FEATURES
Intelligent Monitoring and Alerting
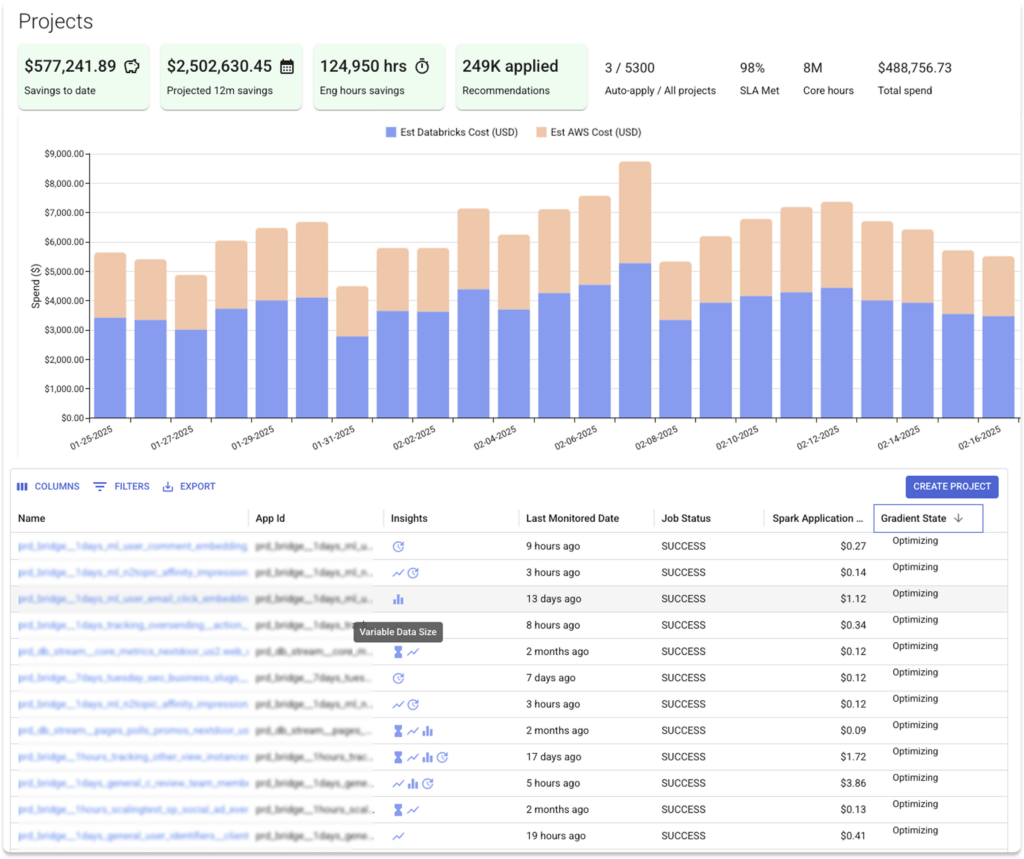
Gain actionable insights into your data pipelines with Gradient’s intelligent monitoring and alerting. Effortlessly identify opportunities, detect anomalies, and take action.
ML-powered insights
Monitor the right metrics, get instant anomaly alerts, and take proactive actions
Actionable insights
Insights, not just reports. Gradient continuously monitors your jobs to provide actionable insights. Instantly detect and react to increases in job failures, performance anomalies, cost spikes data size fluctuations, and more with Gradient.
Proactive optimization
Identify your most expensive jobs and detect inefficiencies and misconfigurations across your Databricks workspace. Gradient’s intelligent monitoring focuses just on the metrics that have been proven to impact job costs and performance.

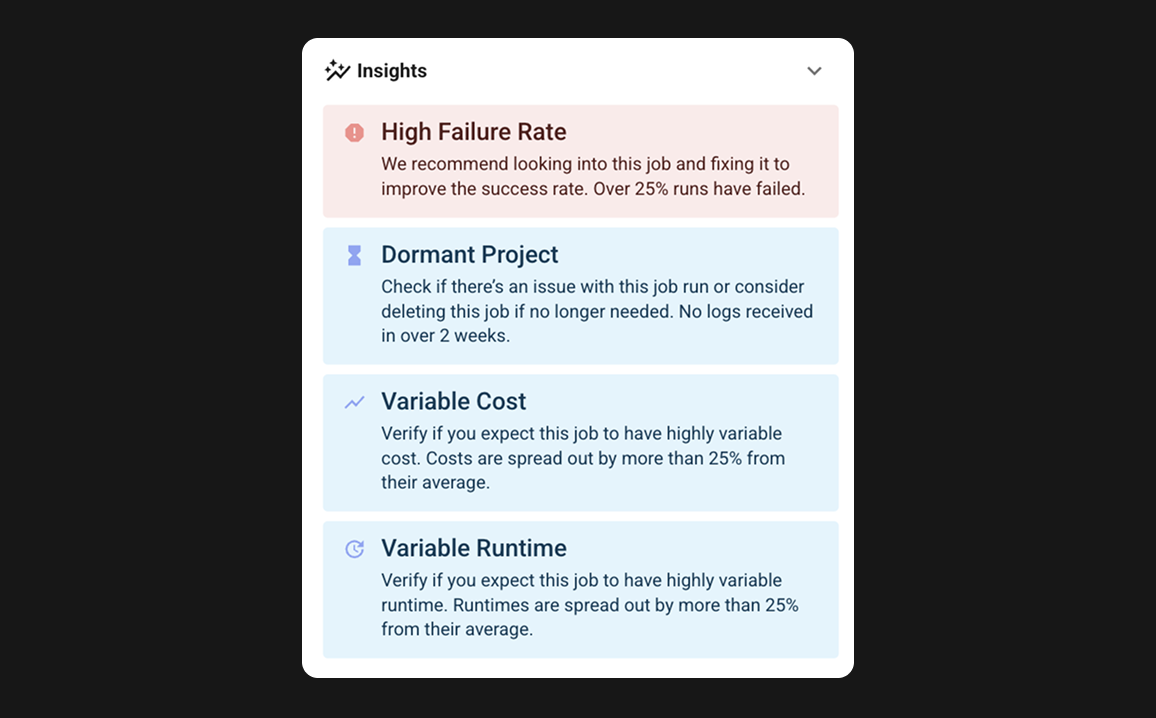
Automatic anomaly
alerts
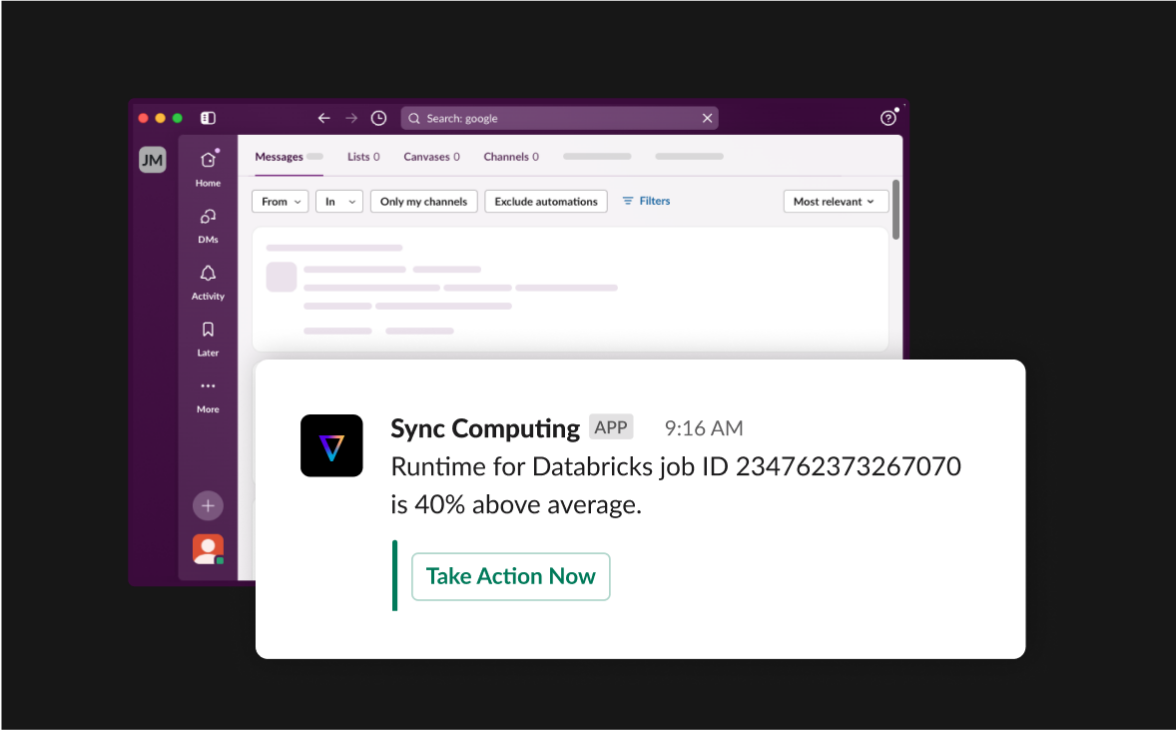
Stay informed about critical issues and anomalies in your data pipelines. Get notified instantly of performance bottlenecks, cost increases, data size spikes, etc., so you can respond quickly and maintain optimal operations.
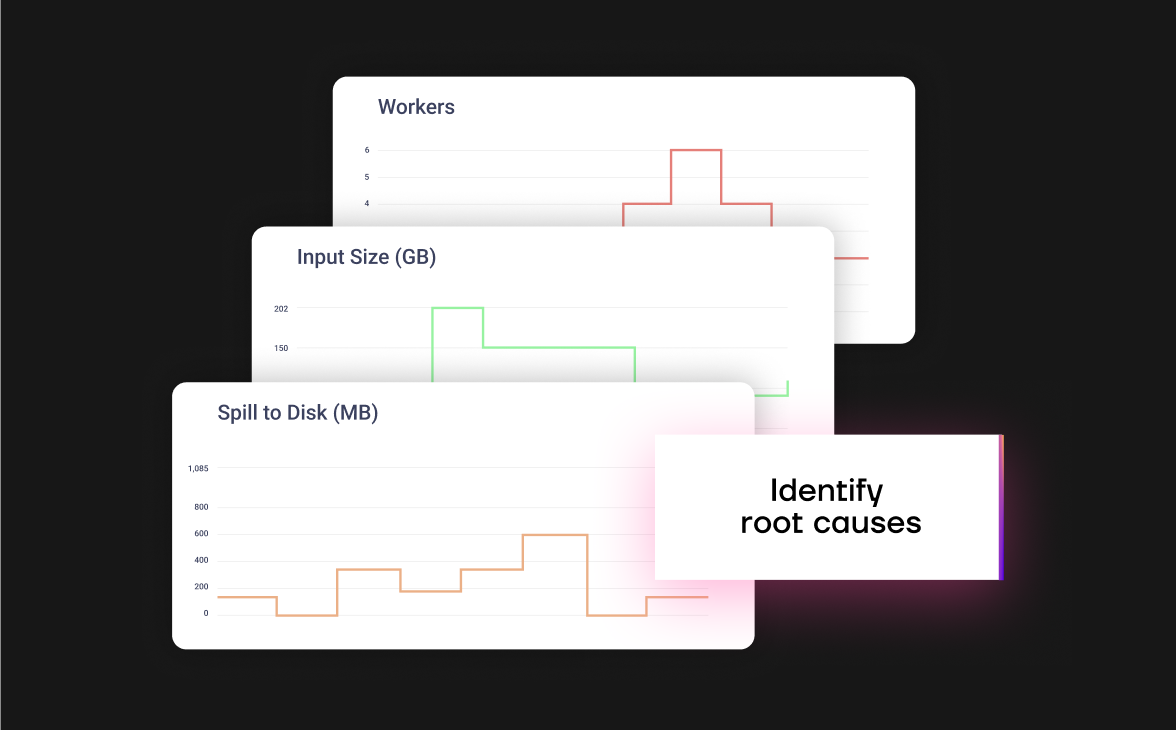
Effortless
root cause analysis
Quickly identify the source of performance issues or unexpected behaviors in your Databricks jobs. Gradient’s intelligent monitoring helps you pinpoint the root causes of anomalies, saving you time and resources in troubleshooting.
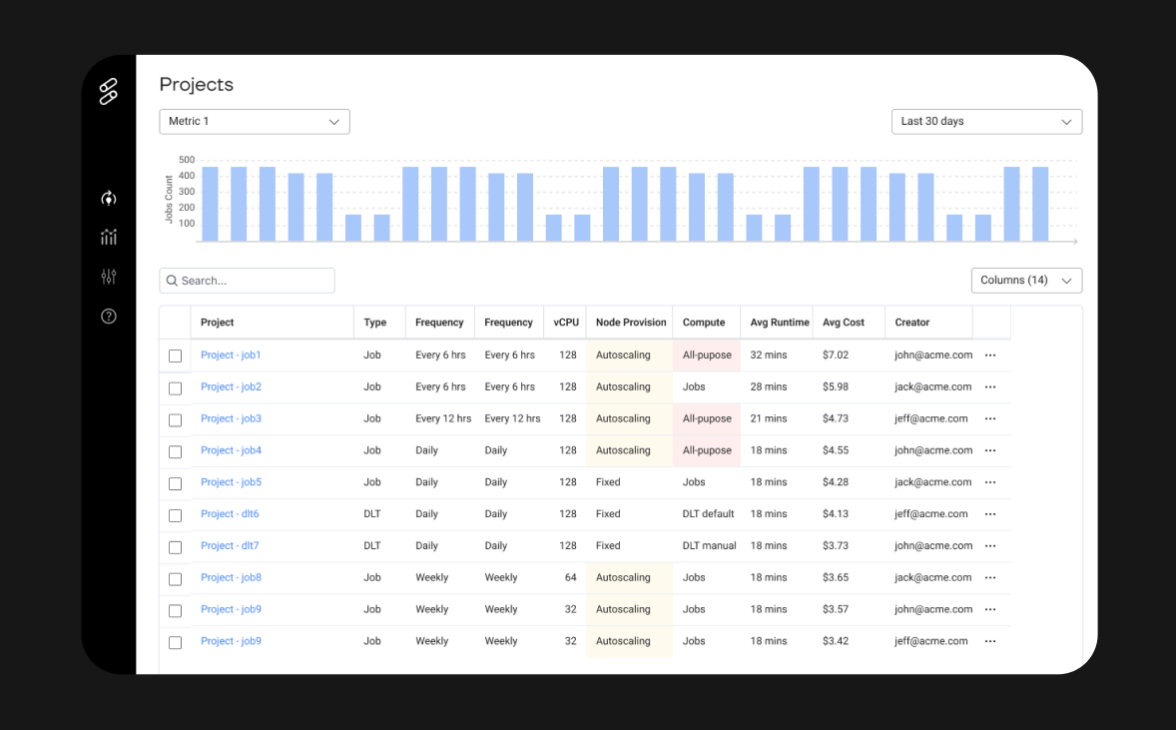
Single pane of glass for compute
Get a bird’s eye view of your data infrastructure with Gradient. View all of your jobs, assess costs and performance, and take action from one place.
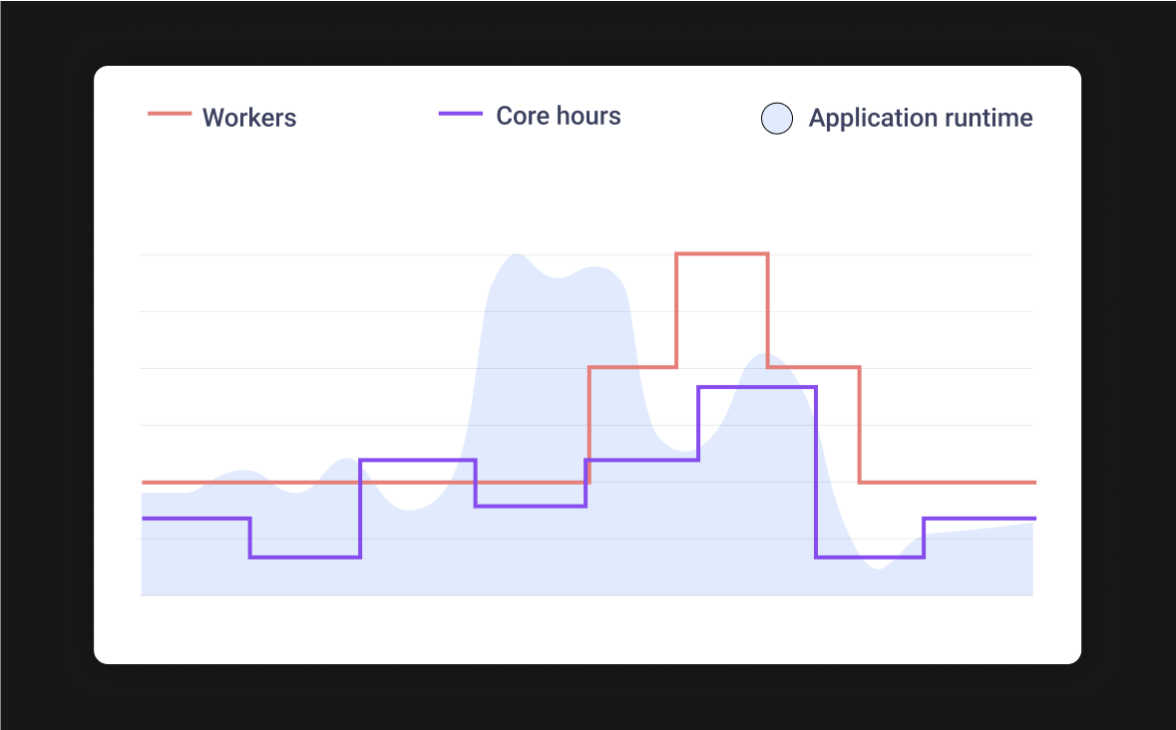
Detect trends
over time
Track key metrics over time to identify patterns and long-term trends in your data pipelines. Proactively optimize your jobs and prevent potential issues before they arise.
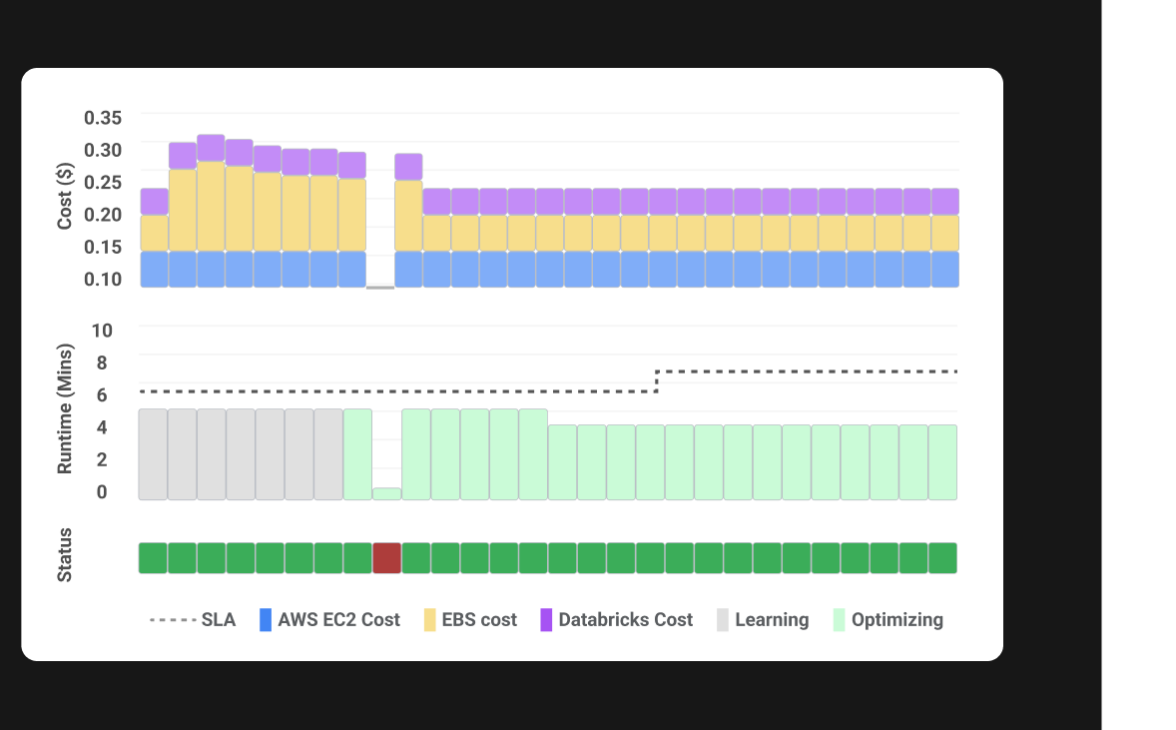
Granular job-level reports
Enjoy unprecedented visibility into your data pipelines with granular reports of job performance. Our reports highlight the Spark metrics that impact job costs and performance.
Works with your data tools
Monitor all your jobs, even those orchestrated by Airflow, Azure Data Factory, Databricks Workflows, or Dagster. Gradient was built to work seamlessly with your stack and data tools.

Key
benefits:
Gain total visibility and control over your data infrastructure

Complete visibility

Adaptive data pipelines

Fine-tuned
models
Cost-performance
correlation

Plug-n-play
Integration

I’d be surprised if there was any data team on the planet that wouldn’t save money and time from using Gradient.
Jesse Lancaster, CTO, Forma.ai





How we’re different
Monitor the right metrics, get instant anomaly alerts, and take proactive actions.
Opinionated monitoring
Focus on the right metrics. Gradient only monitors the metrics that have been proven to impact job costs and runtimes.
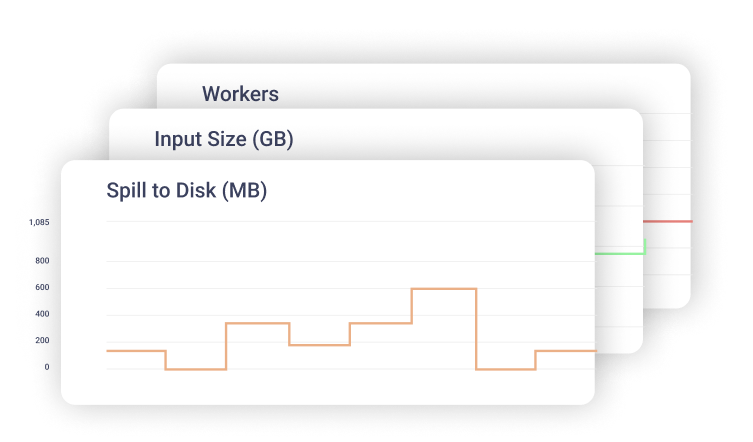
Actionable insights
The insights you need to take action. Get alerted when cost thresholds are breached, data sizes change, or other anomalies.

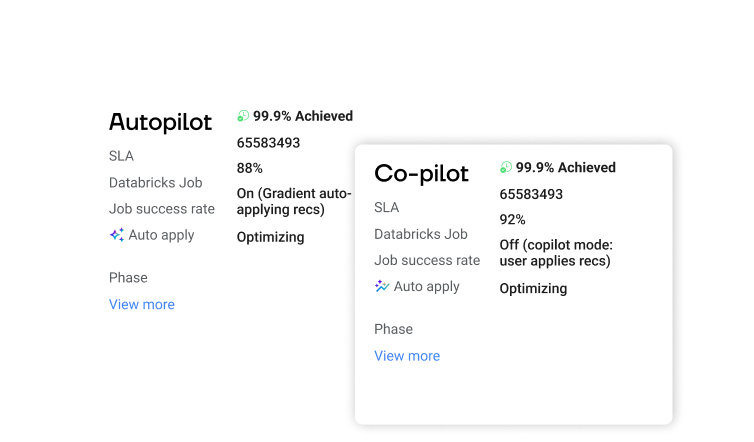
AI optimization engine
Gradient’s ML models are trained on your jobs to offer custom recommendations that can be applied in a click or fully automated.
Explore additional capabilities
Get started today
Save up to 50% on Databricks Jobs compute with actionable insights and AI optimization