
As many previous blog posts have reported, tuning and optimizing the cluster configurations of Apache Spark is a notoriously difficult problem. Especially when a data engineer needs to lower costs or accelerate runtimes on platforms such as EMR or Databricks on AWS, tuning these parameters becomes a high priority.
Here at Sync, we will experimentally explore the impact of driver sizing in the Databricks platform on the TPC-DS 1TB benchmark, to see if we can obtain an understanding of the relationship between the driver instance size and cost/runtime of the job.

Driver node review
For those who may be less familiar with the driver node details in Apache Spark, there are many excellent previous blog posts as well as the official documentation on this topic and I will recommend users to read those if they are not familiar. As a quick summary, the driver is an important part of the Apache Spark system and effectively acts as the “brain” of the entire operation.
The driver program runs the main() function, creates the spark context, and schedules tasks onto the worker nodes. Aside from these high level functions, we’d like to note that the driver node is also used in the execution of some functions, most famously when using the collect operation and broadcast joins. During those functions, data is moved to the driver node and if it’s not appropriately sized, can cause a driver side out of memory error which can shut down the entire cluster.
As a quick side note, for broadcast joins, It looks like a ticket has been filed to change this behavior (at least for broadcast joins) in the open source Spark core. So people should be aware that this may change in the future.

How Does Driver Sizing Impact Performance As a Function of the Number Of Workers?
The main experimental question we want to ask is “how does driver sizing impact performance as a function of the number of workers?” The reason why we want to correlate driver size with the number of workers is that the number of workers is a very important parameter when tuning systems for either cost or runtime goals. Observing how the driver impacts the worker scaling of the job is a key part of understanding and optimizing a cluster.
Fundamentally, the maximum number of tasks that can be executed in parallel is determined by the number of workers and executors. Since the driver node is responsible for scheduling these tasks, we wanted to see if the number of workers changes the hardware requirements of the driver. For example, does scheduling 1 million tasks require a different driver instance type than scheduling 10 tasks?
Experimental Setup
The technical parameters of the experiment are below:
- Data Platform: Databricks
- Compute type: Jobs (ephemeral cluster, 1 job per cluster)
- Photon Enabled: No
- Fixed parameters:: All worker nodes are i3.xlarge, all configs default
- Sweep parameters: Driver instance size (r5a.large, r5a.xlarge, r5a.4xlarge), number of workers
- AWS market: On-demand (to eliminate spot fluctuations)
- Workload: Databrick’s own benchmark on TPC-DS 1TB (all queries run sequentially)
For reference, here are the hardware specifications of the 3 different drivers used on AWS:

The result
We will break down the results into 3 main plots. The first is below where we look at runtime vs. number of workers for the 3 different driver types. In the plot below we see that as the number of workers increases the runtime decreases. We note here that the scaling trend is not linear and there is a typical “elbow” scaling that occurs. We published previously the general concept of scaling jobs. We observe here that the largest driver, r5a.4xlarge, yielded the fastest performance across all worker sizes.

In the plot below we see the cost (DBU’s in $) vs. number of workers. For the most part we see that the medium sized driver, r5a.xlarge is the most economical, except for the smallest number of workers where the smallest driver size r5a.large was the cheapest.

Putting both plots together, we can see the general summary when we plot cost vs. runtime. The small numbers next to each point show the number of workers. In general, the ideal points should be toward the bottom left, as that indicates a configuration that is both faster and cheaper. Points that are higher up or to the right are more expensive and slower.

Some companies are only concerned about service level agreement (SLA) timelines, and do not actually need the “fastest” possible runtime. A more useful way to think about the plot below is to ask the question “what is the maximum time you want to spend running this job?” Once that number is known, you can then select the configuration with the cheapest cost that matches your SLA.
For example, consider the SLA scenarios below:
1) SLA of 2500s – If you need your job to be completed in 2,500s or less, then you should select the r5a.4xlarge driver with a worker size of 50.
2) SLA of 4000s – If you need your job to be completed in 4,000s or less, then you should select the r5a.xlarge driver with a worker size of 20.
3) SLA of 10,000s – If you need your job to be completed in 10,000s or less, then you should select the r5a.large driver with a worker size of 5.
Key Insights
It’s very convenient to see the scaling trend of all 3 drivers plotted in this manner, as there are several key insights gained here:
- There is a general “good” optimal driver for TPC-DS 1TB – across the spectrum, it’s clear that r5a.xlarge is a good choice generally as it is usually cheaper and faster than the other driver sizes. This shows the danger that if your driver is too big or too small, you could be wasting money and time.
- At the extremes, driver size matters for TPC-DS 1TB – At the wings of either large clusters (50 workers) or small clusters (5 workers) we can see that the best driver selection can swing between all 3 drivers.
- Drivers can be too big – At 12 workers, the r5a.4xlarge performance is slightly faster but significantly more expensive than the other two driver types. Unless that slight speedup is important, it’s clear to see that if a driver is too large, then the extra cost of the larger driver is not worth the slight speedup. It’s like buying a Ferrari to just sit in traffic – definitely not worth it (although you will look cool).
- Small driver bottleneck – For the small driver curve (r5a.large), we see that the blue line’s elbow occurs at a higher runtime than the middle driver (r5a.xlarge). This implies that the smaller driver is creating a runtime bottleneck for the entire workload as the cluster becomes larger. The next section will dive into why.
Root cause analysis for the “small driver bottleneck”
To investigate the cause of the small driver bottleneck, we looked into the Spark eventlogs to see what values changed as we scaled the number of workers. In the Spark UI in Databricks, the typical high level metrics for each task are shown below and plotted graphically. The image below shows an example of a single task broken down into the 7 main metrics:

When we aggregated all of these values across all tasks, across all the different drivers and workers, the numbers were all pretty consistent, except for one number: “Scheduler Delay”. For those who may not be familiar, the formal definition from the Databricks Spark UI, is shown in the image below:
“Scheduler delay includes time to ship the task from the scheduler to the executor, and time to send the task result from the executor to the scheduler. If scheduler delay is large, consider decreasing the size of tasks or decreasing the size of task results.”
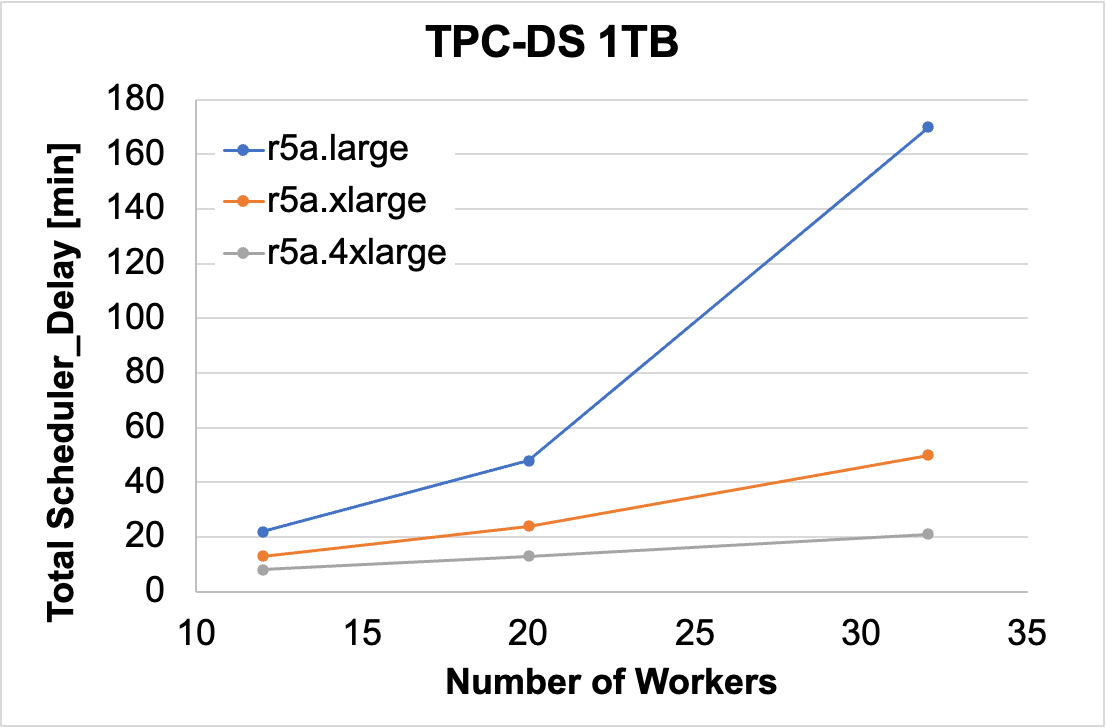
In the graph below, we plot the total aggregated scheduler delays of all tasks for each of the job configurations vs the number of workers. It is expected that the aggregated scheduler delay should increase for a larger number of workers since there are more tasks. For example, if there are 100 tasks, each with 1s of scheduler delay, the total aggregated scheduler day is 100s (even if all 100 tasks executed in parallel and the “wall clock” scheduler delay is only 1s). Therefore, if there are 1000 tasks, the total aggregated scheduler should increase as well.
Theoretically this should scale roughly linearly with the number of workers for a “healthy” system. For the “middle” and “large” sized drivers (r5a.xlarge and r5a.4xlarge respectively), we see the expected growth of the scheduler delay. However, for the “small” r5a.large driver, we see a very non-linear growth of the total aggregated scheduler delay, which contributes to the overall longer job runtime. This appears to be a large contributor to the “small driver bottleneck” issue.
To understand a bit deeper as to what is the formal definition of Scheduler Delay, let’s look at the Spark source code inside the function AppStatusUtils.scala. At a high level, scheduler delay is a simple calculation as shown in the code below:
schedulerDelay = duration – runTime – deserializeTime – serlializeTime – gettingResultTime
To put it in normal text, scheduler delay is basically a catch-all term, that is the time the task is spent doing something that is not executing, serializing data, or getting results. A further question would be to see which one of these terms is increasing or decreasing due to the smaller driver? Maybe duration is increasing, or maybe gettingResultTime is decreasing?
If we look at the apples to apples case of 32 workers for the “medium” r5a.xlarge driver and the “small” r5a.large driver, the runtime of the “small” driver was significantly longer. One could hypothesize that the average duration per task is longer (vs. one of the other terms becoming smaller).
In summary, our hypothesis here is that by reducing the driver size (number of VCPUs and memory), we are incurring an additional time “tax” on each task by taking, on average, slightly longer to ship a task from the scheduler on the driver to each executor.
A simple analogy here is, imagine you’re sitting in bumper to bumper traffic on a highway, and then all of a sudden every car (a task in Spark) just grew 20% longer, if there are enough cars you could be set back miles.
Conclusion
Based on the data described above, the answer to the question above is that inappropriately sized drivers can lead to excess cost and performance as workers scale up and down. We present a hypothesis that a driver that is “too small” with too few VCPUs and memory, could cause, on average, an increase in the task duration via an additional overhead in the scheduler delay.
This final conclusion is not terribly new to those familiar with Spark, but we hope seeing actual data can help create a quantitative understanding on the impact of driver sizing. There are of course many other things that could cause a poor driver to elongate or even crash a job, (as described earlier via the OOM errors). This analysis was just a deep dive into one observation.
I’d like to put a large caveat here that this analysis was specific to the TPC-DS workload, and it would be difficult to generalize these findings across all workloads. Although the TPC-DS benchmark is a collection of very common SQL queries, in reality individual code, or things like user defined functions, could throw these conclusions out the window. The only way to know for sure about your workloads is to run some driver sizing experiments.
As we’ve mentioned many times before, distributed computing is complicated, and optimizing your cluster for your job needs to be done on an individual basis. Which is why we built the Apache Spark Autotuner for EMR and Databricks on AWS to help data engineers quickly find the answers they are looking for.