Configuring Databricks clusters can seem more like art than science. We’ve reported in the past about ways to optimize worker and driver nodes, and how the proper selection of instances impacts a job’s cost and performance. We’ve also discussed how autoscaling performs, and how it’s not always the most efficient choice for static jobs.
In this blog post, we look across a few other popular questions and options we see from folks:
- How do Graviton instances impact cost and performance?
- How does the price and performance of Photon compare to standard instances?
What are Graviton instances?
Graviton instances on AWS contain custom AWS built processors, which promise to be a “major leap” in performance. Specifically for Spark, AWS published a report that claimed Graviton can help reduce costs up to 30% and speed up performance up to 15% for Apache Spark on EMR. Although Databricks clusters can use Graviton, there haven’t been any performance metrics reported (that we know of). There’s no extra surcharge for Graviton instances, and they are typically moderately priced compared to other instances.
What is Photon in Databricks?
Photon is a vectorized query engine written in C++ developed by the creators of Apache Spark and is available within the Databricks platform. Photon is an amazing technical feat with a multitude of features and considerations, that extend well beyond the scope of this blog to go into. For full details, we encourage readers to check out the original Photon academic paper here. Unfortunately, Photon is not free and is typically a 2x cost increase for DBUs compared to non-photon. So users have to decide if the cost increase is “worth it.”
At the highest level for most end users, as cited by the original academic paper::
- Photon is great for CPU heavy operations such as joins, aggregations, and SQL expression evaluations.
- The academic paper claims about a 3x speedup on the TPC-H benchmark compared to standard Databricks runtime
- Photon is not expected to provide a speedup to workloads that are I/O or network bound.
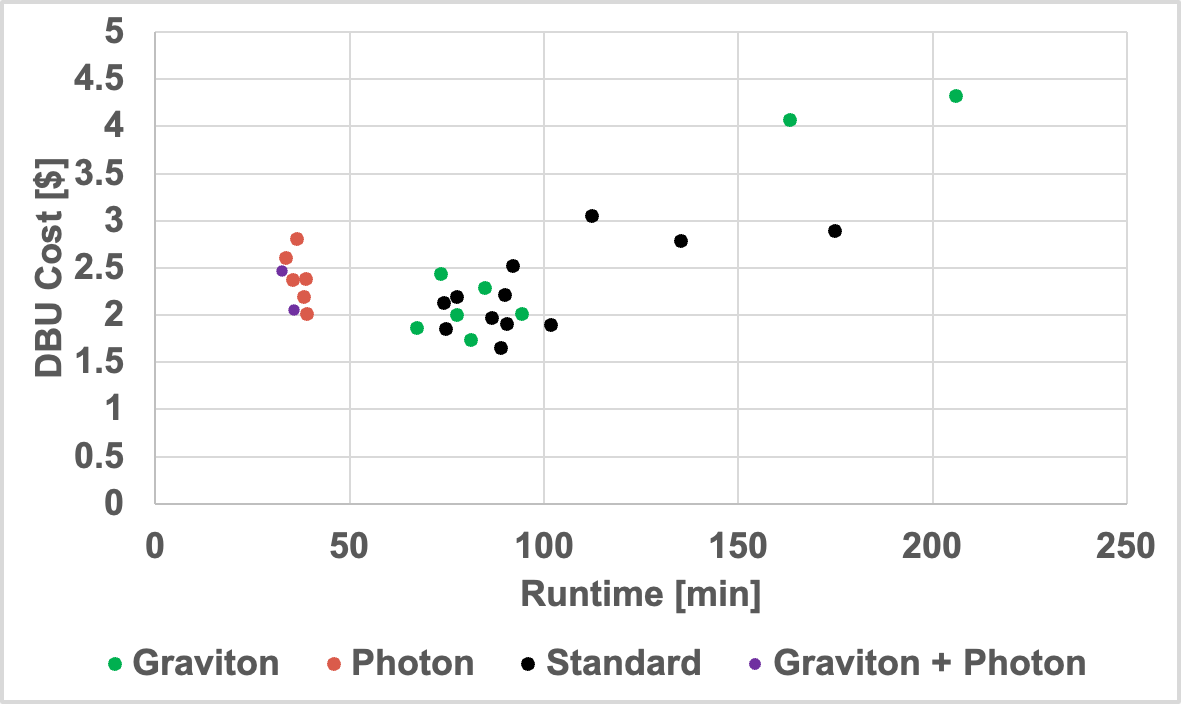
Yes, you can even run Photon on Graviton instances! What happens with this powerful combo? The data below shows the results.
How do I use Graviton and/or Photon?
Graviton instances typically have the “g” letter in the instance names, such as “m6g.xlarge” or “c7g.xlarge” and are selected during the cluster creation step within Databricks under “Worker type” and “Driver type”.
Photon is enabled by simply checking the box “Use Photon Acceleration” in the cluster creation step. An image of the UI is shown below.

Experimental setup
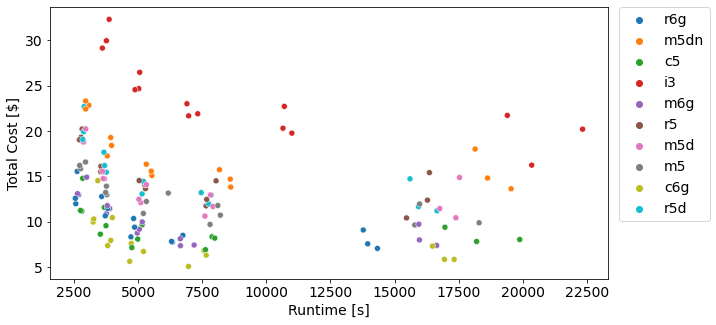
In our analysis we utilize the TPC-DS 1TB benchmark, with all queries run sequentially. We then look at the total runtime of all queries summed together. To keep things simple and fair, every cluster has identical driver and worker instances. We sampled 28 different instances spanning from photon enabled, Graviton, memory, compute, I/O, network, and storage optimized instances. A full list of the parameters of each cluster are below:
- Driver: [instance].xlarge
- Worker: [instance].xlarge
- Number of workers: 10
- EBS volume: 64
- Databricks runtime version: 11.3.x-scala2.12
- Market: On-demand
- Cloud provider: AWS
- Instances: 28 different instances on AWS
For the cost, we utilize only the DBU cost of each cluster. We did not include the AWS costs for various reasons:
- Cloud cost attribution difficulty: Databricks internally re-uses clusters of adjacent jobs. Meaning, AWS clusters for one job may be reused for a second job, if they require the same machine. This causes identifying which job was using which cluster in AWS difficult to determine. This is a niche problem, and only for people who want to determine the true cost of a single job
- AWS costs depend on the market: The AWS costs, or cloud costs in general, depend on the market. Specifically, if users are using on-demand vs. spot nodes, it will drastically change the relative cost performance. Furthermore, spot prices can fluctuate daily, so extracting fair comparisons would be difficult here.
- AWS costs depend on contracts: Large companies negotiate their own costs for their instances, thus again, making an overall apples to apples comparison difficult.
For the reasons above, the DBU costs are utilized because they are exact, easy to identify, and do not fluctuate depending on the market. However, we will say that DBU costs can also depend on contracts. But for the sake of this study, we’ll just use the list prices of DBUs. As you can tell by these thoughts, doing actual cost comparisons is not a trivial task, and is highly dependent on each company’s use case.
Results
The graph below shows the cost vs runtime plots of all 28 different clusters. They are grouped into 3 sections, “Graviton” instances, “Photon” enabled instances, “Standard” instances (no photon, no Graviton), and “Graviton + Photon” instances. Points that are closer to the bottom left hand corner of the graph are both “faster and cheaper.”
In the graph below, we can see two clear “clusters”, basically with and without Photon. It’s clear from this data that Photon is legitimately faster. Unfortunately, it doesn’t appear any cheaper, so if your goal is to save money these results are a bit of a downer. If you’re trying to run faster, Photon may be exactly what you’re looking for.
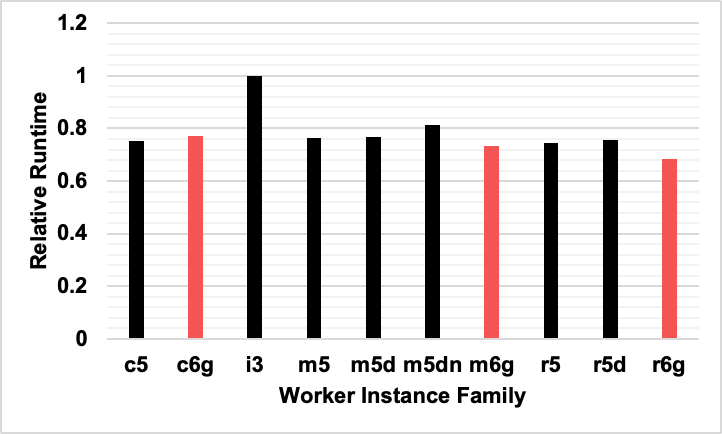
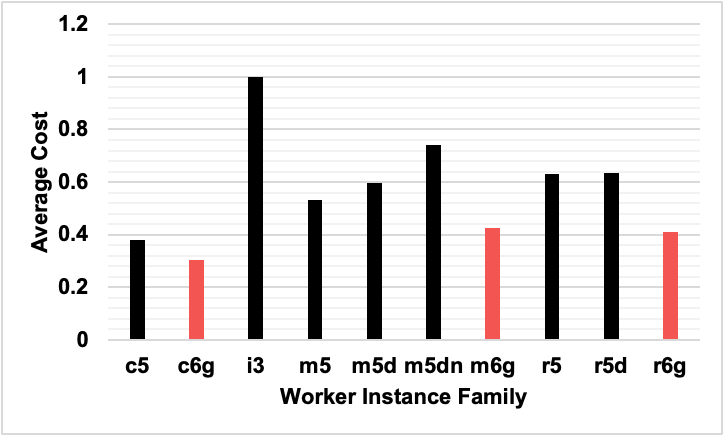
The two bar graphs below contain the same data as the XY plot above, but they break out the data into runtime and DBU costs separately. Also, we present the individual instances used, in case people would like a more granular view into the data.

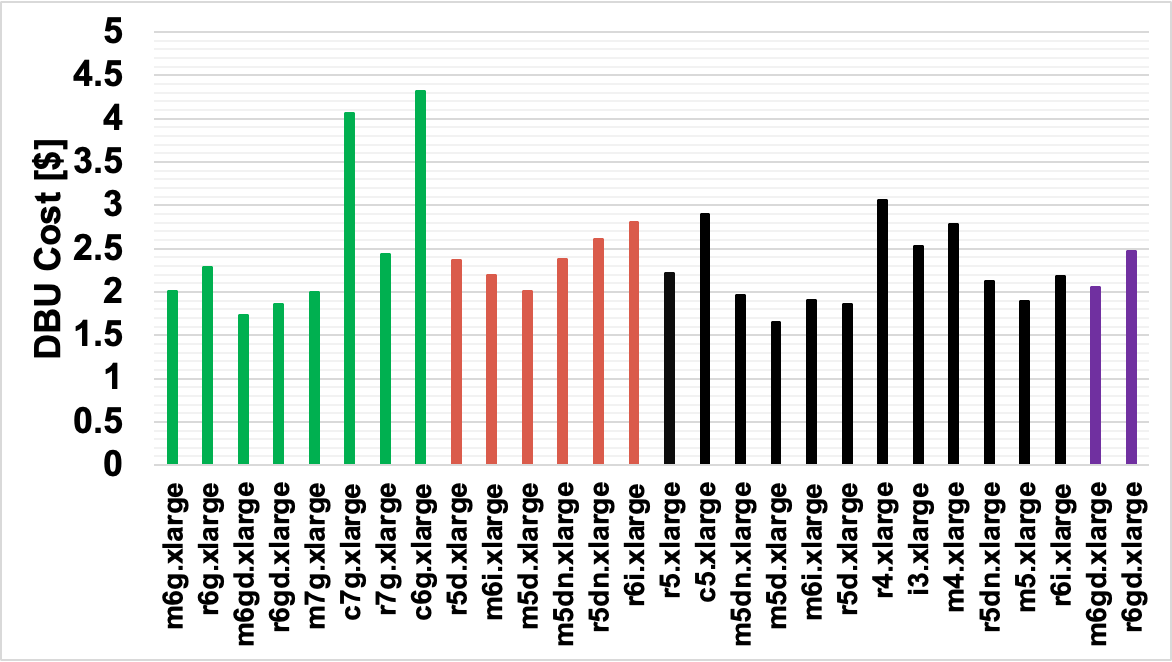
After perusing through the data, our main observations are outlined below. I’d like to heavily caution that these observations are purely from the experiment we ran above. We urge people to exercise caution when trying to generalize these results, as individual jobs can have wildly different results than the ones we showed above. With that said, these are the main takeaways:
- Photon is generally 2x faster – Across the board Photon was about 2x faster than their non-photon counterparts (same instances). This was great to see. Although not as high as some of the claims reported by Databricks, we understand that it is highly dependent on the workload. In my opinion a 2x speedup is pretty impressive.
- Graviton was neutral – The runtime for graviton was perhaps a bit faster than standard instances, but it’s unclear if it’s statistically significant. There doesn’t seem much risk to using Graviton, and they are newer chips so maybe they will be faster for your jobs?
- Photon’s total cost is cheaper (with this data) – In the data above, since the DBU costs were about the same across all 3 types, and Photon’s runtimes were about 2x faster, one can logically conclude that the cloud portion of the costs (the AWS fees) will be less with Photon. As a result, the total cost for an end user was cheapest with Photon enabled.
- Photon pricing makes for complex cost ROI – Because of the previous point, determining the ROI of Photon is difficult. It basically boils down to if the speedup is fast enough to endure the increased cost. If it does not, then users are essentially paying more money for a potentially faster job. If Photon speedup is fast enough, then it will be cheaper. What that threshold is will depend on the market and any discounts. For the sake of this study, the crossover point for on-demand instances was around 20%. Meaning, Photon needs to be at least 20% faster than Standard to observe any cost savings.
Formula for determining Photon ROI
For those that are mathematically inclined, here is a simple formula to help determine the “speedup threshold” which is the minimum speedup Photon needs to achieve for your job in order to break even. If your speedup is greater than this threshold, then you are saving money.

For a simple example, let’s say all of the machine and DBU costs are 1, and the Photon cost increase is a factor of 2, and we have 10 workers. With these very simple numbers, we get a Psth value of 1.5. Plugging in 1.5 for Psth and setting R_orig =1 and solving for R_photon, that means Photon needs to be 33% faster to break even. Clearly this value is heavily dependent on a lot of factors, all of which are shown in the equation above.
Conclusion
Overall the answers to the original two questions really comes down to “it depends.” The data points we showed above are an infinitely small slice of what workloads actually look like. Based on simply the data above, here are the answers:
1) Photon will probably be faster than non-photon, but whether or not it’s cheaper will depend on how much faster it is relative to the costs. To understand if the 2x DBU cost increase with Photon is worth it, it all depends on the markets and pricing of your cloud instances.
2) On average Graviton was about the same for cost and runtime compared to standard instances. We did not see any significant advantage of using Graviton here, but we didn’t see any downside either. Maybe these new chips will be perfect for your workload, or maybe not. It’s hard to tell.
However, with the data above, specifically around Photon, I can’t help but ask the question:
Is Databricks motivated to make Spark run faster?
This is an interesting philosophical question where the tech enthusiast may clash with the business units. The faster Databricks makes Spark, the less revenue they get, since they charge per minute. Photon is an interesting case study in which, yes, they made Spark 2x faster – but then had to double their costs to not lose money. This is at least one data point that shows you where Databricks basically sits: “Yes we can make Spark faster, but not cheaper.”
In my opinion, Databricks, and other cloud providers, are fundamentally motivated to increase revenue. So making Spark run faster and/or cheaper is not in alignment with where they need to do as a business. They will however make the product easier to use, or expand to other use cases which, fundamentally, increases revenue.
We of course respect the fact that any business needs to make money, so I don’t think anything improper is happening here. But it does reveal an interesting conflict between technology and business and how that fundamentally impacts the end user.