AI for your Databricks infrastructure
Gain full visibility and control of your Databricks Jobs with ML-powered cluster management. Save up to 50% on compute spend and consistently meet your runtime SLAs with AI optimization.



ML-powered optimization for Databricks infra
Enjoy the ease of serverless without the cost of convenience. Gradient by Sync uses advanced ML algorithms developed in MIT to provide automated compute optimization for organizations running their data infrastructure on CPUs or GPUs on the cloud.

How
Gradient
helps:
50% cost savings
with zero effort

Hit all your
critical SLAs

25% engineering
hours saved

Continuous
optimization

Complete cost and performance visibility

Optimize complex
data pipelines

Fully customizable
ML models

Optimization
at scale

I’d be surprised if there was any data team on the planet that wouldn’t save money and time from using Gradient.
Jesse Lancaster, CTO, Forma.ai




50
%
cost savings
2
x
faster
200
%
Starting ROI
100
%
SLAs met
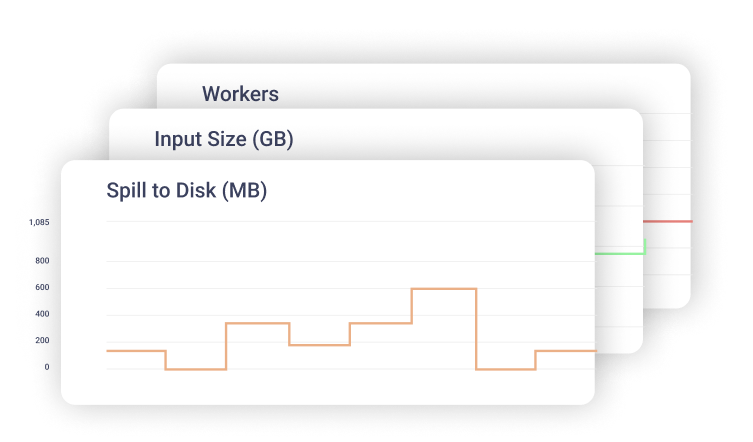
Fine-grained reporting
Gain full visibility into job costs and performance. Get all the granular information as well as overall spend, total savings, and ROI.
Compliant and secure
Gradient is SOC2 type II certified. And it automatically logs every recommendation and change it makes for easy compliance and auditability.

Works with your stack
Supports AWS, Azure, GCP (soon), and NVIDIA GPUs. Integrates with data orchestration/transformation services, such as Airflow, Azure Data Factory, and dbt.
Get started in minutes
Schedule a call to learn more about Gradient and how it can help you meet your compute goals with AI