How Abnormal Security Reduced Databricks Costs by 38% with Gradient

In this blog we explore a real user experience using Gradient to manage and optimize their Databricks production job.

Who is Abnormal Security?
Abnormal Security, aka Abnormal, is a hypergrowth company in the email security space that helps companies worldwide prevent email attacks while automating security operations. They rely on Databricks extensively to help process terabytes of data across thousands of jobs daily, translating to an enormous amount of daily Databricks usage. From ETL jobs, streaming, SQL, to machine learning – it’s safe to say that Abnormal has a diverse set of applications run on Databricks.
Abnormal’s Problem with Databricks
Abnormal’s data platform team came to Sync with a common problem — they simply had too many jobs for a platform team to control in terms of cost, efficiency, and runtime SLAs, all while operating at scale. This problem wasn’t getting easier with their business growing each month – the number of jobs to manage was only increasing.
To put some numbers behind the scale of the problem, let’s say each Databricks cluster can have 10 options to configure. That times a thousand is 10,000 parameters each day that need to be monitored and optimized. Keep in mind, many things can change as well from data size to new code being pushed – so a configuration that worked yesterday can be wrong today.
And to make the problem harder, a bad configuration can lead to an out of memory error and result in a crashed production job. Making a mistake with a configuration is no joke, and that’s why many teams are hesitant to try and optimize themselves.
The Abnormal team was looking for a solution that could manage and optimize many of their production jobs automatically and at scale without any crashes. In some sense, they wanted a tool that would allow their small platform team to seem like an army capable of successfully managing thousands of jobs at once with high fidelity.
How Gradient Helped
Abnormal’s use case is one we’ve heard many times, and one that really strikes at the true value of what Gradient can do – automatically manage and optimize Databricks jobs at scale. With Gradient, a single person can potentially manage thousands of jobs, without breaking a sweat.
How Gradient Works
Gradient builds a custom model for each job it manages, and trains its model on historical data, keeping track of any statistical variations that may occur. With this information, Gradient can confidently apply changes to a user’s cluster automatically to steer it towards the desired performance, learning with each iteration.
Gradient’s model provides the ultimate infrastructure management solution with the following value points relevant for Abnormal:
- Automatically maintains optimal performance – Gradient continuously monitors your jobs and configurations to ensure mathematically optimal performance despite any variations that may occur with no code changes.
- Lowers costs – Gradient can tune clusters at scale to hit minimize costs
- Hit SLAs – Gradient can tune clusters to ensure runtime SLAs are hit
- Offloads maintenance work – Monitoring and tuning clusters can now be automated away, saving precious time for data and platform engineers
- Beyond serverless – Similar to the value of Serverless clusters, Gradient removes all infrastructure decision making away from end users. The one major step forward Gradient performs is it will actively optimize the configurations to hit end user goals – white still leaving everything exposed for users to observe and control if they want.
Automatic Results in Production – “Set and Forget”
An hourly production job with a runtime of about 60 minutes was selected to import into the Gradient system. Integrating Gradient into Abnormals production Airflow environment took under an hour for the one-time installation setup. After the installation, adding new jobs is as simple as clicking a few buttons in the Gradient UI.
After importing the job into Gradient, Abnormal simply enabled “auto-apply” and then walked away. A couple hours later they logged back into Gradient and saw the results below – a 38% cost savings and a 2x speedup of their jobs in production without lifting a finger.
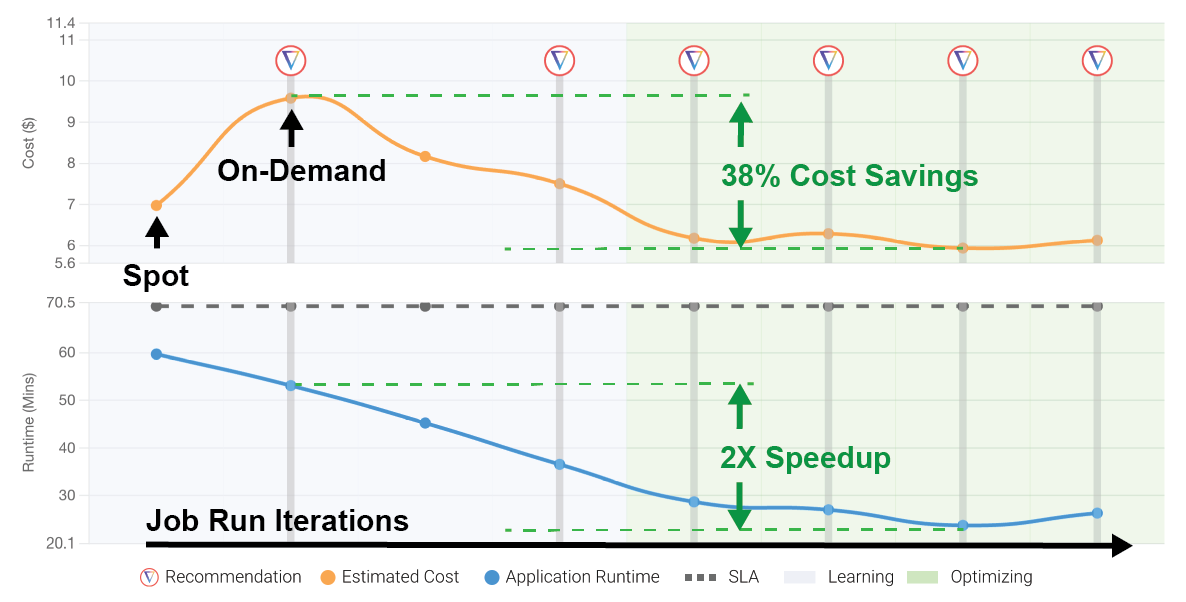
Analyzing the Results
The image above shows an annotated screenshot from Abnormal’s Gradient dashboard for the job. The top graph shows the cost as a function of job run iteration. Each vertical line with a Gradient logo illustrates when a cluster recommendation was applied in production.
The gray area represents the “training” phase of the process while the green area represents the “optimizing” phase. The bottom graph shows the runtime of the application across iterations.
While Abnormal normally runs their job on Spot instances, for this case we switched it to an on-demand cluster to help mitigate any cluster performance noise that could be attributed to the randomness of spot clusters. Basically, it helps to keep the test clean to ensure any performance enhancements we achieve weren’t caused by other random fluctuations. Otherise, the clusters were identical. After optimization, the cluster can be switched back to Spot, where the savings will transfer directly.
In the above cost graph, once the cluster switches to on-demand, the training and optimizing begins. The starting cluster consisted of a r5.xlarge driver node and 10 c5.4xlarge worker nodes. Gradient, under the hood, optimized both cluster and EBS settings.
What Gradient found in this particular example was that this job was under-provisioned and actually needed a larger cluster that resulted in both a 38% cost savings and a 2X speedup. This result can be counter-intuitive as most people may think cost and runtime savings can only occur when a cluster is over-provisioned and simply shrinking a cluster is the obvious way to cut costs.
Towards the end of the image above, you’ll notice that Gradient will manage the cluster and keep it at optimal performance, with no human intervention needed. Even if things change, Gradient will be able to adjust and accommodate.
Was the reduction due to decreasing data sizes?
One question Abnormal had immediately was, maybe this cost reduction was due to a decreasing data size – a completely valid thought. We of course want to ensure that the performance enhancements observed were due to our optimizations and not some external factor.
Fortunately, when we analyzed the input data size during these job runs, they were all consistent across job runs. Proving that this performance boost was due to Gradient’s actions.
How did Gradient know what to do?
As mentioned earlier, Gradient uses a proprietary mathematical model of Databricks. With a few training points, the system can fit model coefficients to quickly provide an accurate prediction of which way to tune a cluster. The best part is, with each new iteration data point, the model only gets more accurate over time.
In this particular scenario, the data was informing the model that it was indeed an under-provisioned cluster and that increasing the size was the right path.
To ensure job run safety, Gradient will gradually walk clusters towards optimal configurations – monitoring the effects of the change with each iteration. This is an important step to prevent catastrophic failures. Changing a cluster too drastically in a single shot is a high risk maneuver due to the unpredictability of Spark jobs.
So what did Abnormal think?
“Gradient is indispensable in our data-driven landscape, where the ever-expanding data volumes require constant monitoring and optimizations. Without Gradient, these oversights can lead to expensive errors, system failures, or excessive costs. With its automated optimization of distributed Spark jobs and scalable solutions, Gradient guarantees seamless pipeline operation, enabling us to focus on delivering products and features to our customers.” – Blaine Elliot – Platform Engineer @Abnormal
Try it yourself today
Gradient is available to try today for users on Databricks AWS and Azure. With each passing month, we’re releasing new features and new optimization paths. If you want help managing and optimizing your Databricks clusters, request a demo or see our site for more information.
 Kartik Nagappa
Kartik Nagappa
 Noa Shavit
Noa Shavit