How Forma.ai improved their Databricks costs quickly and easily with Gradient


Forma.ai is a B2B SaaS startup based in Toronto, Canada building an AI powered sales compensation system for enterprise. Specifically, they seamlessly unify the design, execution, and orchestration of sales compensation to better mobilize sales teams and optimize go-to-market performance.
Behind the scenes, Forma.ai deploys their pipelines on Databricks to process sales compensation pipelines for their customers. They process hundreds of terabytes of data per month across Databricks Jobs clusters and ad-hoc all-purpose compute clusters.
As their customer count grows, so will their data processing volumes. The cost and performance of their Databricks jobs directly impacts their cost of goods (COGs) and thus their bottom line. As a result, the efficiency of their jobs is of the utmost importance today and for their future sustainable growth.
What is their problem with Databricks?
Forma.ai came to Sync with one fundamental problem – how can they optimize their processing costs with minimal time investment? Thanks to their customer growth, their Databricks usage and costs were only increasing. They were looking for a scalable solution to help keep their clusters optimized without high overhead on the DevOps and Development teams.
Previously they had put some work into trying to optimize their jobs clusters, such as moving to different instance types for the most expensive pipelines. These pipelines and their clusters are updated frequently however, and manually reviewing configuration of every cluster regularly is simply not cost or time effective.
How Gradient Helps
Gradient provided the solution they were looking for – a way to achieve optimal clusters without the need to manually tune – freeing up their engineers to focus on building new features and accelerate development.
Furthermore, the configurations that Gradient does make are fully exposed to their engineers, so their team can actually learn and see what configurations actually matter and what the impact is. Enriching their engineers and leveling up their own Databricks experience.
Initial Results with Gradient
For a first test, Forma onboarded a real job they run in production with Gradient, enabled ‘auto-apply’ and then let Gradient control their cluster for each recurring run. After a couple cycles of learning and optimizing, the first results are shown below: an 18% cost savings and a 19% speedup without lifting a finger.
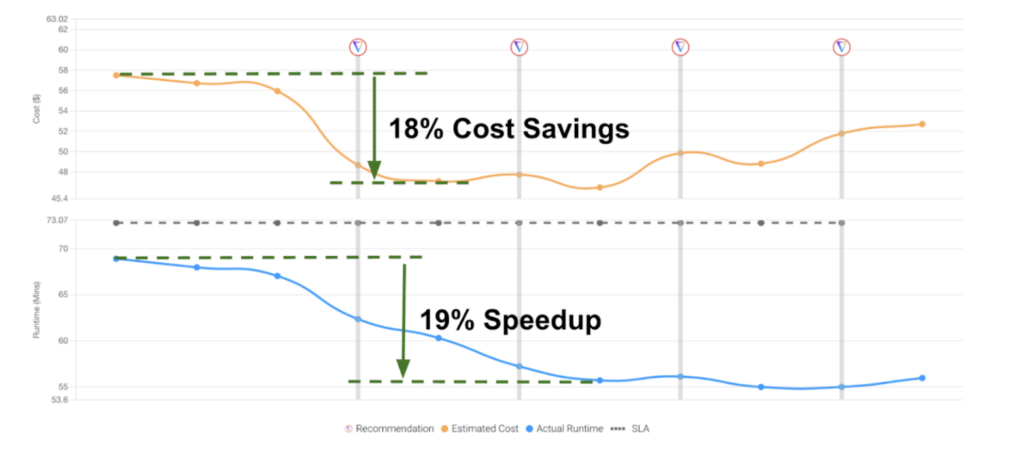
“Cost and cost control of data pipelines is always a factor, and Databricks and cloud providers generally make it really easy to spend money and pretty labor intensive to save money, which can end up meaning you spend more on the time spent optimizing than you end up saving. Gradient solves this dilemma by removing the bulk of the time spent on analysis and inspection. I’d be surprised if there was any data team on the planet that wouldn’t save money and time by using Gradient.”
Jesse Lancaster VP, Data Platform
So what did Gradient do actually?
In this first initial result, the change that had the most impact was tuning the cluster’s EBS settings (AWS only). These settings are often overlooked in favor of CPU and Memory settings.
A table of the specific parameters before and after Gradient is shown below:
| Initial Settings | Optimized Settings | |
| ebs_volume_type | GENERAL_PURPOSE_SSD” | GENERAL_PURPOSE_SSD” |
| ebs_volume_count | 1 | 4 |
| ebs_volume_size | 100 | 32 |
| ebs_volume_iops | <not set> | 3000 |
| ebs_volume_throughput | <not set> | 312 |
The initial settings reflect the typical settings Databricks provides, and is what most people use. The automatic EBS settings depend on the size of the instance chosen, with bigger instances getting more baseline storage according to AWS’s best practices. While these baseline settings are sufficient for running applications, they are often suboptimal.
We can see low level settings like IOPS and throughput are usually not set. In fact, they aren’t even available in the cluster creation Databricks console. You have to adjust these specific settings in the cluster JSON or with the Jobs API.
If you’d like to try out Gradient for your workloads, checkout the resources below:
 Noa Shavit
Noa Shavit