
Save up to 50% on compute!
Save on compute while meeting runtime SLAs with Gradient’s AI compute optimization solution.

To much fanfare, Databricks announced their wide release of serverless compute across all of their platforms at the Data + AI 2024 conference. It’s quite clear that Databricks’ vision is to own the compute layer to make life easier for end users, so they don’t have to worry about annoying cluster or versions details.
We at Sync are all about cloud compute efficiency. So of course we had to take a closer look at Databricks Serverless Compute to provide an honest perspective of serverless computing compared classic computing, and evaluate the pros and cons.
Full disclosure – Sync is a Databricks partner. With that said, everything we state here is merely our opinion, which is based on the experimental measurements covered below. Our goal is to provide an unbiased guide, so that users can decide for themselves whether or not serverless is a good choice for them.
This post focuses on the jobs serverless feature, which is currently under public preview. We also covered the Databricks SQL warehouse serverless product here.
At a high level, serverless means that end users don’t have to provision cloud infrastructure anymore. Databricks will do it all for you, so users can just focus on their code. For example, selecting which instances to use is now under the control of Databricks, not the end user.
While this sounds like a no-brainer, if you zoom in a bit closer there are some pros and cons. Let’s use an analogy here. Let’s say you want to travel from San Francisco to London.
If you’re a high volume traveler for business, you may prefer the high level of control the “classic” way brings, since you need that level of granularity. If you’re a wealthy aimless traveler just enjoying the world, serverless is probably the dream. It all depends, both methods are potentially great.
As you review the results, we’d like you to bear in mind that jobs serverless will most likely improve with time, and that our current results are merely a snapshot in time. Will these numbers hold up in 1 year? Maybe, maybe not – we have no idea. We can only hope that this feedback helps shape the offering with some honest feedback from the field.
Now for the good stuff: here are the top 9 lessons learned from evaluating Databricks Jobs Serverless.
Read on for our in-depth analysis of Databricks server vs. serverless computing.
By far, the biggest hope users have for serverless is that “it will optimize my compute for me.” While this is true in some regard, the core issue users need to understand is “Does serverless provide the lowest cost option?” We can answer very clearly and unambiguously that, unfortunately, it does not. Serverless is not the cheapest option around.
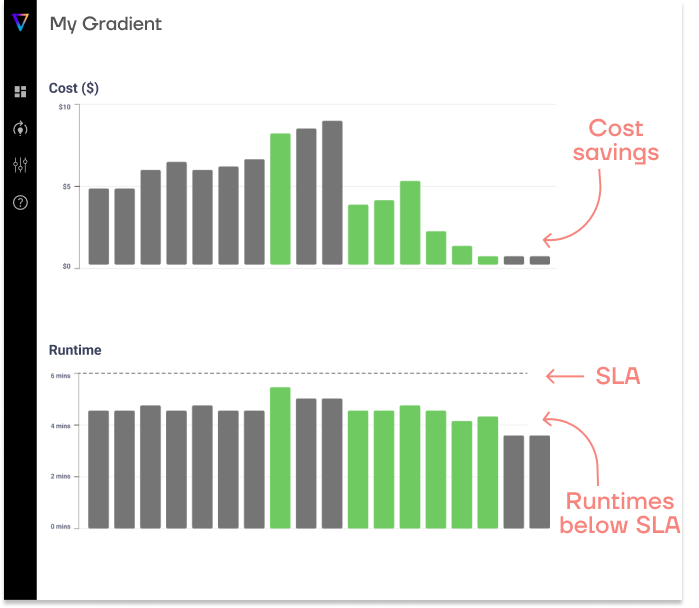
While serverless is a pretty good option, it’s certainly not the most optimal when it comes to cost for all use cases. As evidence, we ran a test job and found that an optimized cluster by Gradient (our flagship product), outperformed Databricks serverless jobs by roughly 60% from a cost perspective!
Our test job runs basic queries on a randomly generated dataset. The runtime on a classic cluster is about 1 hour, which is pretty typical in many jobs we’ve encountered at companies. Serverless was able to run the job much faster, taking only 30 minutes which was great to see. Unfortunately, the runtime savings didn’t translate to the cost savings, as you can see in the chart below.

In the test, we are utilizing on-demand instances with list pricing. Users will likely save even more if using Spot instances. However, you have no option to use spot instances with serverless. You have no access at all to what’s going on.
This test result might not translate to your internal jobs. You may have a job that demonstrates that serverless massively outperforms an optimized cluster in terms of costs – it all depends on your workload. With that said, this data point does prove that serverless is not GLOBALLY optimal. Serverless does not guarantee cost savings.
Some skeptics might say that the cost savings of serverless appears in the form of engineering hours saved. With serverless, engineers don’t have to spend time thinking about clusters – which can translate to real time and money saved. We completely agree with this point of view, that is very substantial.
Our one counter argument is that getting started on any cluster is pretty easy today, so most people don’t spend time tuning their clusters if they don’t want to. Engineers typically resort to cluster tuning to help lower cost or improve performance. So if the cost and performance of Serverless is not ideal, you’re just out of luck – serverless may not be solving the root issue that tuning is attempting to solve.
At the end of the day, everything depends on the particularities of your workload and use case.
Save on compute while meeting runtime SLAs with Gradient’s AI compute optimization solution.
A great use case for serverless, which we fully endorse, is using serverless for short (<5 min) jobs. The elimination of spin up time for your cluster is a massive win that we really love.
Here’s an experiment we ran using a trivial job that doesn’t really do anything. The job doesn’t even run Spark and is run on a single node cluster. The cost was slightly lower with serverless, but the big win was in the runtime where we saw roughly 80% reduction in runtime! This improvement is mostly due to the complete elimination of cluster spin up time which can take 5-10 minutes.
What’s interesting is even though serverless does not have spin up time, the cost premium for serverless still equated to roughly the same overall cost – which was a bit disappointing.

With that said, the big win is that users may not always know that they are running a short job and could be massively over provisioning their clusters on accident.
Serverless helps to avoid that mistake and that can result in substantial big cost savings – simply preventing human error.

We couldn’t love this aspect enough. Cluster spin up time is such a pain to deal with when you’re just trying to run something in real-time. So many times users have to wait for a cluster to spin up and get sidetracked by another task so that they don’t come back to the cluster until an hour later.
Our one nit pick here is that for scheduled jobs in a pipeline, spin up time is less of a concern. These are jobs that can be running at all hours of the day at scales of 1000s of jobs running per day. At that level, spin up time is really a cost factor – and then the real question is if serverless provides the lowest cost.
However, if you’re doing a quick ad-hoc experiment, or just want to get a quick result – we highly recommend serverless as you’ll get your result much faster.
Something quite unique about Databrick jobs serverless is that there are zero knobs. Not even “T-shirt” sizing, like what we have today in SQL serverless platforms. This means that you can’t even select “small, medium, large, x-large” clusters – you don’t get to select anything.
For a company that is just trying to get jobs up and running asap, we think this can be pretty great. It can save engineers some time when it comes to provisioning infrastructure.
The big tradeoff is that you can’t change anything. If you care about cost and runtime and want the ability to tune performance, then this may not be a convenient feature.
The big downside of jobs serverless is that there’s no way to tune the cluster to adjust cost or runtime. You basically have to live with whatever Databricks decides. This means that if you want faster runtime, you can’t just throw a bigger cluster at it and call it a day. You can’t do anything really, except change your code. You’re stuck.
We can only assume that eventually Databricks will throw in some high-level “performance” knob, as we think this is a pretty big limitation, but who knows.
Serverless utilizes shared compute resources in the background, and as a result enforces a large number of general restrictions. We’ve heard rumors that it’s a giant Spark on Kubernetes clusters, but don’t quote us on that.
A couple impactful restrictions of serverless are:
This goes on and on, exceeding over 100 limitations. We, in fact, had a hard time getting ANY job to run on serverless. We ran into issues even with simple test jobs. It wasn’t until we manually changed the code and moved data around that we finally got it to work.
Our opinion is unless this is improved dramatically, it will be a giant lift and shift amount of work for enterprises who built their jobs on classic compute. Serverless eliminates the general flexibility we had on classic clusters. This will likely slow the adoption of serverless for larger companies. Probably new workloads will get onboarded to serverless first, before any big migration effort takes place.
One thing we found troubling was the pricing. On the Databricks website they say that the cost is $0.35/DBU. But, where is the DBU/hr metric? Normally, one would take the runtime of the job and calculate a $/hr rate. Then, a user could tune the cluster size and tune the rate of cost. But with zero knobs, we have no control over the rate of cost.
It appears that we only get the number of DBUs a job costs AFTER it completes via the system tables. We find it odd that this number is calculated completely in the dark. Today my job costs 10 DBUs, next month it may cost 12 DBUs. Why? No clue. The amount of power Databricks has here is a bit overreaching in our opinion.
In fact, because there is no DBU/hr metric, the “list price” they have here of $0.35/DBU is incomplete. Since the amount of DBUs my jobs cost is solely under Databricks’ control, the end price is pretty much arbitrary. For example, the calculation of job cost is simply: $0.35/DBU * X DBU, where X is the amount of DBUs Databricks determines and reports in the system tables.
This is quite the advantage for Databricks, and in our opinion, it will result in large revenue and profit growth. Any compute optimization they do on the backend helps widen their margins, while the cost to the user stays mysterious. I don’t blame Databricks for doing this, and this is also not a new concept. In fact, many companies prefer to run serverless for this revenue generating reason. Users get “convenience” and Databricks makes more money, it’s a fair exchange.
What’s funny is that this is approaching the Snowflake’s serverless model. Not only is Snowflake the company’s mortal enemy, many people complain that Snowflake is too expensive for this very reason. It will be interesting to see how the market reacts in the long run and if sticker shock to their serverless bills will cause some CFOs to take action.
Related: DuckDB vs. Snowflake vs. Databricks: A Comprehensive Comparison
Save on compute while meeting runtime SLAs with Gradient’s AI compute optimization solution.
In Spark-land, everyone knows of the dreaded out of memory (OOM) error. What happens if the cluster under the serverless hood hits this error for your job? Typically we would try to fix this with more memory, but we don’t have that option with serverless.
Are users now dependent on Databricks to fix this? That could be dangerous. In cluster-land, a million things can go wrong, and now that it’s all managed by Databricks you’re pretty much at the mercy of their support team if anything critical goes down.
If you have established special discounts with AWS or Azure, or custom plans for certain instances – listen up. If you use serverless jobs those discounts can become irrelevant in regards to your Databricks usage. This is because on serverless the compute runs inside the Databricks environment.
This may or may not apply to your company, it really depends on the nature of your contracts and the volume of your Databricks usage. We thought we’d point it out as it is a major difference between classic and serverless compute.
Distributed computing is a very complex topic, and rarely is anything a guaranteed slam dunk. In this post, we covered the pros and cons of Databricks serverless jobs as it is today.. Some will find this capability beneficial and that’s fantastic! Based on our initial analysis, we found serverless jobs to be ideal for short and ad-hoc jobs, as the largest value add is the elimination of spin up times.
As most companies, Databricks’ marketing overshoots the benefits of their features from time to time. We’ve already reported on this in regards to Photon and Autoscaling, and we hope we have now sprinkled some truth in regards to Serverless as well. By the way, Databricks states that Photon and autoscaling are automatic for jobs serverless, which in our analysis, often leads to unnecessary cost increases.
As you can imagine, we get a lot of questions about serverless. Here are the top two questions we are asked about Databricks serverless jobs:
Yes, Databricks has presented materials touting that serverless is cost efficient relative to classic compute. This presentation from DAIS 2024 is a great example. The real question is – what do you compare serverless to? If you’re comparing serverless to just default settings, then serverless may likely do very well. But a workload optimized cluster can likely outperform serverless. Finding an optimized cluster, though, is by no means an easy feat. How do we determine how “optimal” it is?
Skeptics may say that we are biased as well, that examples above are based on jobs we knew could outperform serverless. This is a totally fair position to have. For the record – we did not cherry pick a workload in our tests, we just quickly found the first job we could that was even compatible with serverless.
At the end of the day, benchmarks presented by external parties can be totally irrelevant to your use case. Fancy benchmarks like TPC-DS, or even the one we shared in this post do not look like your jobs. There’s only one thing that really matters: YOUR WORKLOADS.
Finally, we say, don’t take our word for it, nor Databricks’. Compare serverless head to head with an optimized classic cluster and see for yourself. If you need help, Gradient is here to lead you to help that coveted optimized cluster. Or, if you have the knowledge and skills, you can manually optimize your cluster and compare it to serverless.
Does serverless impact the Sync roadmap? We have short term and a long term answers to this question:
Short term: Serverless and classic will co-exist for quite some time. We see serverless as just another option (like Photon, or autoscaling). Sync’s algorithms can test whether serverless or an optimized classic cluster is best for your needs, and share recommendations or auto-apply those changes for you. At the end of the day, all we care about is selecting the best options and configurations based on your goals. If serverless is that, then we’ll be happy to point your jobs in that direction.
Long term: We are a cloud compute management company, and Databricks is just the first stop in our evolution. Our plan is to expand to all facets of cloud computing, from Spark, to bare CPUs, GPUs, Kubernetes etc., it’s all up for grabs. Databricks has been a great partner and an important first step, but longer term, it will be one of dozens of platforms we support. Our guess is optimizing classic compute will play a role for Databricks users for many years to come, and we’re happy to help them with that
Like we said earlier, don’t take our word for it. Try serverless out for yourself, do your own homework. Conduct an A/B test and see if serverless is actually cost effective. If you need help automatically finding the optimized classic cluster, feel free to check us out.
 Kartik Nagappa
Kartik Nagappa
 Noa Shavit
Noa Shavit