
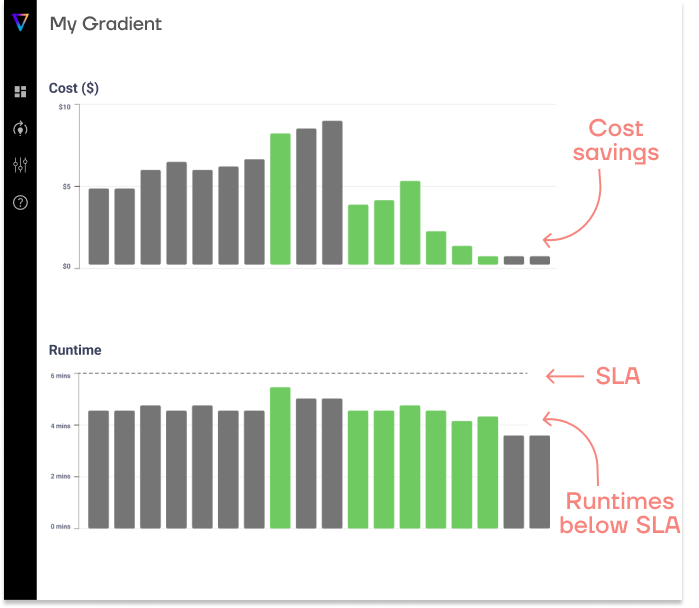
Save up to 50% on compute!
Save on compute while meeting runtime SLAs with Gradient’s AI compute optimization solution.

The exponential growth of data in recent years has revolutionized the way businesses operate and make decisions. From small start-ups to large enterprises, organizations across industries are leveraging data to gain competitive advantages, optimize operations, and drive innovation. However, with this data surge comes the challenge of efficiently storing, processing, and retrieving vast amounts of information.
While traditional solutions like SQLite and MySQL have their place, modern data platforms like DuckDB, Snowflake, and Databricks are reshaping the landscape of data processing.

 : DuckDB has carved out a niche as a lightweight, in-process analytical database, ideal for quick analyses of local datasets using SQL queries.
: DuckDB has carved out a niche as a lightweight, in-process analytical database, ideal for quick analyses of local datasets using SQL queries.
 : Snowflake has revolutionized the data warehousing space with its cloud-native, scalable architecture, offering comprehensive data storage, processing, and AI integration capabilities.
: Snowflake has revolutionized the data warehousing space with its cloud-native, scalable architecture, offering comprehensive data storage, processing, and AI integration capabilities.

 : Databricks offers a unified platform for big data processing and machine learning, building on the power of Apache Spark, and providing a complete ecosystem for data storage, processing, and advanced analytics.
: Databricks offers a unified platform for big data processing and machine learning, building on the power of Apache Spark, and providing a complete ecosystem for data storage, processing, and advanced analytics.As we delve into the comparison of these data analytics platforms, it’s important to note that each has its strengths and is designed with specific use cases in mind. Understanding these differences is crucial for selecting the right tool for your data processing needs.
Save on compute while meeting runtime SLAs with Gradient’s AI compute optimization solution.
To truly appreciate the capabilities and limitations of DuckDB, Snowflake, and Databricks, we need to understand their underlying architectures.

DuckDB stands out with its unique architecture as an embeddable SQL OLAP (Online Analytical Processing) database management system. Unlike traditional client-server database systems, DuckDB runs entirely within the process of the host application.
Snowflake takes a radically different approach with its cloud-native, fully managed data warehouse architecture. Its unique design separates compute and storage, allowing for independent scaling of these resources.
Snowflake’s architecture is focused on providing a fully managed data cloud, with strong emphasis on separating storage and compute for optimal performance and cost management in cloud environments.
Databricks offers a comprehensive platform that combines the power of Apache Spark with additional proprietary technologies to create a unified environment for data engineering, analytics, and machine learning.
Databricks implements a lakehouse approach, combining the best features of data warehouses and data lakes. The data cloud was actually the first to come up with this hybrid concept. This architecture allows for more flexible data storage and processing options, particularly suited for organizations with diverse data types and advanced analytical needs.
Understanding the typical use cases for each platform is crucial in determining which solution aligns best with your organization’s needs. Let’s explore the scenarios where DuckDB, Snowflake, and Databricks excel.

DuckDB shines in scenarios that require quick, efficient analysis of small to medium-sized datasets. Some of the DuckDB use cases are:
The Python-based open-source data analysis project, pandas, is another popular tool for data manipulation. DuckDB stands out as an attractive alternative when dealing with datasets that exceed in-memory limits. While pandas is well-suited for small in-memory datasets, DuckDB scales more effectively, allowing you to work with larger datasets without performance degradation due to memory constraints.
Snowflake’s cloud-native architecture is designed to handle large-scale, enterprise-level data pipelines. It excels in:
Databricks offers a comprehensive platform that caters to a wide range of big data and machine learning use cases:
Related posts:
We also put together a comprehensive guide on Databricks vs. Snowflake earlier this year. Check it out for an even more focused head-to-head comparison of these two data clouds.
As data volumes and requirements grow, the performance and scalability of a data processing platform become critical factors. Let’s examine how DuckDB, Snowflake, and Databricks handle increasing workloads and compare their capabilities in this area.
DuckDB’s in-process architecture gives it a significant performance advantage for certain types of workloads, particularly when dealing with local, moderately sized datasets.
Snowflake’s cloud-native architecture is designed for elastic scalability, allowing it to handle growing workloads with ease.
Databricks leverages the distributed computing capabilities of Apache Spark, enhanced with proprietary optimizations, to deliver high performance and scalability for big data workloads.
To further optimize Databricks’ performance and scalability, Sync’s Health Check provides instant insights into how your organization utilizes the platform. It pinpoints inefficiencies and surfaces opportunities to enhance performance, resource allocation, and cost efficiency.
The usability and integration capabilities of a data processing platform can significantly impact its adoption and effectiveness within an organization. Let’s explore how DuckDB, Snowflake, and Databricks compare in terms of ease of use and their ability to integrate with existing tools and workflows.
DuckDB stands out for its simplicity and ease of use, particularly for users familiar with SQL.
DuckDB’s simplicity makes it an excellent choice for data scientists who need quick access to SQL capabilities without the overhead of setting up a database server. Its ability to work directly with files and integrate with popular data science tools enhances its utility in analytical workflows.
Snowflake offers a user-friendly interface combined with powerful management features, aiming to simplify data warehousing operations.
Databricks offers a unified platform that combines ease of use with advanced features for data engineering, analytics, and machine learning.
The choice between these platforms often depends on the technical expertise of your team, the complexity of your data workloads, and the level of integration required with existing systems and tools.
Related posts:
Read more on Apache Spark scaling (AWS EMR and Databricks) and the top three trends we discovered.
Understanding the cost structures and pricing models of DuckDB, Snowflake, and Databricks is crucial for making an informed decision that aligns with your organization’s budget and data processing needs. Let’s break down the pricing approaches of each platform and consider their cost-effectiveness for different scenarios.
DuckDB stands out in this comparison because it’s open-source and free, meaning there’s no formal cost structure.
While the software itself is free, there may be indirect costs associated with:
Snowflake employs a consumption-based pricing model, aligning costs with actual usage.
Pricing for running your jobs on Databricks is also usage based. However, the platform has a more complex pricing structure, for some of its features (e.g. SQL warehouse). To fully understand your costs, check out our extensive post on Databricks pricing and how to optimize your expenses.
When evaluating the cost-effectiveness of these platforms:
It’s crucial to consider not just the direct costs, but also the potential savings in development time, management overhead, and the ability to derive value from data quickly. A platform that appears more expensive upfront may prove cost-effective if it significantly enhances productivity or enables new revenue-generating insights.
When selecting between DuckDB, Snowflake, and Databricks, consider these key factors:
Choose based on your use case data volume, analytical complexity, team expertise, budget, and growth projections. Remember, these platforms can be complementary, often used in combination to address diverse data processing needs.
| Feature | DuckDB | Snowflake | Databricks |
| Architecture |  In-process, columnar In-process, columnar | Cloud-native, separate storage & compute |  Unified analytics platform Unified analytics platform |
| Best for |  Local analytics, data science Local analytics, data science |  Enterprise data warehousing, AI/ML integration Enterprise data warehousing, AI/ML integration |  Big data processing, ML/AI Big data processing, ML/AI |
| Data scale | Small to medium | Large |  Very large (Big Data) Very large (Big Data) |
| Setup complexity |  Minimal Minimal | Moderate |  High High |
| Control over costs | N/A | Minimal | Moderate, but it’s difficult to tune clusters |
| Scalability | Limited (single machine) | Highly scalable (cloud) |  Highly scalable (distributed) Highly scalable (distributed) |
| Cost |  Free, open-source Free, open-source |  Pay-as-you-go Pay-as-you-go | Consumption-based |
| Language support |  SQL, Python, R, Java SQL, Python, R, Java | SQL (primary). Python, Java, and Scala support via Snowpark | SQL, Python, R, Scala, Java |
| Unique strength | Simplicity & speed for local data |  Easy scaling & data sharing Easy scaling & data sharing |  Unified platform for diverse workloads Unified platform for diverse workloads |
This table provides a quick overview of the key characteristics of each platform, allowing for easy comparison across important features.
DuckDB, Snowflake, and Databricks each offer unique approaches to modern data processing challenges. The rapid evolution of these platforms reflects the growing complexity and scale of data operations in today’s business landscape.
While choosing the right platform is crucial, it’s equally important to foster a data-driven culture within your organization. Invest in training, encourage experimentation, and be prepared to adapt as your needs change and new technologies emerge.
Whether you’re choosing between DuckDB, Databricks, and Snowflake for cloud-based analytics, or considering DuckDB as an alternative to pandas for local data processing, understanding these platforms’ strengths is key to making the right decision for your data strategy. By making informed decisions and leveraging the strengths of these modern data processing platforms, you can position your organization to thrive in an increasingly data-centric world.
Try Gradient
As compute costs (and engineering hours) increase, an automated cluster management solution is practically mandatory. Our product, Gradient, helps data engineers and platform managers achieve optimal cost and runtime performance without manual tuning – resulting in:
 Kartik Nagappa
Kartik Nagappa