Do Graviton instances lower costs for Spark on EMR on AWS?

We perform a cost and runtime evaluation of Graviton instances for Apache Spark on EMR AWS using the TPC-DS 1TB benchmark.

Here at Sync we are passionate about optimizing cloud infrastructure for Apache Spark workloads. One question we receive a lot is
“Do Graviton instances help lower costs?”
For a little background information, AWS built their own processors which promise to be a “major leap” in performance. Specifically for Spark on EMR, AWS published a report that claimed Graviton can help reduce costs up to 30% and speed up performance up to 15%. These are fantastic results, and who doesn’t love a company that builds their own hardware.
As an independent company, here at Sync, we of course always want to verify AWS’s claims on the performance of Graviton instances. So in this blog post we run several experiments with the TPC-DS benchmark with various driver and worker count configurations on several different instance classes to see for ourselves how these instances stack up.
The Experiment
The goal of the experiment is to see how Graviton instances perform relative to other popular instances that people use. There are of course hundreds of instances types, so we only selected 10 popular instances to make this a feasible study.
As for the workload, we selected the fan favorite benchmark, TPC-DS 1TB, with all 98 queries run in series. This is different compared to what AWS used in their study, which was to look at individual queries within the benchmark. We decided to track the total job runtime of all queries since we’re just looking for the high level “average” performance to see if any interesting trends appear. Results of course may vary query by query, and of course your individual code is a complete wildcard. We make no claim that these results are generally true for all workloads or your specific workloads.
The details of the experimental sweeps are shown below:
- Workload: TPC-DS 1TB (queries 1-98 run in series)
- EMR Version: 6.2.0
- Instances: [r6g, m5dn, c5, i3, m6g, r5, m5d, m5, c6g, r5d] (bold are the Graviton instances)
- Driver Node sizes: *.xlarge, *.2xlarge, *.4xlarge (* = instances)
- Worker Nodes: *.xlarge
- Number of workers: [5,12,20,32,50]
- Cores.executor: 4
- Market: on-demand, list pricing
- Cost data: True AWS costs extracted from the cost and usage reports, includes both EC2 and EMR fees
The Result
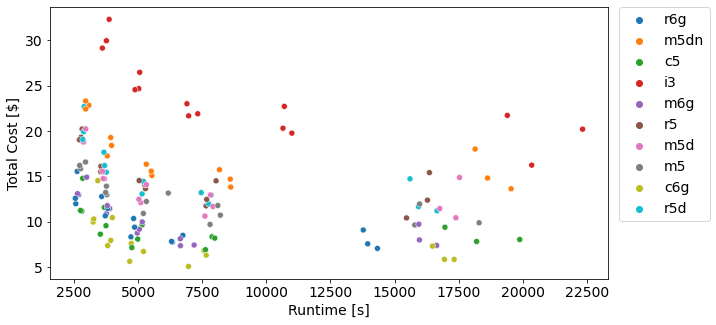
Below is a global view of all of the experiments run showing cost vs. runtime. Each dot represents a different configuration as described by the list above. Points that are in the bottom left hand corner edge are ideal as they are both cheaper and faster.
At a high level, we see that the c6g instances (light green dots) were the lowest cost with comparable runtimes, which was interesting to see. The other two graviton instance (r6g and m6g) skewed lower-left than most of the other instances as well.
One deviation is the c5 instances performed surprisingly well on both the cost and runtime curves. They were quite similar to the best graviton chip, the c6g.
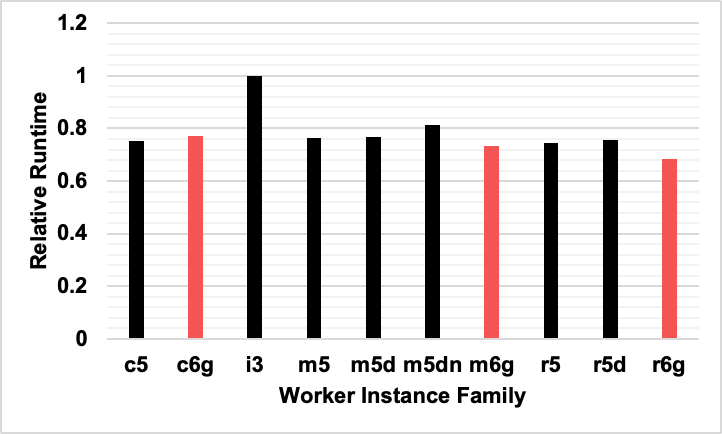
To make the information a bit easier to digest, we take an average of the runtime and cost data to do a clear side by side comparison of the different instances. The salmon colored bars are the Graviton enabled instances.
In the graph below the runtime of Graviton instances were comparable with other instances. The r6g instances were the fastest instances, although not by much – only about 6.5% faster than m6g. The one negative standout was that the i3 instances took around 20% longer runtime than all of the other instances.
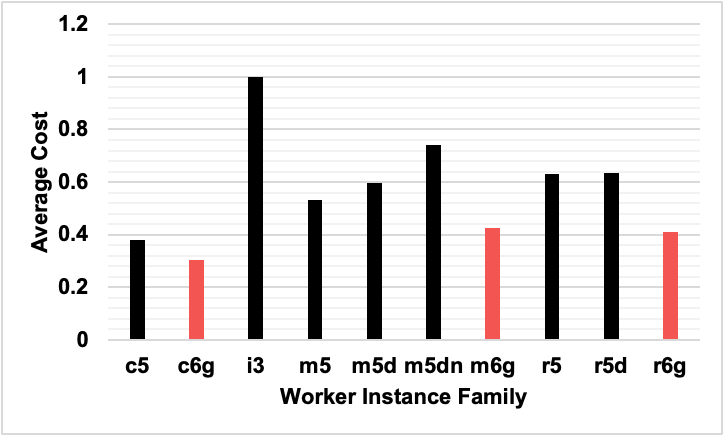
More variation is seen in the cost breakdown, where we see that the Graviton instances were typically lower cost than their non-Graviton counterparts, some by a wide margin. What really stole the show were the “c” class instances, where c5 actually was cheaper by about 10% than the m6g and r6g Graviton instances.
The global winner was the c6g instance, which was the absolute cheapest. It’s interesting to see the significant cost difference between the max (i3) and min (c6g), which shows a 70% cost difference!
Based on the data above, it’s interesting to see that the runtime of Graviton instances was comparable to other non-Graviton instances. So, what then was the cause of the huge cost differential? It seems at the end of the day the total job cost generally followed the trends of the list prices of the machines. Let’s look deeper.
The table below shows the list price of the instances and their on-demand list price, in order of lowest to highest cost. We can see the lowest instance cost was the Graviton instance c6g, which corresponds to the study above where the c6g was the lowest cost.
However, there were some exceptions where more expensive instances still had cheaper total job costs:
- c5.xlarge – Was the 3rd lowest cost on-demand price, however had the 2nd cheapest overall job cost
- R6g.xlarge – Was the 5th lowest cost on-demand price, however had the 3rd cheapest overall job cost
These two exceptions show that the actual list price of the instances doesn’t always guarantee overall total cost trends. Sometimes the hardware is such a great fit for your job that it overcomes the higher cost.
| Instance | List Price On-Demand |
| c6g.xlarge | 0.136 |
| m6g.xlarge | 0.154 |
| c5.xlarge | 0.17 |
| m5.xlarge | 0.192 |
| r6g.xlarge | 0.2016 |
| m5d.xlarge | 0.226 |
| r5.xlarge | 0.252 |
| m5dn.xlarge | 0.272 |
| r5d.xlarge | 0.288 |
| I3.xlarge | 0.312 |
Conclusion
So at the end of the day, do Graviton instances save you money? From this study, I’d say that on average their cost/performance numbers were in fact better than other popular instances. However, as we saw above, it is not always true and, like most things we post – it depends.
If you’re able to explore different instance types, I’d definitely recommend trying out Graviton instances, as they look like a pretty solid bet.
To revisit the claims that AWS had about Graviton instances being 30% cheaper and 15% more performant, based on the data above that is not always true and depends on a lot of cluster parameters.
For example, one thing we’ll note is that in the AWS study, they only used workers with *.2xlarge instances, whereas our study only looked at *.xlarge worker node instances. I also have no idea what Apache Spark configurations they used and if they matched what we did or not.
At the end of the day, everything depends on your workload and what your job is trying to do. There is no one-size-fits-all instance for your jobs. That’s why we built the Apache Spark Gradient to help users easily optimize their Apache Spark configurations and instance types to help hit their cost and runtime needs.
 Noa Shavit
Noa Shavit