What is Databricks Unity Catalog (and Should I Be Using It)?

Since launching in 2013, Databricks has continuously evolved its product offerings from machine learning pipeline to end-to-end data warehousing and data intelligence platform.
While we at Sync are big fans of all things Databricks (particularly how to optimize cost and speed) we often get questions about understanding Databricks new offerings—particularly as product development has accelerated in the last 2 years.
To help in your understanding, we wrote this blog post to address the question, “What is Databricks Unity Catalog?” and whether users should be using it (the answer is yes). We walk through a precise technical answer, and then dive into the details of the catalog itself, how to enable it and frequently asked questions.
What Is the Unity Catalog in Databricks?
The Databrick’s Unity Catalog is a centralized data governance layer that allows for granular security control and managing data and metadata assets in a unified system within Databricks. Additionally, the unity catalog provides tools for access control, audits, logs and lineage.
You can think of the unity catalog as an update designed to bridge gaps in the Databrick ecosystem—specifically to eliminate and improve upon third-party catalogs and governance tools. With many cloud-specific tools being used, Databricks brought in a unified solution for data discovery and governance that would seamlessly integrate with their Lakehouse architecture. Thus, while Unity Catalog was initially billed as a governance tool, in reality it streamlines processes across the board. While simplistic, it’s not wrong to say Unity Catalog simply makes everything Databricks run smoother.
Notably, the Unity Catalog is being offered by default on the Databricks Data Intelligence Platform. This is because Databricks believes the Unity Catalog is a huge benefit to their users (and we are inclined to agree!). If you have access to the Unity Catalog, we highly recommend enabling it in your workspace.
What benefits does the Databricks Unity Catalog have to offer?
The Unity Catalog benefits can be thought of in four buckets: data governance, data discovery, data lineage, and data sharing and access.
Data Discovery
The unity catalog provides a structured way to tag, document and manage data assets and metadata. This allows for a comprehensive search interface that utilizes lineage metadata (including full lineage) history and ensures security based on user permissions.
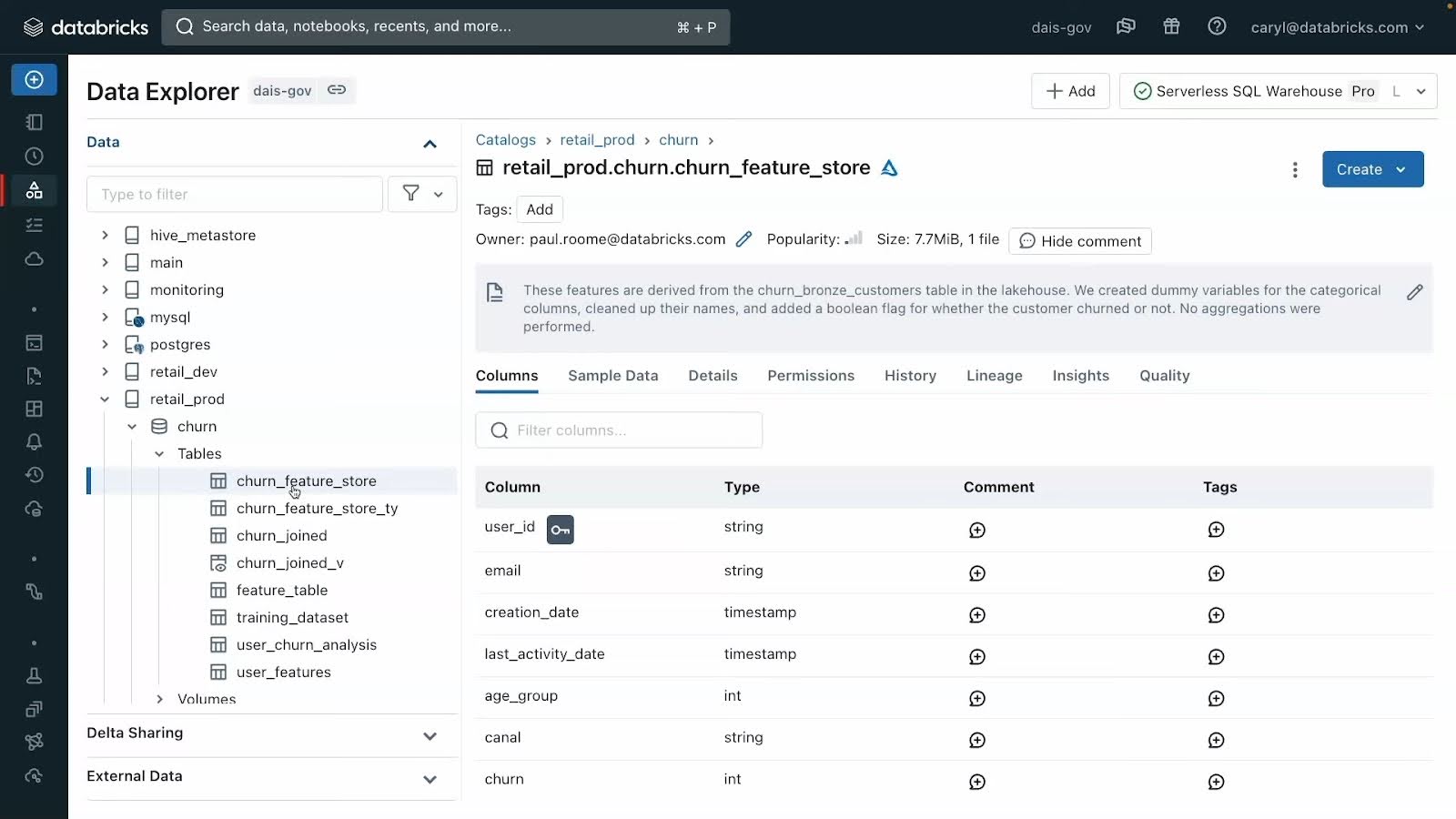
Users can either explore data objects through the Catalog Explorer, or parse through data using SQL or Python to query datasets and create dashboard from available data objects. In Catalog explorer, users can preview sample data, read comments and check field details (50 second preview from Databricks here).
A preview of the Catalog explorer for data discovery in Unity Catalog (via Databricks/Youtube)
Data Governance
Unity Catalog is a layer over all external compute platforms and acts as a central repository for all structured and unstructured data assets (such as files, dashboards, tables, views, volumes, etc). This unified architecture allows for a governance model that includes controls, lineage, discovery, monitoring, auditing, and sharing.

Unity Catalog thus offers a single place to administer data access policies that apply across all workspaces. This allows you to simplify access management with a unified interface to define access policies on data and AI assets and consistently apply and audit these policies on any cloud or data platform.
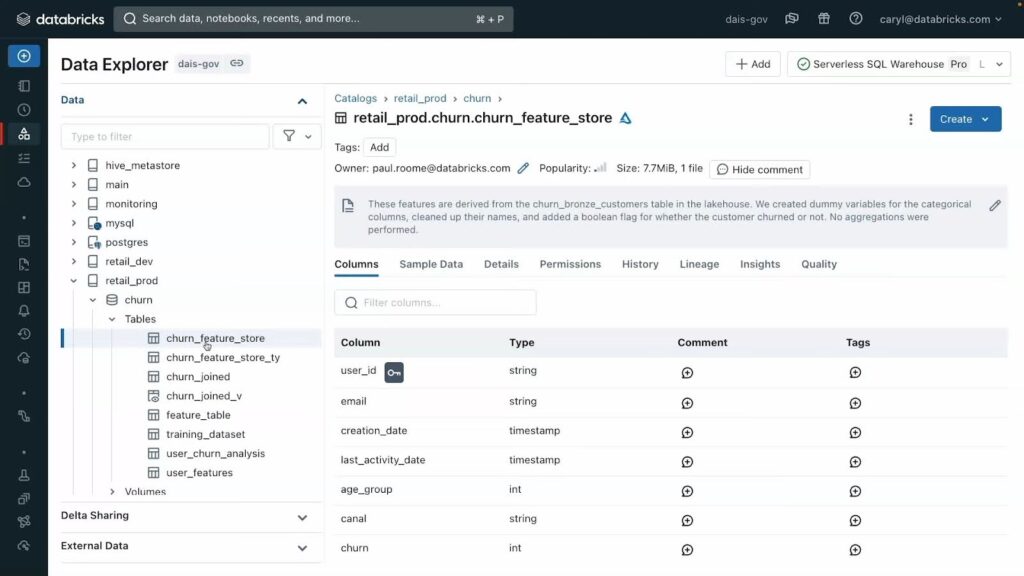
All of Databricks governance parameters can be accessed via their Unity Catalog Governance Portal. The Databricks Data Intelligence Platform leverages AI to best understand the context of tables and columns, the volume of which can be impossible for manual categorization. This also enables you to quickly assess how many of your tables are monitored via Lakehouse Monitoring — Databricks’s new “AI for Governance tool”.
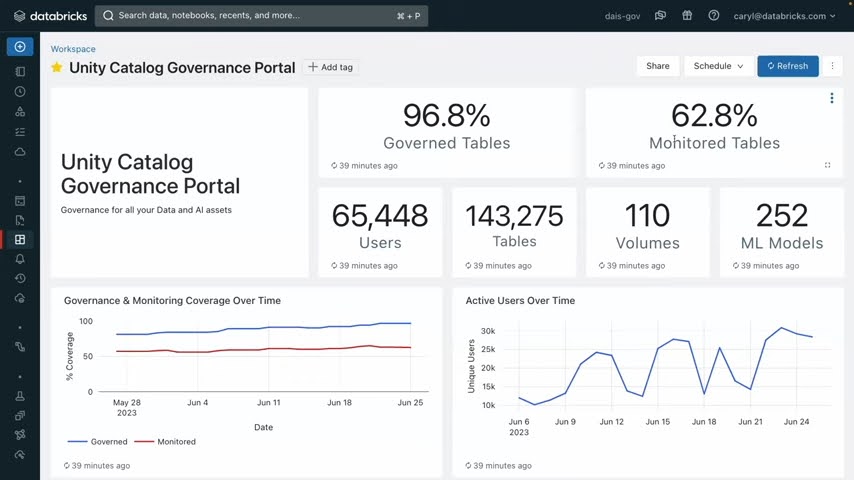
A screenshot of the Unity Catalog Governance portal shows how their Lakehouse Monitoring uses AI to automatically monitor tables and alert users to uses like PII leakage or data drift (via Databricks/Youtube)
With Lakehouse monitoring you can also set up alerts that automatically detect and correct PII leakage, data quality, data drift and more. These auto alerts are contained within their own section of the Governance Portal, which shows when the issue was first detected, and where the issue first stemmed from.
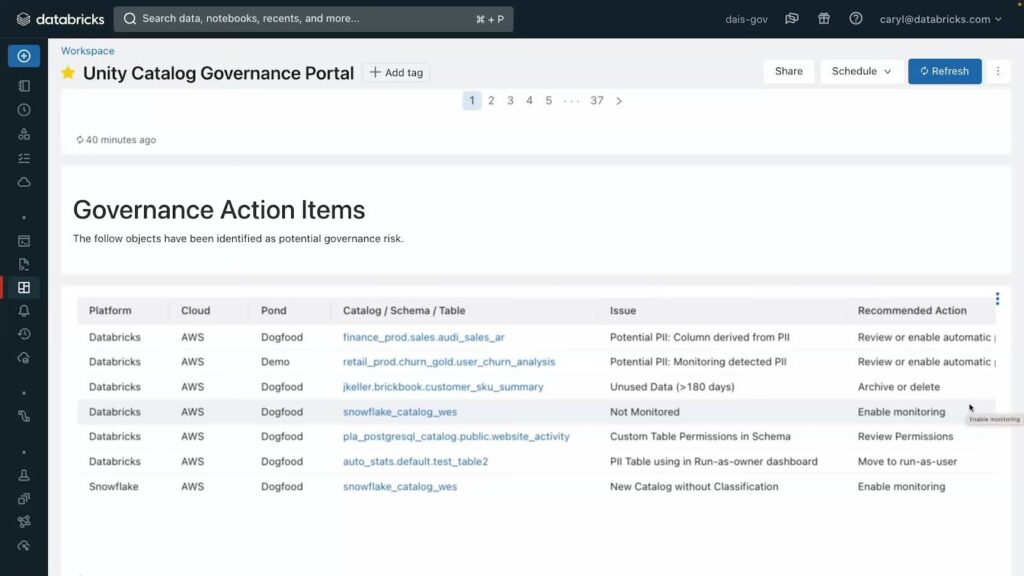
A preview of the governance action items shows how issues are identified by cause and Catalog/Schema/Table. Digging further in will reveal the time and date of first incidence as well as it where it stems from.
It incorporates a data governance framework and maintains an extensive audit log of actions performed on data stored within a Databricks account.
Data Lineage
As the importance of Data Lineage has grown, Databricks has responded with end-to-end lineages for all workloads. Lineage data includes notebooks, workflows and dashboards and is captured down to the column level. Unity Catalog users can parse and extract lineage metadata from queries and external tools using SQL or any other language enabled in their workspace, such as Python. Lineage can be visualized in the Catalog Explorer in near-real-time and
Unity Catalog’s lineage feature provides a comprehensive view of both upstream and downstream dependencies, including the data type of each field. Users can easily follow the data flow through different stages, gaining insights into the relationships between field and tables.
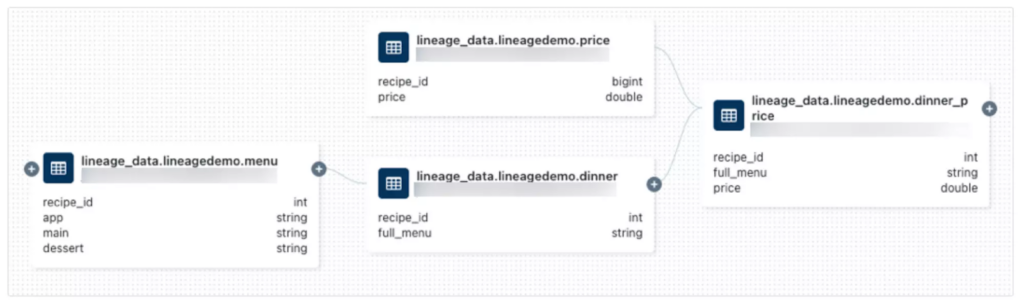
An example of the metadata lineage within Unity Catalog
Like their governance model, Databricks restricts access to data lineage based on the logged-in users’ privileges.
Data Sharing and Access
One of the most welcomed features of Databricks Unity Catalog is its built-in sharing method which is built on Delta Sharing, Databricks’ popular cloud-platform-agnostic open protocol for sharing data and managing permissions launched in 2021.

Within Unity Catalog you can access control mechanisms use identity federation, allowing Databricks users to be service principals, individual users, or groups. In addition, SQL-based syntax or the Databricks UI can be used to manage and control access, based on tables, rows, and columns, with the attribute level controls coming soon.
How Does Databricks Unity Catalog Enhance Data Governance and Security
Databricks has a standards-complaint security model based on ANSI SQL and allows administrators to grant permissions in their existing data lake using familiar syntax, at the level of catalogs, databases (also called schemas), tables, and views.
Unity Catalog grants user-level permissions for Governance Portal, Catalog Explorer and for data lineages and sharing. Unity Catalog in effect has one model for safeguarding appropriating access across your full data estate with permissions, row level, and column level security.
It almost allows registering and governing access to external data sources, such as cloud object storage, databases, and data lakes, through external locations and Lakehouse Federation.
Does Unity Catalog Help With Databricks Cost?
Yes, because Unity Catalog reduces both storage costs and fees for external licensing, it reduces cost compared to previous solutions. It also indirectly saves time by greatly reducing bottlenecks for ingesting data, reducing time spent on repetitive tasks by an average of 80% (according to Databricks). This all comes free and automatically enabled for all new users of the Databricks Data Intelligence Platform.
How do I set up and configure Unity Catalog in Databricks?
The following is a step-by-step guide to setting up and configuring Databricks Unity Catalog.
- Confirm Your Workspace Is Enabled For Unity Catalog.
Log into your account and click Workspaces. From there check the Metastore Column. If a metastore name is preset, it means your workspace is attached to a Unity Catalog.
If your workspace doesn’t return a metastore, you’ll want to either to enable and attach your workspace, or create a Unity Catalog metastore.
- Add users and assign the workspace admin role.
The user who creates a workspace is automatically added as an admin role. That admin can then add and invite users, and can assign workplace admin roles and metastore admin roles. - Create Clusters or SQL Warehouses for users to run queries and create objects. To run Unity Catalog workloads, compute resources must comply with certain security requirements. As a workspace admin, you can opt to make compute creation restricted to admins or let users create their own SQL warehouses and clusters
- Grant Privileges to Users. To create objects and access them in Unity Catalog catalogs and schemas, a user must have permission to do so. See how to grant privileges and manage admin privileges.
- Create New Catalogs and Schemas. To start using Unity Catalog, you must have at least one catalog defined. Catalogs are the primary unit of data isolation and organization in Unity Catalog. All schemas and tables live in catalogs, as do volumes, views, and models. You’ll want to create managed storage for the new catalog, then bind the new catalog your workspace, and then grant privileges for that catalog. Full instructions here.
What Integrations Work With Data Unity Catalog?
Unity Catalog works existing data storage systems and governance solutions such as Atlan, Fivetran, dbt or Azure data factory. It also integrates with business intelligence solutions such as Tableau, PowerBi and Qlik. This makes it simple to leverage your existing infrastructure for updated governance model, without incurring expensive migration costs (for a full list of integrations check out Databricks page here).
What if my workspace wasn’t enabled for Unity Catalog automatically?
If your workspace was not enabled for Unity Catalog automatically, an account admin or metastore admin must manually attach the workspace to a Unity Catalog metastore in the same region. If no Unity Catalog metastore exists in the region, an account admin must create one. For instructions, see Create a Unity Catalog metastore.
Unity Catalog Limitations
The following limitations apply for all object names in Unity Catalog:
- Object names cannot exceed 255 characters.
- The following special characters are not allowed:
- Period (.)
- Space ( )
- Forward slash (/)
- All ASCII control characters (00-1F hex)
- The DELETE character (7F hex)
- Unity Catalog stores all object names as lowercase.
- When referencing UC names in SQL, you must use backticks to escape names that contain special characters such as hyphens (-).
For a full list of Unity Catalog Limitations, read the full documentation for the Unity Catalog.
Unity Catalog FAQs
- How does Databricks Unity Catalog differ from Hive Metastore?
Databricks Unity Catalog offers a centralized data governance model, supports external data access, data isolation, and advanced features like column-level security, while Hive Metastore has limited governance capabilities. - How Long is Lineage Data Stored in Databricks Unity Catalog?
Lineage data on Databricks Unity Catalog is retained for 1 year. - What are the supported compute and cluster access modes for Databricks Unity Catalog?
Supported access modes are Shared Access Mode and Single User Access Mode. No-Isolation Shared Mode is not supported. - What data file formats are supported for managed and external tables in Databricks Unity Catalog?
Managed tables must use the Delta table format, while external tables can use Delta, CSV, JSON, Avro, Parquet, ORC, and Text formats. - How do you enable your workspace for Databricks Unity Catalog?
You can enable Unity Catalog during workspace creation or assign an existing metastore to your workspace through the Databricks account console. - How do you control access to data and objects in Databricks Unity Catalog?
You can use admin privileges, object ownership, privilege inheritance, basic object privileges (GRANT/REVOKE), dynamic views for row/column security, and manage external locations and credentials. - What is the Databricks Unity Catalog object model?
The object model follows a hierarchical structure: Metastore ► Catalog ► Schema ► Tables, Views, Volumes, and Models. - Can you transfer ownership of objects in Unity Catalog?
Yes, you can transfer ownership of catalogs, schemas, tables, and views to other users or groups using SQL commands or the Catalog Explorer UI. - How do you create a new catalog in Unity Catalog?
You can use the CREATE CATALOG SQL command, specifying a name and managed location if needed. You must have CREATE CATALOG privileges on the metastore. - How do you grant permissions on a catalog or schema?
Use the GRANT statement with the desired privileges (e.g., CREATE SCHEMA, CREATE TABLE) and the catalog or schema name, followed by the user or group to grant access to. - What is the syntax for referring to a table in Unity Catalog?
Use the three-part naming convention: <catalog>.<schema>.<table> - How do you create a managed table in Unity Catalog?
Use the CREATE TABLE statement, specifying the table name, columns, and partitioning if needed. Managed tables are created in the managed storage location. - Can you access data in the Hive Metastore through Unity Catalog?
Yes, data in the Hive Metastore becomes a catalog called hive_metastore, and you can access tables using the hive_metastore.<schema>.<table> syntax. - How do you drop a table in Databricks Unity Catalog?
You can use the DROP TABLE statement followed by the fully qualified table name (e.g., DROP TABLE <catalog>.<schema>.<table>).
Unity Catalog is the solution to a problem was created as Databricks grew beyond its initial usage. In order to streamline the various product offerings within their ecosystem, Databricks introduced the Unity Catalog to eliminate third-party integrations, particularly in the realm of data governance. We feel this has been tremendously well executed and as Unity Catalog comes free and installed by default for all new databricks data intelligence platform users, we feel it’s highly advantageous to maximize its utility, particularly for data governance, lineage and data discovery.
 Noa Shavit
Noa Shavit