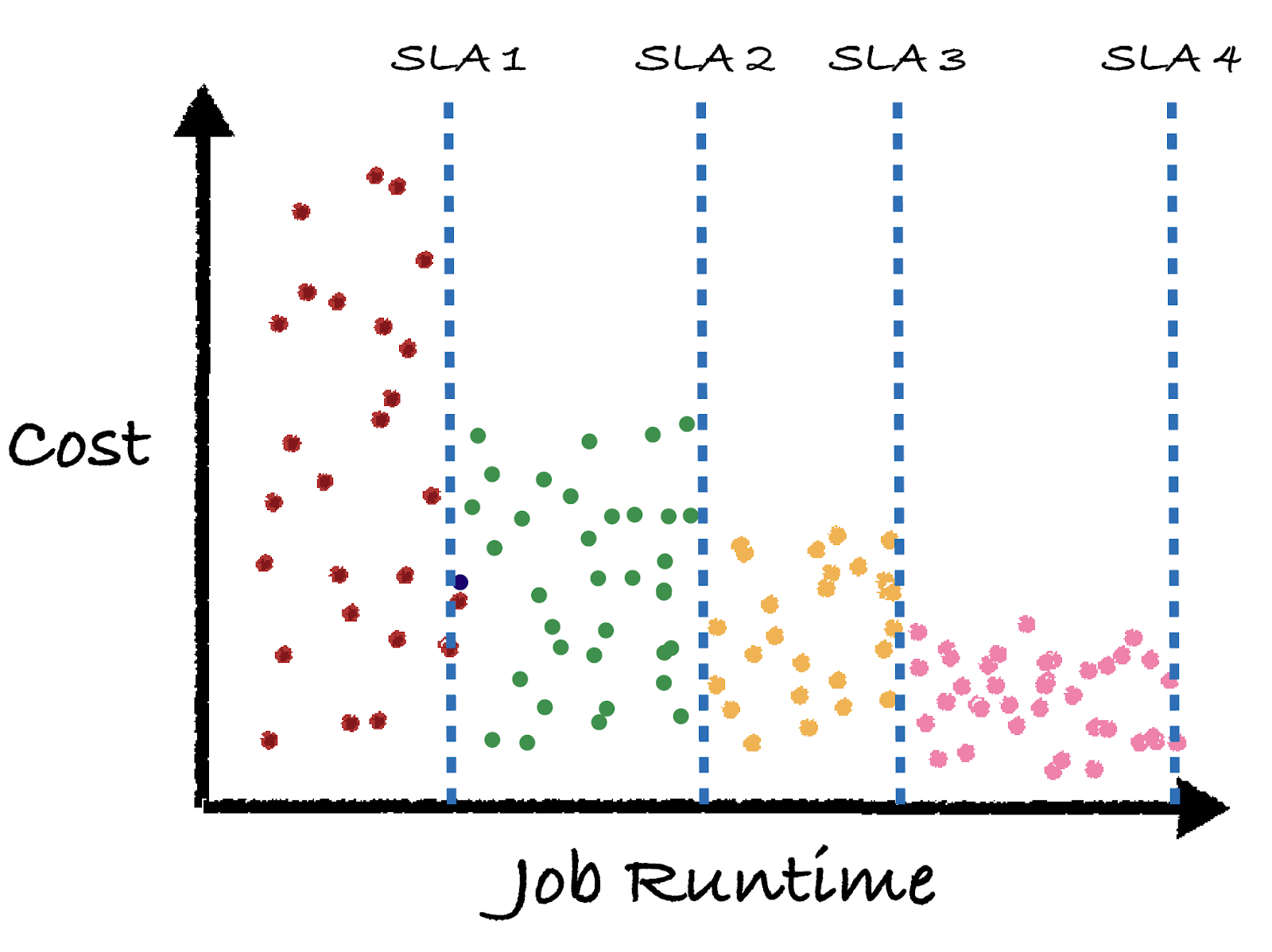
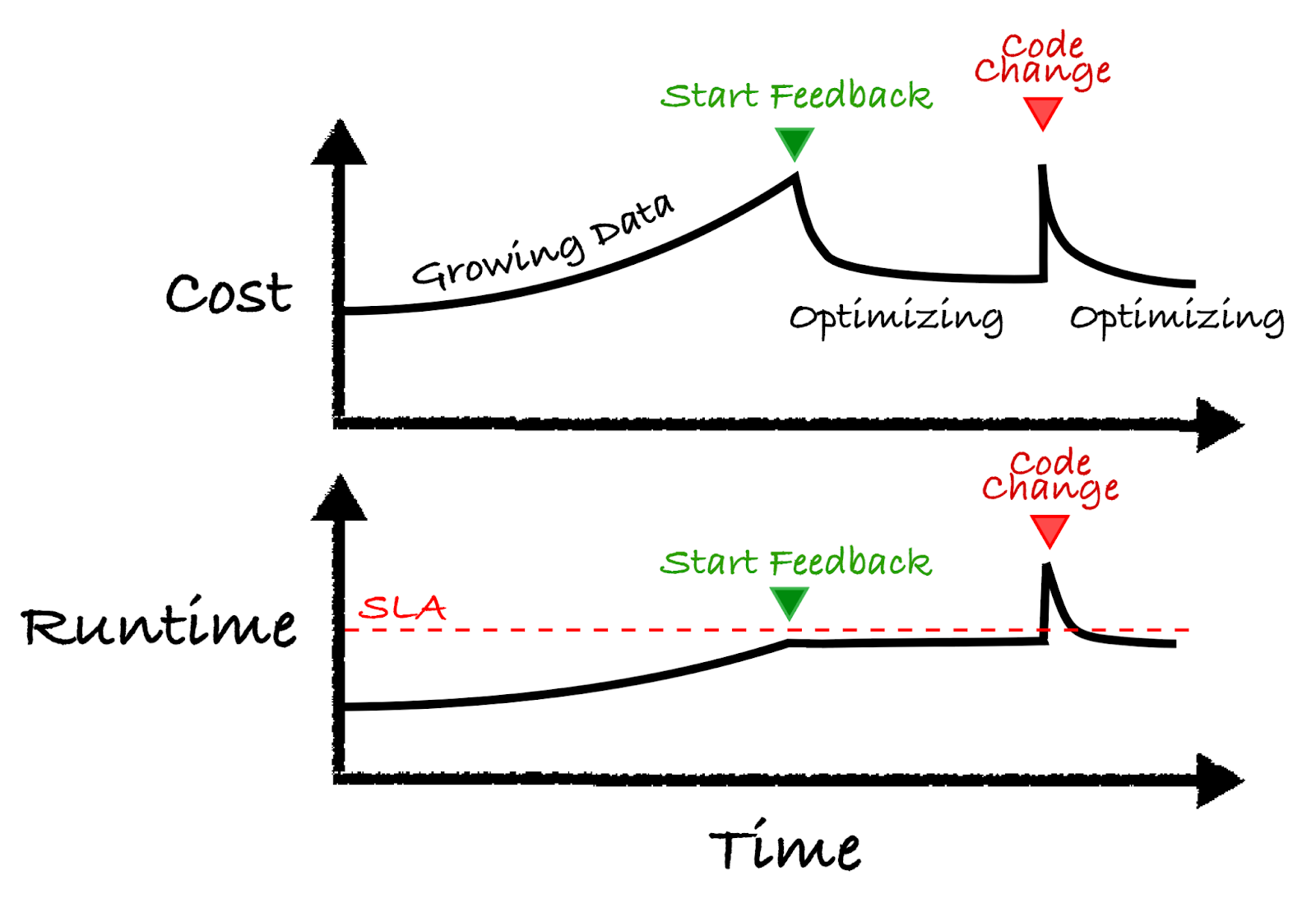
For users running Databricks Jobs at scale, one dream ability is to optimize and intelligently control jobs clusters to minimize costs and hit SLA goals. Building such a system is not trivial and requires an entire team to develop a custom algorithm as well as infrastructure.
Here at Sync, we built Gradient to solve exactly this need. Gradient is an all-in-one Databricks Jobs intelligence system that works with the Jobs API to help automatically control your jobs clusters. Check out the documentation here to get started.
Updating From Jobs API 2.0 to 2.1
The largest update from API 2.0 to 2.1 is the inclusion of multiple tasks in a job, as described in the official documentation. To explain a bit more, Databricks jobs can contain multiple tasks in a single job, where each task can be a different notebook, for example. All API 2.1 requests must conform to the multi-task format and responses are structured in the multi-task format.
Databricks jobs api example
Here is an example, borrowed from the official documentation, of how to create a job:
To create a job with the Databricks REST API, run the curl command below, which creates a cluster based on the parameters located in the create-job.json
curl --netrc --request POST \
https://<databricks-instance>/api/2.0/jobs/create \
--data @create-job.json \
| jq .
An example of what goes into the create-job.json is found below
{
"name": "Nightly model training",
"new_cluster": {
"spark_version": "7.3.x-scala2.12",
"node_type_id": "r3.xlarge",
"aws_attributes": {
"availability": "ON_DEMAND"
},
"num_workers": 10
},
"libraries": [
{
"jar": "dbfs:/my-jar.jar"
},
{
"maven": {
"coordinates": "org.jsoup:jsoup:1.7.2"
}
}
],
"email_notifications": {
"on_start": [],
"on_success": [],
"on_failure": []
},
"webhook_notifications": {
"on_start": [
{
"id": "bf2fbd0a-4a05-4300-98a5-303fc8132233"
}
],
"on_success": [
{
"id": "bf2fbd0a-4a05-4300-98a5-303fc8132233"
}
],
"on_failure": []
},
"notification_settings": {
"no_alert_for_skipped_runs": false,
"no_alert_for_canceled_runs": false,
"alert_on_last_attempt": false
},
"timeout_seconds": 3600,
"max_retries": 1,
"schedule": {
"quartz_cron_expression": "0 15 22 * * ?",
"timezone_id": "America/Los_Angeles"
},
"spark_jar_task": {
"main_class_name": "com.databricks.ComputeModels"
}
}Azure databricks jobs api
The REST APIs are identical across all 3 cloud providers (AWS, GCP, Azure). Users can toggle between the different cloud versions in the reference page on the top left corner
Conclusion
The Databricks Jobs API is a powerful system which enables to programmatically control and monitor their jobs. Likely this is useful for “power users” who want to control many jobs or for users who need to use an external orchestrator, like Airflow, to orchestrate their jobs.
To add automatic intelligence to your Databricks Jobs API solutions to help lower costs and hit SLAs, check out Gradient as a potential fit.
Useful Links
How To Optimize Databricks Clusters
Databricks Instructor-Led Courses
Databricks Guided Access Support Subscription