April 2024 Release Notes
April 2024 Release Notes
Our April releases are here! Take a look at Sync’s latest product updates and features. Sync’s Databricks Workspace health check is now self-serve and available as a notebook that you simply download and run on your own. With the notebook, you’ll be able to answer questions such as: ⚙️ What is the distribution of job

Jeffrey Chou
29 Apr 2024
![]()
News, Releases
March 2024 Release Notes
March 2024 Release Notes
Our team has been hard at work to deliver industry-leading features to support users in achieving optimal performance within the Databricks ecosystem. Take a look at our most recent releases below. Worker Instance Recommendations Introducing Worker Instance Recommendations directly from the Sync UI. With this feature, you are able to tap into optimal cluster configuration
Jeffrey Chou
26 Mar 2024

News
February 2024 Release Notes
February 2024 Release Notes
We’re excited to share all the new and improved features that our team has recently released to help our customers gain full governance over their Databricks infrastructure. Databricks Workspace IntegrationIntroducing the Databricks Workspace Integration for Gradient. With this new feature, you’re able to further simplify the process of connecting your Databricks Workspace to the Sync
Jeffrey Chou
21 Feb 2024
![]()
Releases
Sync Computing Partners with Databricks for Lakehouse Job Cluster and Usage Optimization
Sync Computing Partners with Databricks for Lakehouse Job Cluster and Usage Optimization
Sync Computing Partners with Databricks for Lakehouse Job Cluster and Usage Optimization — Self-improving machine learning algorithms provide job cluster optimization and insights for Databricks users
Jeffrey Chou
01 Feb 2024

Press
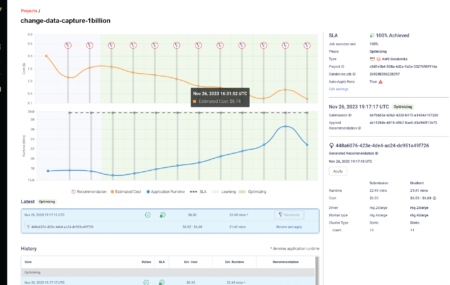
Gradient New Product Update Q4 2023
Gradient New Product Update Q4 2023
Today we are excited to announce our next major product update for Gradient to help companies optimize their Databricks Jobs clusters. This update isn’t just a simple UI upgrade… We upgraded everything from the inside out! Without burying the lead, here’s a screenshot of the new project page for Gradient above. Back in the last
Jeffrey Chou
27 Nov 2023
Blog, News
How to Use the Gradient CLI Tool to Optimize Databricks / EMR Programmatically
How to Use the Gradient CLI Tool to Optimize Databricks / EMR Programmatically
Introduction: The Gradient Command Line Interface (CLI) is a powerful yet easy utility to automate the optimization of your Spark jobs from your terminal, command prompt, or automation scripts. Whether you are a Data Engineer, SysDevOps administrator, or just an Apache Spark enthusiast, knowing how to use the Gradient CLI can be incredibly beneficial as

Pete Tamisin
11 Jul 2023

Blog, Case Study