Databricks vs Snowflake: A Complete 2024 Comparison

We provide a high level overview and comparison of Databricks vs Snowflake, as well as our own opinions on their relative strengths and weaknesses.

Databricks and Snowflake are two of the largest names in cloud data solutions – and for good reason. Both platforms have been instrumental in helping companies generate value from their internal (and external) data assets. Each platform has distinct advantages and features and they’ve increasingly overlapped in their offerings—leaving many confused about which solution is best suited for their business needs.
Unfortunately, as is the case in most things in life, there isn’t a simple answer for “which one is better.” But, at Sync, we’ve seen, debugged, and optimized thousands of workloads across numerous enterprises, which has given us a unique perspective.
To begin a meaningful comparison, we have to understand the history and core competency of each offering. To help in that process, we at Sync broke down the major differences between Snowflake and Databricks — including price, performance, integration, security and best use cases—in order to best address the individual needs of each user.
While this topic has been debated plenty of times in the past, here at Sync we aim to provide emphasis on the total cost of ownership and ROI for companies. With all that said, let’s begin!
Below is our complete 2024 guide to all things Databricks vs. Snowflake.
Databricks vs. Snowflake: What Are The Key Differences?
The first thing to understand about the two platforms is what they are, and what solution they are hoping to provide.
Databricks is a cloud-based, unified data analytics platform, for building, deploying, and sharing data analytics solutions at scale. Databricks aims to provide one unified interface where users can store data and execute jobs in interactive, shareable workspaces. These workspaces contain cloud-based notebooks—which are the backbone of Databricks— through which all compute functions are built to be computed by cloud based machines.
Snowflake, on the other hand, is a fully-managed, SaaS cloud-based data warehouse. Whereas Databricks was initially designed to unify data pipelines, Snowflake was designed to be the easiest to manage data warehouse solution on the cloud. While the target market for Databricks is data scientists and data engineers, the target market for Snowflake is typically data analysts—who are highly proficient in SQL queries and data analysis—but not as interested in complex computations or machine learning workflows.
Over time, Databricks and Snowflake have been increasingly in competition, as each hopes to expand their offerings to be an all-in-one cloud data platform solution. New products like Snowflake’s Snowpark (which offers Python functionality) and Databricks’s DBSQL (their serverless data warehouse) have made it increasingly difficult to differentiate the offering of each product.
For the time being, most would agree that Snowflake tends to be the dominant name for easy-to-use cloud data warehouse solutions, and Databricks is the winner for cloud-based machine learning and data science workflows.
Databricks vs Snowflake: Data Storage
At the moment, Snowflake has the edge for querying structured data, and Databricks has the edge for raw and unstructured data needed for ML. In the future, we think Databricks data lakehouse platform could be the catch-all solution for all data management.
One of the largest differences between Snowflake and Databricks is how they store and access data. Both lead the industry in speed and scale. The largest difference between the two is the architecture of data warehouse vs data lakehouse, and the storage of unstructured vs structured data.
Snowflake
Snowflake, at its core, is a cloud data warehouse. It stores structured data in a closed, proprietary format for quick, seamless data querying and transformation. Their proprietary format allows for high speed and reliability with tradeoffs on flexibility. More recently, Snowflake is allowing the ingestion of data and storage of data in additional formats (such as Apache Iceberg), but the vast majority of its’ customer data still sits in their own format.
Snowflake utilizes a multi-cluster shared disk architecture, in which compute resources share the same storage device, but retain their own CPU and memory. To achieve this, Snowflake ingests, optimizes, and compresses data to a cloud object storage layer, like Amazon S3 or Google Cloud Storage. Data here is organized into a columnar format and segmented into micro-partitions, anywhere from 50 to 500MB. These micro-partitions store metadata, which helps dramatically with speed. Interestingly enough – Snowflake’s own internal storage file format is not open source – keeping most customers locked in.
To function efficiently, Snowflake uses multiple layers to provide an enterprise-experience to the cloud processing workload. Snowflake maintains a cloud services layer that handles the enterprise authentication and access control.
For execution, Snowflake uses virtual warehouses, which are abstractions on top of regular cloud instances (such as EC2).These warehouses query data from a separate Data storage layer, effectively separating storage and compute. . This separation of compute and storage makes Snowflake infinitely scalable and allows users to run concurrent queries off the same data, with reasonable isolation.,
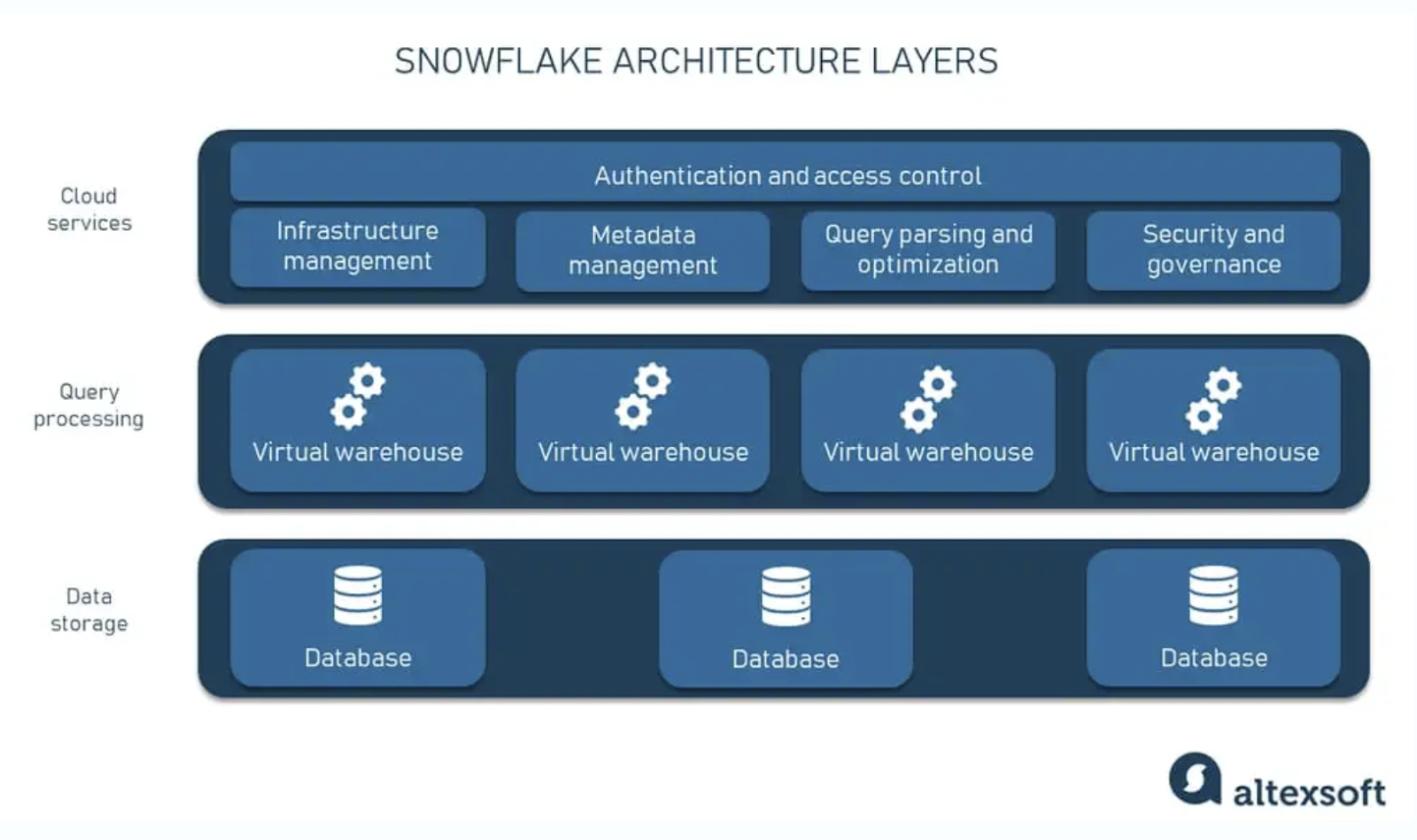
Snowflake and Databricks are cloud agnostic meaning they run all three major cloud service providers, Amazon AWS, Microsoft Azure and Google Cloud Platform (GCP).
Sync’s Take: Snowflake’s architecture allows for fast and reliable querying of structured data, at scale. It has appeal to those who want simple methods for managing their resource requirements of their jobs (through T-Shirt size warehouse options). It is primarily geared towards those proficient in SQL but lacks the flexibility to easily deal with raw, unstructured data.
Databricks
One of Databricks’ selling points is it employs an open-source storage layer known as Delta Lake— which aims to combine the flexibility of cloud data lakes, with the reliability and unified structure of a data warehouse—and without the challenges associated with vendor lock-in. Databricks has pioneered this so-called ‘data lakehouse’ hybrid structure as a cost-effective solution for data scientists, data engineers, and analysts alike to work with the same data—regardless of structure or format.
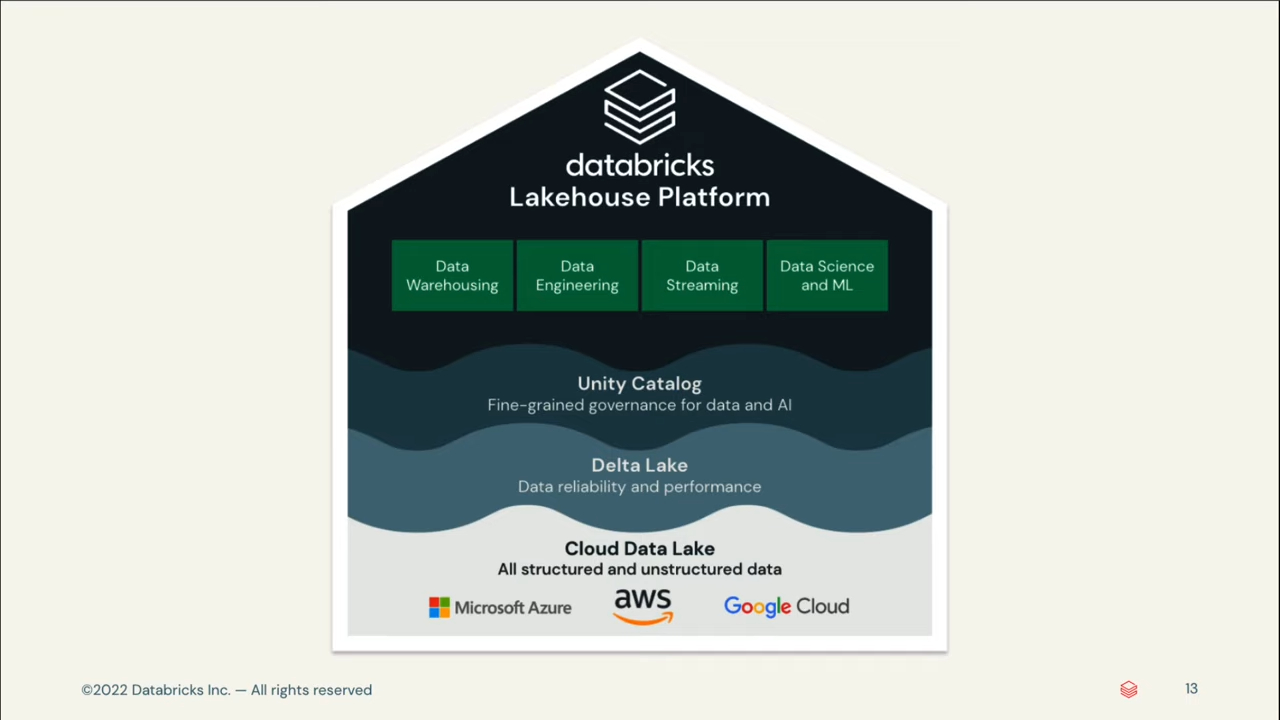
Databricks data lakehouse works by employing three layers to allow for the storage of raw and unstructured data—but also stores metadata (such as a structured schema) for warehouse-like capabilities on structured data. Notably, this data lakehouse provides ACID transaction support, automatic schema enforcement—which validates DataFrame and table compatibility before writes—and end-to-end streaming for real-time data ingestion—some of the most desirable advancements for data lake systems.
Sync’s Take: Lakehouses bring the speed, reliability and fast query performance of data warehouses to the flexibility of a Data Lake. The drawback is that as a relatively new technology, new and less technical users have been occasionally unable to locate tables and have to rebuild them.
Databricks vs Snowflake Scalability
Snowflake and Databricks continue to battle for dominance of enterprise workloads. While both have been proven to be industry leaders in this capacity, the largest practical difference between the two lies in their resource management capabilities.
Snowflake
Snowflake offers compute resources as a serverless offering. Meaning users don’t have to select, install, configure, or manage any software and hardware. Instead, Snowflake uses a series of virtual warehouses—independent compute resources containing memory and CPU—to run queries.. This separation of memory and compute resources allows Snowflake to scale infinitely without slowing down, and multiple users can query concurrently against the same single segment of data.
In terms of performance, Snowflake has been shown to process up to 60 million rows in under 10 seconds.
Snowflake employs a simple “t-shirt” sizing model to their virtual warehouses, with 10 sizes with each double the computing power as the size before it. The largest is 6XL which has 512 virtual nodes. Because warehouses don’t share compute resources or store data, if one goes down it can be replaced in minutes without affecting any of the others.

A diagram of the virtual nodes associated with each size data warehouse
Most notably, Snowflake’s multi-cluster warehouses provide both a “maximized” and “auto-scale” feature which gives you the ability to dynamically shut down unused clusters, saving you money.
Databricks
Databricks started out with much more “open” and traditional infrastructure, where basically all of the compute runs inside a user’s cloud VPC. This is the complete opposite of the “serverless” model where the compute is run inside Databrick’s VPC, since all of the cluster configurations are exposed to end users. This has its pros and cons, the main advantage is that users can hyper optimize their clusters to improve performance, but the drawback is that it can be painful to use or require an expert to maintain.
More recently, Databricks is evolving towards the “serverless” model with Databricks SQL Serverless, and likely extending this model to the other products, such as notebooks. The pros and cons here flip, in that the pro is users don’t have to worry about cluster configurations, however the con is that users have no access nor visibility into the underlying infrastructure and are unable to custom tune clusters to meet their needs.
Since Databricks is currently in a “transition” period between classic and “serverless” offerings, their scalability really depends on which use case people select.
One major note is Databricks has a diverse set of compute use cases, from SQL warehouses, Jobs, All Purpose Compute, Delta Live Tables, to streaming – each one of these has slightly different compute configurations and use cases. For example SQL warehouses can be used as a shared resource, where multiple queries can be submitted to the warehouse at any time from multiple users. Jobs are more singular, in which one notebook is run on one cluster, and is shut down (Jobs can also be shared now, but this is used less).
The different use cases need to fit the end user’s needs, which can also impact scalability. This one example symbolizes both the strength and weakness of Databricks, there are so many options at so many levels it can be great if you know what you’re doing, or it can be a nuisance.
Sync’s Take: When it comes to scaling to large workflows, both Snowflake and Databricks can handle the workload. However, Databricks is better able to boost and fine tune the performance of large volumes of data which ultimately saves costs.
Databricks vs Snowflake: Cost
Both Databricks and Snowflake are marketed as pay-as-you-go models. Meaning the more compute you reserve/request, the more you pay. Their models starkly differ from more traditional “usage based pricing schemes” where customers pay only for the usage they actually consume. In both Databricks and Snowflake, users can and will pay for requested resources whether or not those resources are actually necessary or optimal to run the job.
Another big difference between the two services is that Snowflake runs and charges for the entire compute stack (virtual warehouses and cloud instances), whereas Databricks only runs and charges for the management of compute, requiring users still have to pay a separate cloud provider bill. It is worth noting that Databricks’ new serverless product mimics the Snowflake operating model. Databricks works off a compute/time units called Databricks Units (or DBUs) per second and Snowflake uses a Snowflake credit system.
As a formula, it breaks down like this:
- Databricks (Classic compute) = Data storage + Cost of Databricks Service (DBUs) + Cost of Cloud Compute (Virtual machine instances)
- Snowflake = Data storage (Daily average volume of bytes stored on Snowflake) + Compute (number of virtual warehouses used)
Both Databricks and Snowflake offer tiers and discounts of pricing based on company size, and both allow you to save money by pre-purchasing units or credits.
Databricks has more variance in price as it has different prices depending on the type of workload, with certain types of computes costing 5x more per compute hour than the simple jobs.
One major advantage Databricks has in terms of costs, is it allows users to utilize Spot instances in their cloud provider – which can translate to significant cost savings. Snowflake obfuscates all of this, and the end user has no option to benefit from utilizing Spot instances.
Sync’s Take: There is no concrete answer to which service is “cheaper” as it really depends on how much of the service or platform you’re using, and for what types of tasks. However, the control and introspection capabilities that Databricks provides is fairly unmatched in the Snowflake ecosystem. This gives Databricks a significant edge when optimizing for large compute workloads.
If you’d like a further guide on the breakdown of Databricks pricing, we recommend checking out our complete pricing guide.
Databricks vs Snowflake Speed Benchmarks
Databricks claims they are 2.5x faster than Snowflake. Snowflake also claims they are faster than databricks. While this is a contentious issue between the two giants the reality is benchmarks merely only serve as a vanity metric. In reality, your workloads will likely look nothing like the TPC-DS benchmarks that either company ran, and hence their benchmarks would not apply to your jobs. Our opinion here is that benchmarks don’t matter at this level.
While this may be an unsatisfying answer, if you’re looking for a solution that is all about the absolute fastest way to run your code – there are likely other solutions that are less well known but do focus on performance.
Most companies we speak to value both platforms due to their ease of use, having all of their data in one place, ability to share code, and not having to worry about low level infrastructure. Pure raw speed is rarely a priority for companies. If this sounds like your company, likely the speed metrics don’t really matter so much.
However, cost likely does matter in aggregate, and hence doing an actual comparison of runtime and cost on the different platforms with your actual workloads is the only real way to know.
Databricks vs Snowflake: Ease of Use
All things equal, Snowflake is largely considered the “easier” cloud solution to learn between the two. It has an intuitive SQL interface and as a serverless experience, doesn’t require users to manage any virtual or local hardware resources. Plus as a managed service, using Snowflake doesn’t require any installing, maintaining, updating or fine-tuning of the platform. It’s all handled by Snowflake.
From a language perspective, Snowflake is all SQL-based (excluding their new foray into Snowpark) making it accessible for many business analysts. While Databricks SQL has data warehouse functionality in line with Snowflake, the large use case of Databricks is being able to write in Python, R and Scala and reviews on Gartner and Trust Radius have consistently rated it a more technical setup than Snowflake.
Snowflake also has automated features like auto-scaling and auto-suspend to help start and stop clusters without fine-tuning. While Databricks also has autoscaling and autosuspend, it is designed for a more technical user and there is more involved with fine-tuning your clusters (watch more about how we help do this here).
Sync’s Take: While Databricks UI has a steeper learning curve than Snowflake, it ultimately has more advanced control and customization than Snowflake, making this a tradeoff that is largely dependent on how complex you intend your operations to be.
Databricks vs Snowflake: Security
Both Databricks and Snowflake are GDPR-compliant, offer role-based access control (RBAC), and both organizations encrypt their data both at rest and in motion. Both have very good records with data security and offer a variety of role-based access controls and support for compliance standards.
Databricks offers additional isolation at multiple levels including workspace-level permissions, cluster ACLs, JVM whitelisting, and single-use clusters. For organizations that employ ADS or AMS teams, Databricks provides workload security that includes code repository management, built-in secret management, hardening with security monitoring and vulnerability reports, and the ability to enforce security and validation requirements.
Snowflake allows users to set regions for data storage to comply with regulatory guidelines such as HIPAA and PCI DSS. Snowflake security levels can also be adjusted based on requirements and has built-in features to regulate access levels, and control things like IP allows and blocklists. Snowflake also allows advanced features of Time Travel and Fail-safe which allow you to restore tables, schemas, and databases from a specific time point in the past or protect and recover historical data.
Historically the only issue for Snowflake was the inability to on-premise storage on a private-cloud infrastructure, which is needed for the highest level of security like government data. In 2022, Snowflake started adding in on-premise storage, however as of yet there is limited information on this has been received.
Sync’s Take: Both Databricks and Snowflake have an excellent reputation with data security, as it is mission-critical to their businesses. There is really no wrong choice here and it largely comes down to making sure individual access levels match your intent.
Databricks vs. Snowflake: Ecosystem and Integration
Databricks and Snowflake are becoming the abstractions on top of Cloud Vendors for data computation workloads. As such, they both plug into a variety of vendors, tools, and products.
From the vendor space, both Databricks and Snowflake provide marketplaces that allow other predominant tools and technology to be co-deployed. There are also community built and contributed features, such as the Databricks Airflow Operators / Snowflake Airflow Operators.
On the whole though, the Databrick’s ecosystem is typically more “open” than Snowflake, since Databricks still runs in a user’s cloud VPC. This means, users can still install custom libraries, or even introspect low-level cluster data. Such access is not possible in Snowflake, and hence integrating with your favorite tools may be harder. Databricks also tends to be generally more developer / integration friendly than Snowflake for this exact reason.
Other FAQ on Databricks vs Snowflake?
- Is Databricks a data warehouse? Databricks bills itself as the world’s first “Data Lakehouse”, combining the best of data lakes and data warehouses. However, despite having the capability, Databricks is not typically thought of as a data warehouse solution, as its learning curve and fine-tuning are often unnecessarily for someone seeking a just straightforward data warehouse.
- Can Snowflake and Databricks integrate with each other? It is possible and not entirely uncommon to integrate Databricks and Snowflake with each other. Typically in this manner, Databricks acts as a Data Lake for all unstructured data, manipulating it and processing it as part of an ETL pipeline where it is then stored on Snowflake like a traditional data warehouse.
- What data types does Snowflake accept? Snowflake is optimized for structured and semi-structured data, meaning it can only accept certain data formats, notably JSON, Avro, Parquet and XML.
- Can Snowflake and Databricks create dashboards for business intelligence? Yes, both Snowflake and Databricks are able to create dashboards and visualizations for business intelligence.
Databricks vs Snowflake: Which Is Better?
Both Databricks and Snowflake have a stellar reputation within the business and data community. While both cloud-based platforms, Snowflake is most optimized for data warehousing, data manipulation and querying, while Databricks is optimized for machine learning and heavy data science.
Broken down into components, here are a list of pros for each:
| Platform/Feature | Databricks | Snowflake |
| Storage | Better for raw, unstructured data. | Better for reliability and ease of use for structured data |
| Use Case | Better for ML, AI, Data Science and Data Engineering. Collaborative notebooks in Python/Scala/R a big plus | Easier for analysts in business intelligence and companies looking to migrate existing data warehouse system |
| Price | Cheaper at high compute volumes. Not as predictable on cost. | Efficient at scaling down unused resources. More consistent, predictable costs. |
| Scalability | Infinitely scalable. Effective at high volume workloads. | Separate storage and compute makes for seamless concurrent queries. |
| Security | GDPR-compliant, role-based access control, encrypted at rest and and in motion | GDPR-compliant, role-based access control, encrypted at rest and in motion |
If you want to integrate structured data an existing ETL pipeline using structured data and programs like Tableau, Looker and Power BI, Snowflake could be the right option for you. If you instead are looking for a unified analytics workspace where you build compute pipelines, Databricks might be the right choice for you.
Interested in using Databricks further? Check out Sync’s Gradient solution – the only ML-powered Databricks cluster optimization and management tool. At a high level, we help maintain the openness of Databricks but now with the “ease” of Snowflake. On top of that, we also actively drive your costs lower and lower.
 Noa Shavit
Noa Shavit