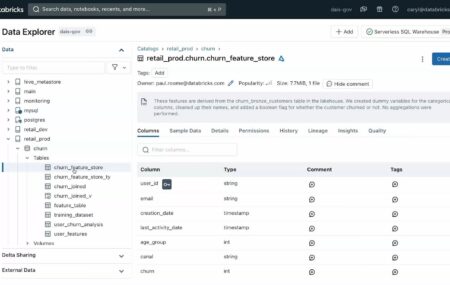
What is Databricks Unity Catalog (and Should I Be Using It)?
What is Databricks Unity Catalog (and Should I Be Using It)?
To help in your understanding, we wrote this blog post to address the question, “What is Databricks Unity Catalog?” and whether users should be using it (the answer is yes). We walk through a precise technical answer, and then dive into the details of the catalog itself, how to enable it and frequently asked questions.

Jeffrey Chou
29 May 2024
![]()
Blog
March 2024 Release Notes
March 2024 Release Notes
Our team has been hard at work to deliver industry-leading features to support users in achieving optimal performance within the Databricks ecosystem. Take a look at our most recent releases below. Worker Instance Recommendations Introducing Worker Instance Recommendations directly from the Sync UI. With this feature, you are able to tap into optimal cluster configuration
Jeffrey Chou
26 Mar 2024

News
Are Databricks clusters with Photon and Graviton instances worth it?
Are Databricks clusters with Photon and Graviton instances worth it?
Configuring Databricks clusters can seem more like art than science. We’ve reported in the past about ways to optimize worker and driver nodes, and how the proper selection of instances impacts a job’s cost and performance. We’ve also discussed how autoscaling performs, and how it’s not always the most efficient choice for static jobs. In
Jeffrey Chou
17 Aug 2023
![]()
Blog
How to Use the Gradient CLI Tool to Optimize Databricks / EMR Programmatically
How to Use the Gradient CLI Tool to Optimize Databricks / EMR Programmatically
Introduction: The Gradient Command Line Interface (CLI) is a powerful yet easy utility to automate the optimization of your Spark jobs from your terminal, command prompt, or automation scripts. Whether you are a Data Engineer, SysDevOps administrator, or just an Apache Spark enthusiast, knowing how to use the Gradient CLI can be incredibly beneficial as

Pete Tamisin
11 Jul 2023

Blog, Case Study
Integrating Gradient into Apache Airflow
Integrating Gradient into Apache Airflow
Summary In this blog post, we’ll explore how you can integrate Sync’s Gradient with Airflow. We’ll walk through the steps to create a DAG that will submit a run to Databricks, and then make a call through Sync’s library to generate a recommendation for an optimized cluster for that task. This DAG example can be

Brandon Kaplan
27 Jun 2023
![]()
Blog
Introducing: Gradient for Databricks
Introducing: Gradient for Databricks
Wow the day is finally here! It’s been a long journey, but we’re so excited to announce our newest product: Gradient for Databricks. Checkout our promo video here! The quick pitch Gradient is a new tool to help data engineers know when and how to optimize and lower their Databricks costs – without sacrificing performance.
Jeffrey Chou
19 Jun 2023
![]()
Blog