
Save up to 50% on compute!
Save on compute while meeting runtime SLAs with Gradient’s AI compute optimization solution.

The global data landscape is experiencing remarkable growth, with unprecedented increases in data generation and substantial investments in analytics and infrastructure. According to data from sources like Network World and, G2 the global datasphere is projected to expand from 33 zettabytes in 2018 to an astounding 175 zettabytes by 2025, reflecting a compound annual growth rate (CAGR) of 61%.

As the volume of data continues to grow, so does the need for specialized skills to effectively manage it. This brings us to today’s topic: exploring strategies to manage your organization’s data infrastructure in the most efficient and cost-efficient way possible.
In today’s landscape, big data, which is data too large to fit into a single node machine, is transformed and managed by clusters. But what are clusters?
In Databricks, clusters are groups of virtual computers that work together to process and analyze big data. Think of them as a team of workers who divide the tasks among themselves to get the job done faster and more efficiently.
Read more on Databricks cluster types.

On a more granular level, an Amazon Elastic Compute Cloud (EC2) instance is a single unit of computing power that is used to address a single virtual machine. Clusters are made up of many EC2 Instances, which consist of driver nodes and worker nodes.
Databricks clusters contain one driver node and one or more worker nodes. Clusters can scale up or down by adding or removing worker nodes, depending on the workload. For example, when processing a large dataset, you can add more EC2 worker nodes to speed up the task. Once the workload is finished, you can scale down to save costs.
Clusters offer the flexibility to select different types of EC2 instances tailored to your specific needs. You can choose from a wide range of options based on factors like computing power, memory, storage, and more. These choices play a crucial role in optimizing performance and cost efficiency for your workloads.
Databricks offers Job clusters for data pipeline processing and warehouse clusters used for the SQL lakehouse. Job clusters have far more sizing options. This post focuses on optimizing job clusters using EC2 instances for Databricks workloads.
In Databricks, you can choose between two cluster types to suit your workload needs. The Databricks Classic cluster allows you to manually configure and provision resources, offering full control over the setup. Alternatively, the Databricks Serverless Compute is a cluster type that simplifies this process by automatically configuring and managing resources for you—though it comes at a premium cost.
Serverless clusters are ideal for lightweight, quick tasks, while Classic clusters are better suited for handling large-scale jobs involving substantial amounts of data. In this post, we focus on the use of Classic clusters for managing and optimizing heavy data workloads effectively.
Read our comprehensive comparison of Databricks serverless vs. classic.
When using Amazon EC2, understanding the cost structure is crucial to managing and optimizing your cloud expenses effectively. The costs can often be underestimated, but as your data scales, these expenses can grow unexpectedly, potentially reaching surprising levels without you knowing.
Amazon EC2 offers a wide variety of instance types tailored to different workloads, each providing unique benefits that influence performance and cost. The instance type you choose can significantly affect your cloud expenses based on your workload’s requirements.
Here are a few examples of instance types:
Related: EMR Graviton and whether Graviton instances lower costs for Spark on AWS
AWS operates in multiple geographic regions worldwide, and each region has its own pricing based on demand, infrastructure costs, and operational expenses. For example, instances in North America may be less expensive than those in Asia-Pacific regions. Within each region, there are multiple availability zones to ensure high availability.
In the table below you can see the average hourly rate for common instance types (e.g. I4I) by region. For a full breakdown of EC2 pricing, go here.
| Region name | Region code | Average price/hour (USD) |
| US West (Oregon) | us-west-2 | $0.241 |
| US East (N. Virginia) | us-east-1 | $0.241 |
| US East (Ohio) | us-east-2 | $0.241 |
| Asia Pacific (Mumbai) | ap-south-1 | $0.247 |
| Europe (Ireland) | eu-west-1 | $0.252 |
| Canada (Central) | ca-central-1 | $0.256 |
| Europe (London) | eu-west-2 | $0.260 |
| Asia Pacific (Singapore) | ap-southeast-1 | $0.267 |
| Europe (Frankfurt) | eu-central-1 | $0.267 |
| Asia Pacific (Tokyo) | ap-northeast-1 | $0.271 |
| Asia Pacific (Sydney) | ap-southeast-2 | $0.272 |
| South America (São Paulo) | sa-east-1 | $0.325 |
While you can see substantial differences in rates by region in the table above, optimizing cost is not as straightforward as choosing the lowest-priced region. Data transfers between regions or zones incur additional costs that can outweigh the cost savings, not to mention the impact on performance. Provisioning EC2 instances in the same region as your data is not only important from a cost perspective, it also reduces access latency and increases transfer speed.
Understanding regional, zone, and data transfer pricing differences is key to optimizing your expenses, especially for globally distributed applications.
Save on compute while meeting runtime SLAs with Gradient’s AI compute optimization solution.
Amazon EC2 provides several key storage options tailored to different workload needs:
The first three storage options come with the EC2 instance naturally, while the latter options are an external Amazon Service you can integrate with. These options offer flexibility and scalability, allowing you to base your decisions on factors like persistence and latency.
Amazon EC2 offers three primary pricing models for their instances – On-Demand, Spot and Reserved – each suited to different workloads, budgets, and operational needs.
| Feature | On-Demand Instances | Spot Instances | Reserved Instances |
| Pricing | Fixed, highest cost | Dynamic, up to 90% cheaper | Discounted, up to 75% off |
| Commitment | None | None | 1 or 3 years |
| Availability | Guaranteed if capacity exists | Not guaranteed; interruptions | Guaranteed for the reserved term |
| Flexibility | High | High | Low |
| Workload Tolerance | Production workloads and other non-interruptible workloads | Fault-tolerant workloads | Extremely predictable workloads |
| Best Use Case | Short-term, critical workloads | Cost-sensitive, flexible tasks | Long-term, extremely predictable tasks |

After exploring the various factors that influence EC2 costs, here are some practical strategies to help you save money.
Choosing the right instance type for the right job is like selecting the perfect tool for a task—it can help increase efficiency, optimizes costs, and unlocks the full potential of your workload.
Start by analyzing the nature of your workloads:
For example, for Spark jobs without complex transformations we recommend using a high-memory cluster where the entire dataset can fit comfortably within the total memory provisioned. In such scenarios, R7g instances are an excellent choice, offering high memory capacity and optimal performance for memory-intensive tasks. There is no one-size-fits-all solution; you’ll need to evaluate your needs and choose instances accordingly.
Similarly, choosing the right EC2 instance pricing model can help optimize AWS EC2 for costs. Doing a little bit of groundwork by evaluating your workflow requirements and matching that against a suitable pricing model will always have a positive return.
Here are a couple insights about each model:
Save on compute while meeting runtime SLAs with Gradient’s AI compute optimization solution.
Depending on the maturity of your data and organization, some companies may require all three pricing models for different workflows. This is to ensure resources are not over or under-utilized.
Databricks and AWS EC2 support autoscaling policies, which define rules for automatically increasing or decreasing the number of nodes in a cluster. These policies help control usage costs, set resource limits, and scale up or down based on workload demands. Autoscaling is particularly useful for experienced engineers managing dynamic workloads.
Example of a scaling policy:
In this example, the policy adds nodes when the cluster’s memory usage exceeds the defined threshold, indicating high resource demand. Conversely, it removes nodes when no workloads are running.
It should be noted that autoscaling is not one-size-fits-all. Autoscaling might be a perfect fit for your workloads—or it might not. The truth is, the answer often depends on your specific needs. The only way to know for sure is to dive in and experiment.
Related: Is Databricks autoscaling cost efficient? Find out in this Databricks autoscaling on the TPC-DS benchmark report.
EC2 comes with a plethora of storage options, and all of them cater to a different use case. Choosing the right storage type for your workload can significantly optimize costs and ensure efficient performance.
For persistent storage, we recommend S3 as a long term storage solution. It is rich with features revolving around balancing transfer latencies and costs while offering scalability and durability to store large volumes of data. In addition, EC2 images are often stored on S3.
S3’s tiered storage classes, including Standard, Infrequent Access, and Glacier, allow you to optimize costs based on how frequently data is accessed, making it an excellent choice for backups, archives, and data lakes that require reliable, long-term storage with flexible pricing options.
For local storage on your machine, EBS storage options typically offer the best value for most use cases. Unless you require ultra-fast transfer speeds, EBS provides sufficient performance at a much lower cost compared to NVMe SSDs
Only utilize NVMe SSDs for ultra-fast workloads that require ephemeral storage with low latency and high throughput, while directly attached to the instance. Caching is the most common use-case for SSDs as they are one of the most expensive options in this list. The data is also lost when the EC2 instance stops, rendering the usage for persistent data redundant.
When selecting the right storage, the location of your resources is a critical consideration. Data transfer costs between regions and availability zones can add up, making it essential to plan where your data resides in advance to minimize inter-zone transfer expenses. Additionally, it’s wise to account for the location of your existing resources, whether on-premises or in the cloud, to ensure seamless integration and cost efficiency when deploying EC2 instances.
Thoughtful planning can significantly reduce unnecessary data transfer costs and improve overall resource management. For reference, the transfer cost between EC2 instance regions is currently about $0.09 per GB.
| Storage Type | Pros | Cons |
| EBS (Elastic Block Store) | – Cost-effective for most use cases- Sufficient performance for general workloads | – Not suitable for ultra-fast workloads- Higher latency compared to NVMe SSD |
| NVMe SSD | – Ultra-fast speeds- Low latency and high throughput- Ideal for ephemeral workloads like caching | – Expensive- Data is lost when the EC2 instance stops- Not suitable for persistent storage |
| S3 (Simple Storage Service) | – Scalable and durable- Cost-optimized tiered storage classes (Standard, Infrequent Access, Glacier)- Ideal for long-term storage of large volumes of data | – Not suitable for workloads requiring ultra-fast storage |
As the saying goes:
“Knowledge comes from learning, but wisdom comes from doing.”
You won’t fully understand the exact requirements of your workflows until they’ve been deployed and observed in action. Monitoring helps you identify inefficiencies and optimize resource usage. For instance, it’s not uncommon to find data pipelines using only 5% of the allocated SSD storage for extended periods—wasting valuable resources and increasing costs.
To effectively manage your resources, use tools like:
Additionally, take advantage of free offerings from cloud providers, especially if you’re a small business owner. For example, AWS provides a free EC2 instance (t2.micro) for new accounts as part of its free tier, as well as substantial credits for startups. Use these freebies for experimentation, testing, or ad-hoc workloads, helping you save money while exploring new solutions.
By continuously monitoring and leveraging available resources wisely, you can significantly reduce unnecessary costs and improve overall efficiency.
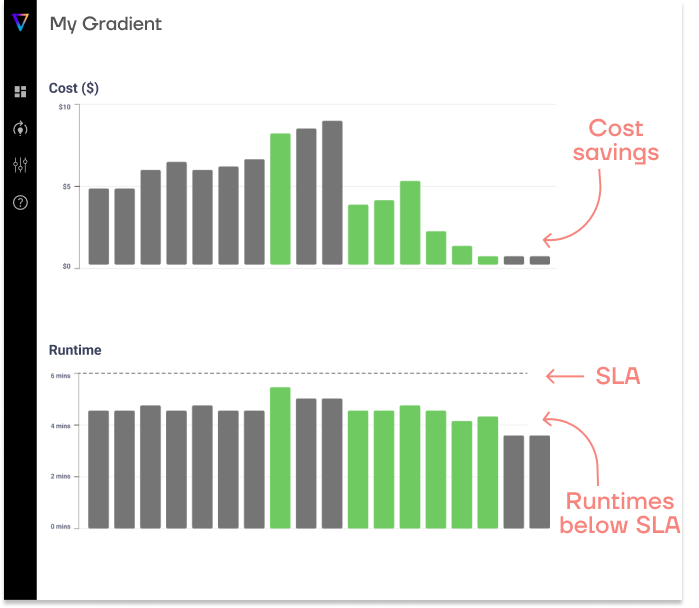
We, at Sync, believe that engineers shouldn’t waste time running and testing their workloads on various configurations. They should be spending their time building, while we automate the optimization of resources.
Our AI agent, Gradient, integrates seamlessly with your Databricks workspace, collects logs, and analyzes jobs using advanced machine learning algorithms. It is then able to make changes to your configurations (like node count, instance type) instantly and evaluate the impact of those changes continuously. This closed-loop feedback system is what ensures the models continue to improve with each run.
By using Gradient, data engineers at enterprise organizations have reported cost savings up to 50% on their compute bill, not to mention hundreds of engineering hours saved. In fact, a senior data engineer with experience at Disney, Meta, and Nielsen used Gradient to optimize his Spark jobs. Gradient was able to save his company over $100k on AWS a year!
Read this user’s blog post: User Perspective — How Sync Computing Can Optimize Cloud Spend
We hope this article has shed some light on optimizing the costs of EC2 in Databricks. Here’s a quick recap:
Optimizing resource management is a long-term commitment, and we’re here to support you on this journey.
Click here to schedule a free 30-min consultation into your Databricks ecosystem.
Save on compute while meeting runtime SLAs with Gradient’s AI compute optimization solution.
 Kartik Nagappa
Kartik Nagappa