
Save up to 50% on compute!
Save on compute while meeting runtime SLAs with Gradient’s AI compute optimization solution.

Databricks is a popular unified analytics platform and a go-to solution for many organizations looking to harness the power of big data. Its collaborative workspaces have become the industry standard for data engineering and data science teams and an ideal environment for building, training and deploying machine learning and AI models at scale.
However—as with any cloud-based service— Databricks pricing structure is extremely complex and product dependent – understanding it is crucial for budgeting and cost management. In this article, we’ll explain in simple terms everything having to do with Databricks pricing, including its pay-as-you-go model, what factors affect your individual pricing, and examples of how to save on cost.
The short answer is that it depends. As we’ll explain below Databrick’s price depends on usage so there is no single answer to what it costs. However, based on the average data use of a medium-sized company, it’s fairly normal to see an expenditure of a midsize company to be somewhere between $100k to $1 million per year.
In simple terms, Databricks cost is based on how much data you process, and the type of workload you’re executing and which product you’re using. Each type of compute has a different price per processing unit—known as Databricks unit, or DBU. To calculate your Databricks cost, you simply multiply the number of DBUs used by the dollar rate per DBU for that workload.
For instance, certain jobs such as Jobs Light Compute or Serverless Real-Time cost $0.07 per DBU. So if you use a job that requires 100 DBU it would cost $7.00.
Keep in mind complex tasks such as All-Purpose Interactive workloads (typically used for data science or business intelligence) have higher costs of around $0.55 per DBU. This means that it’s not just the amount of data, but also the workload type. Data velocity (the frequency your data pipeline is used) and data complexity (how much work it takes to process your data set) can all add to the amount of DBUs needed, and thus raise the cost of your workload. It’s thus crucial to evaluate your ETL workflow before and during your Databricks subscription to understand if there are areas for optimization.
Outside of the job function itself, prices for your Databricks subscriptions differ by cloud service provider, your pricing plan, and even your region (though within the contiguous U.S these prices are largely the same). Databricks price can also differ by size and type of instance, which refers to the type of virtual machine you are running on the Databricks lakehouse.
In addition to Databricks costs, there can also be the cloud compute costs. For example, if you run a job on a cluster, you have to pay for both the Databricks overhead as well as the cloud compute costs. Typically the cloud compute costs can be larger than your Databricks cost, so keep this in mind. As a result, the total cost of Databricks is a sum of two major components:
Total Cost of Ownership = Databricks Cost + Cloud Provider Cost
What is interesting, is both the Databricks and cloud costs scale with the cluster size. While that does make sense from the cloud provider’s perspective, since they are providing the compute — one may ask:
Why do Databricks costs scale with cluster size when they don’t run my cluster?
In reality, Databricks is a software layer on top of your cloud provider. Whether you run a 1 node cluster, or a 1000 node cluster, the actual costs to Databricks is fixed. While this doesn’t make any sense, that’s the reality of Databricks pricing.
At the moment there are three different types of pricing plans: Standard Plans, Premium Plans, and Enterprise Plans. These plans differ in their features and types of workloads available, with Premium plan costing the same or more than Standard plan.
Much of the premium plan’s benefit is for role-based access control (think assigning admins with more capabilities and permissions than users), and for higher levels of automation and authentication. There is also access to features like Audit Logs, Credential Pass Through (for Azure Databricks), and IP access list. Enterprise plans are customized per user so vary based on company size, contract size, and duration of the plan.
For a full list of differences between standard and premium pricing, check out our Databricks instance types pricing page.
Below you will see a breakdown of Databricks cost by workload for the standard plan, using AWS as Cloud Service Provider and in the Central US region.
Jobs Compute
Delta Live Tables
All Purpose Compute:
The following workloads are only available for premium subscriptions, and so their prices reflect as such.
Serverless and SQL Compute:
Yes, Databricks does offer free trials, with a free version with fully usable user-interactive notebooks available for 14 days. While the Databricks trial itself is free, you still need to pay for the underlying cloud infrastructure.
If you want to continue to use Databricks for free (but with limited features) you can use the open-source Databricks Community Edition. This is great for those wanting to learn Apache Spark.
However, it’s also important to note that because there are no upfront costs and Databricks is priced on a pay-as-you-go model, the cost itself to get set up is very minimal.
Save on compute while meeting runtime SLAs with Gradient’s AI compute optimization solution.
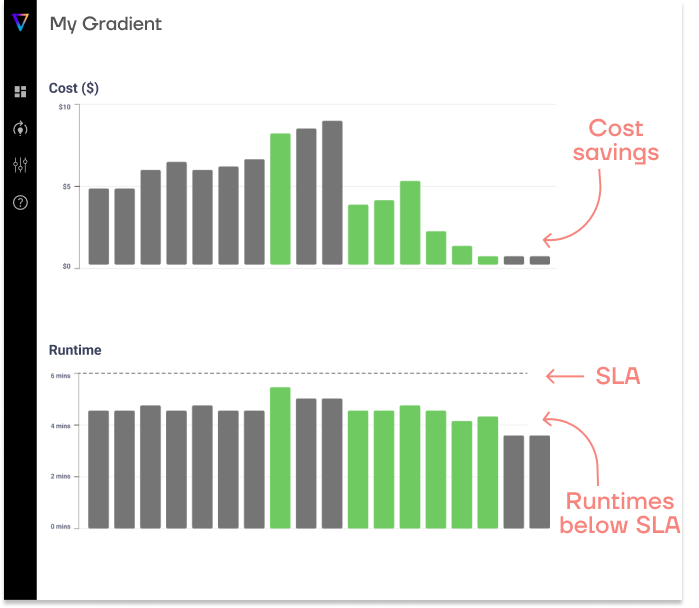
The great news about the Databricks pricing model is that because it’s based on usage, there are a number of ways to reduce your cost basis by altering your usage. Some of these ways include:
Save on compute while meeting runtime SLAs with Gradient’s AI compute optimization solution.
Finding the total cost of your databricks usage can be tricky. Because pricing is based on both the Databricks and Cloud provider fees, it’s difficult to collect and attribute all of the costs. There are several methods you can use depending on what you can access at your company:
1. First Find DBUs
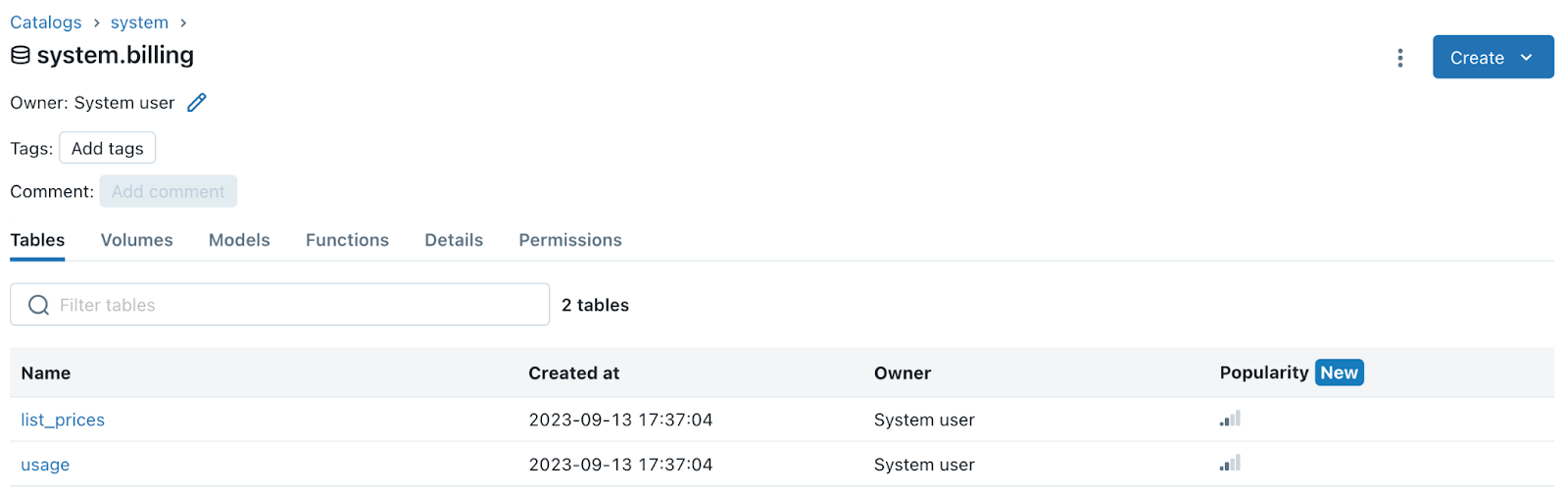
You’ll always want to first asses the direct cost of your Databricks usage. To do this you can go to your admin page, and look at your data usage to isolate just your DBU costs. You can also go the new “system tables” under Databricks which will breakdown the DBU costs only for your jobs.
2. Find Cloud Provider Costs
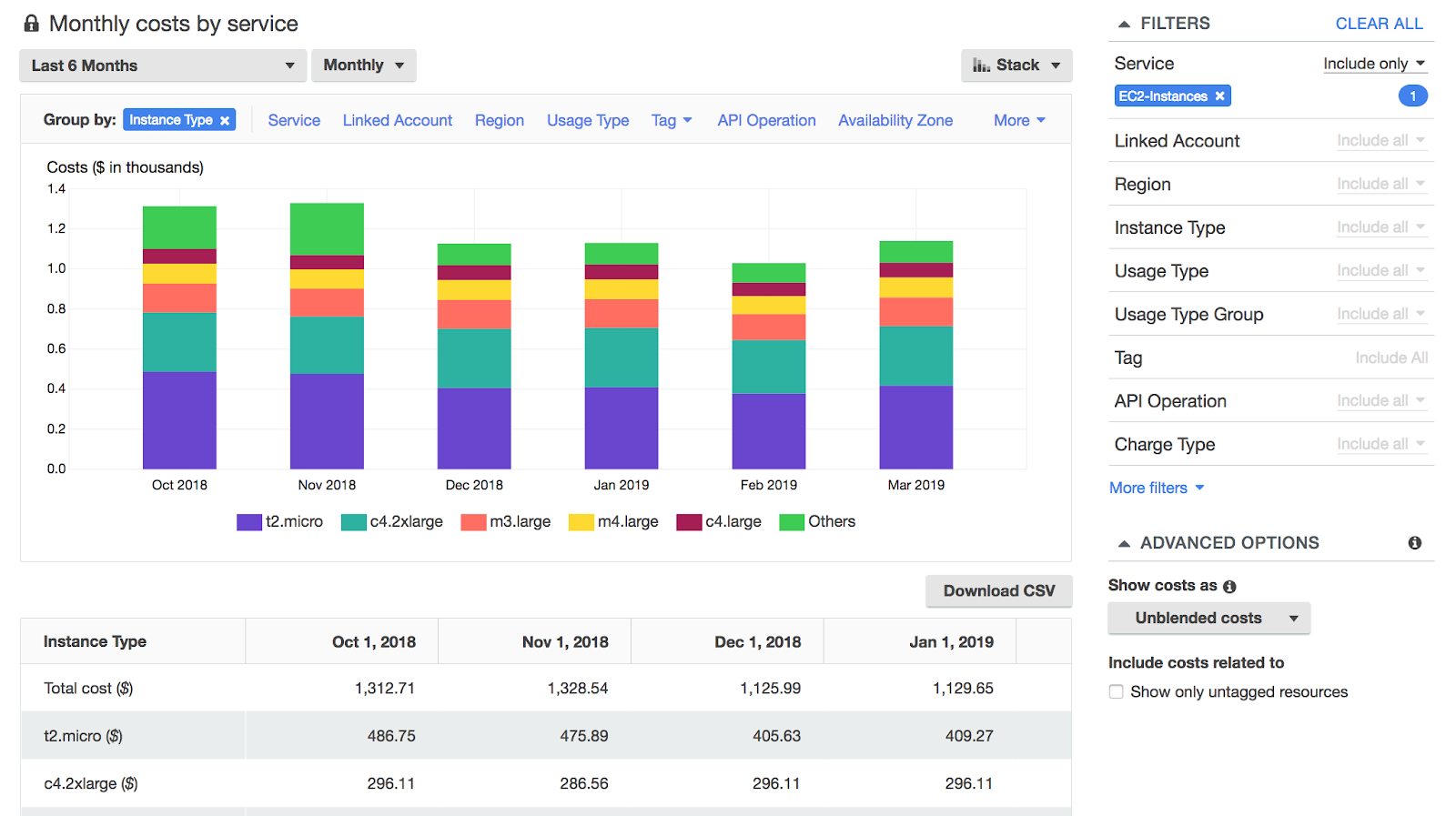
The good news about Cloud provider costs is that they should remain fairly static relative to Databricks costs. To find your Cloud Provider cost, you should be able to use the tags employed inside your Databricks clusters to find associated costs within your Cloud Provider account. For example, example in AWS, you can use costs explorer to find the cluster and tags associated with your bill.
One thing to note is that it can take from several hours to a day to wait for the billing information to be placed in both Databricks or your cloud providers endpoints. This means you have to match costs to workflows from given days, and you can’t get real time results on costs.
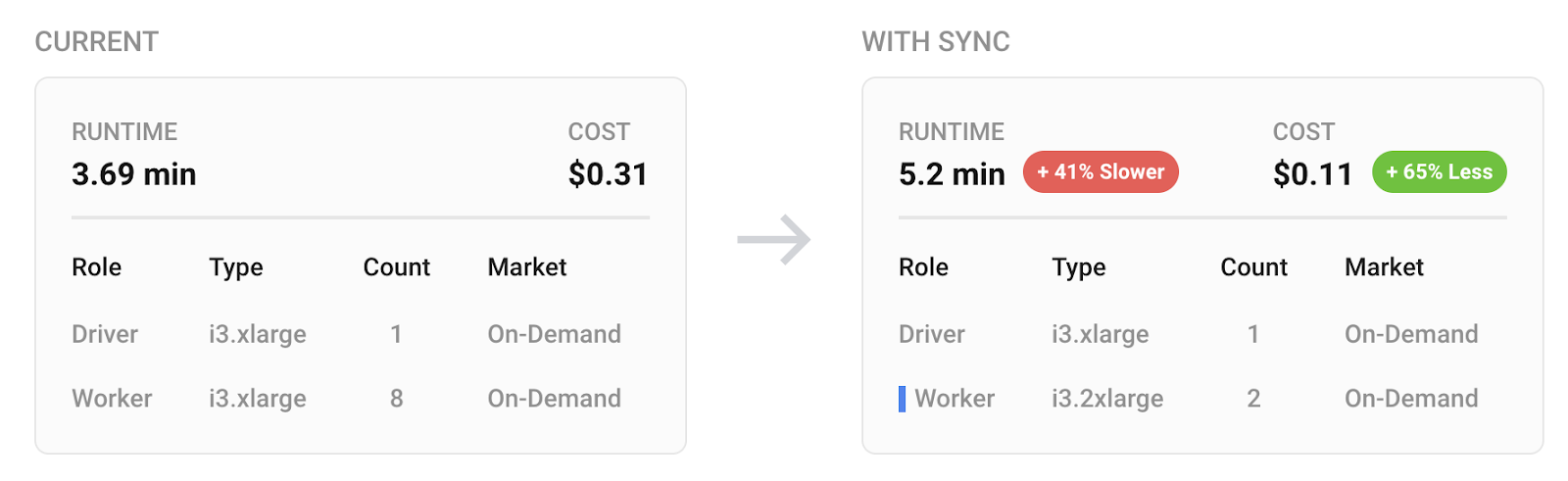
Due to the complexities of extracting the actual cost of each workload, we put together our Gradient product to estimate the total cost (DBUs + cloud costs) of each of your jobs. These costs are estimated based on the Spark eventlog and the cluster metrics from your cloud provider.
In the image below from Gradient, we can see the runtime and the estimated total cost of the job before and after a sync recommendation. These cost values are provided instantly after each job run. Of course they are only estimates and baked on list-pricing – but it will give you a good idea of cost trends.
Apart from workspace and compute costs, there are other factors to consider:
While Databricks is a fairly unique product, the most common alternative companies consider is Snowflake. While both are cloud-based data solutions, Databricks is much more common for large-scale machine learning and data science jobs, whereas Snowflake is optimized for low-to-moderate SQL-based queries. Snowflake is typically easier to use, however, users have much less fine grain control of their infrastructure. Read more in our guide on Snowflake vs. Databricks.
While both have a usage-based charge Snowflake charges clients directly for everything – from compute to storage. Databricks on the other hand has 2 cost drivers, Databricks fees in addition to Cloud compute / storage fees.
At the end of the day, there’s no real way to predict if either platform will be cheaper. It all depends on how you use it and what kind of workloads you’re running. One comment we can say is, you’ll only get as much efficiency as effort you put in – as both platforms require optimizations.
For more in-depth information read Databricks guide on evaluating data pipelines for cost performance.
How To Optimize Databricks Clusters
Databricks Instructor-Led Courses
Migrate Your Data Warehouse to Databricks
Save on compute while meeting runtime SLAs with Gradient’s AI compute optimization solution.
 Kartik Nagappa
Kartik Nagappa
 Noa Shavit
Noa Shavit