
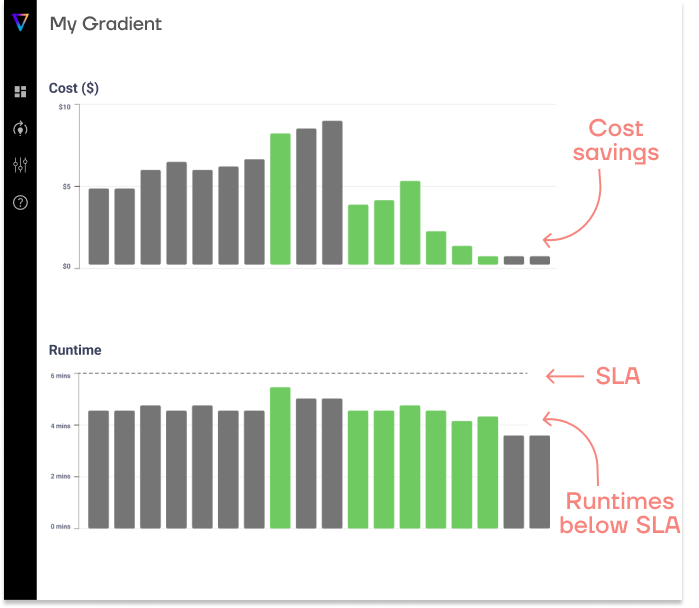
Save up to 50% on compute!
Save on compute while meeting runtime SLAs with Gradient’s AI compute optimization solution.
Data is central to modern business and society. Depending on what sort of leaky analogy you prefer, data can be the new oil, gold, or even electricity. Of course, even the biggest data sets are worthless, and might even be a liability, if they aren’t organized properly.
Data collected from every corner of modern society has transformed the way people live and do business. Everything from the subtleties of internal corporate transactions to the habits of everyday life can be measured, stored and analyzed. You’d be hard-pressed to find a modern business that does not rely on data-driven insights.
The ability to collect, analyze, and utilize data has revolutionized the way businesses operate and interact with their customers in various industries, such as healthcare, finance, and retail. Other industries are natively intertwined with data, like those stemming from mobile devices, internet-of-things, and modern machine learning and AI.
Estimates vary, but the amount of new data produced, recorded, and stored is in the ballpark of 200 exabytes per day on average, with an annual total growing from 33 zettabytes in 2018 to a projected 169 zettabytes in 2025. In case you don’t know your metrics, these numbers are astronomical! 100 zettabytes is 1014 gigabytes, or 10 to 100 times more than the estimated number of stars in the Local Group of galaxies, which includes our Milky Way.
The value of data has been apparent for as long as people have been writing things down. One of the earliest examples of writing, a clay tablet, is likely a record of transactions. Stonehenge and other megaliths can be interpreted as resilient data stores for analyzing solar position to predict seasonal conditions.
As the magnitude and role of data in society has changed, so have the tools for dealing with it. While a +3500 year data retention capability for data stored on clay tablets is impressive, the access latency and forward compatibility of clay tablets fall a little short.
Similarly, data platforms based on the business needs of the past don’t always meet the needs of today. Data volume and velocity, governance, structure, and regulatory requirements have all evolved and continue to. Despite these limitations, data warehouses, introduced in the late 1980s based on ideas developed even earlier, remain in widespread use today for certain business intelligence and data analysis applications.
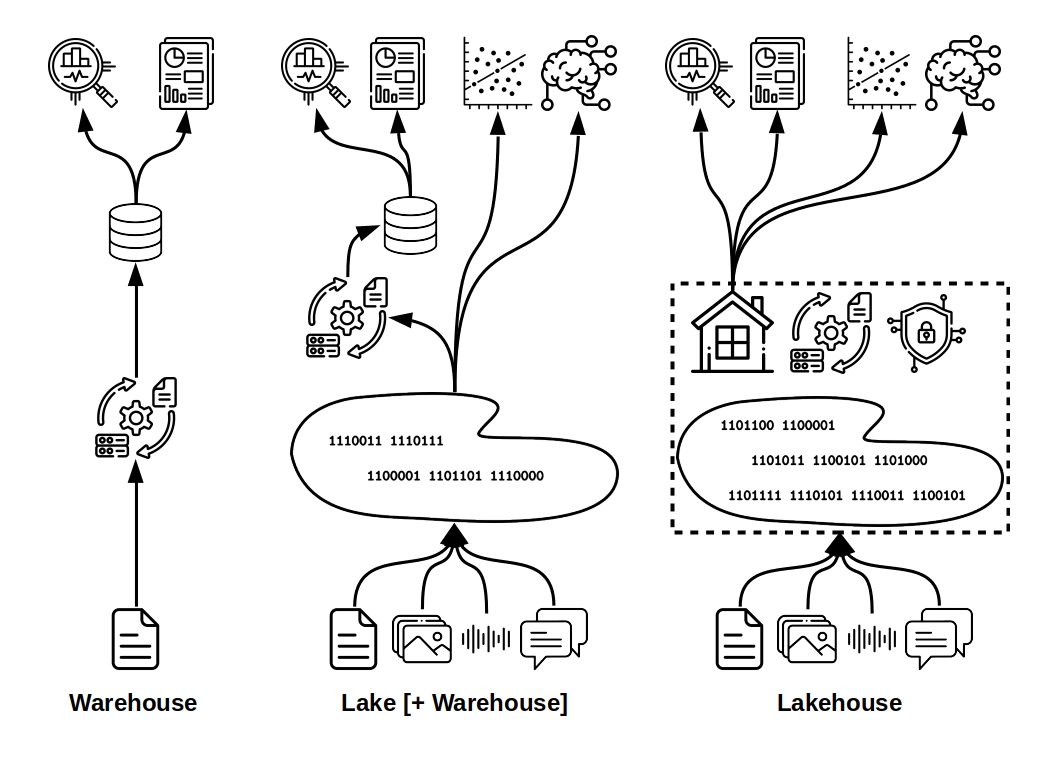
While data warehouses are still in use, they are limited in use-cases as they only support structured data. Data lakes add support for semi-structured and unstructured data, and data lakehouses add further flexibility with better governance in a true hybrid solution built from the ground-up. Read on for a detailed comparison of the pros and cons of data warehouses, data lakes, and data lakehouses.
Save on compute while meeting runtime SLAs with Gradient’s AI compute optimization solution.
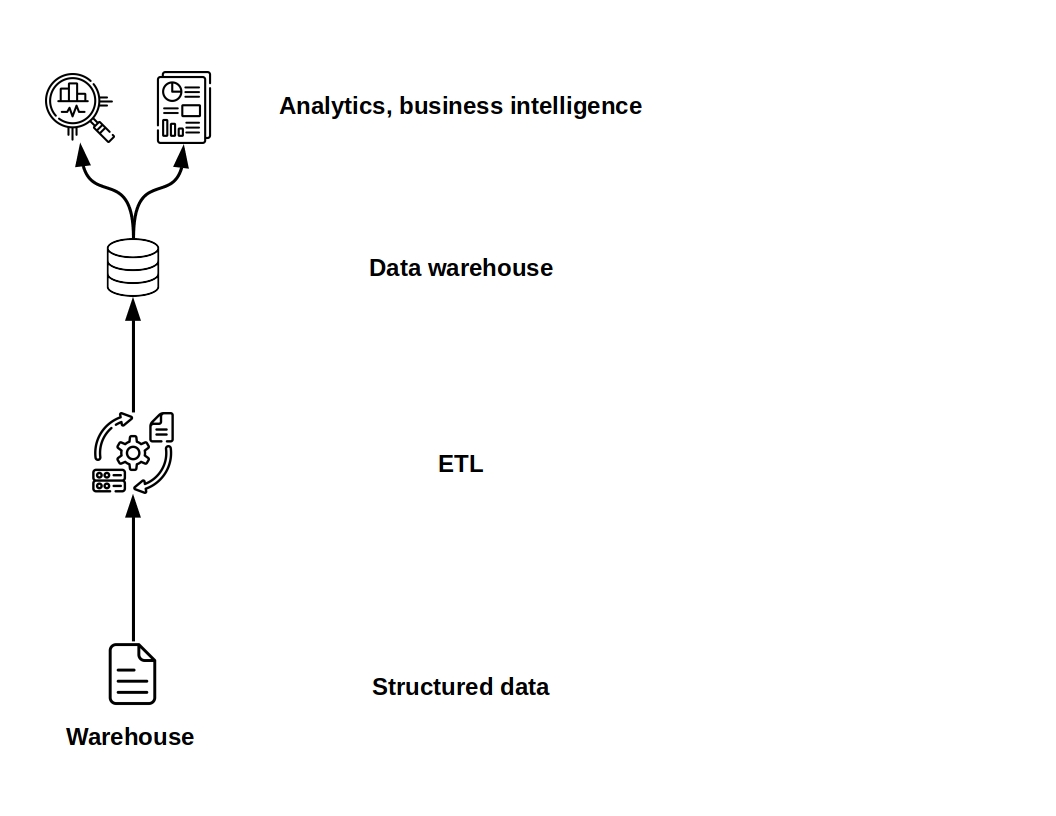
A data warehouse is a repository and platform for storing, querying, and manipulating data. Warehouses are particularly suited for structured data used for decision support and business intelligence. Modern data warehouses have become more efficient, flexible, and scalable (particularly in the context of massively parallel processing and distributed computation), but they still bear the mark of their early development in the previous century.
The data warehouse concept dates back to data marts in the 1970s. After a long incubation period, the idea began to bear fruit commercially at IBM in the late 1980s and early 1990s. Data warehousing improved on the inefficiency of data marts, siloed data stores maintained by individual departments.
Data warehouses have come a long way since then, offered by tech giants (Google BigQuery, Amazon Redshift, Microsoft Synapse), well known specialists like Yellowbrick, Teradata, and Snowflake, and modern projects like DuckDB.
Read our comparison of Snowflake, Databricks, and DuckDB
In line with their original use case, data warehouses are by and large more closed than modern data platforms, like Databricks or Snowflake. They use proprietary data formats, more rigidly enforced schema, and have strict governance.
Compared to a data lake or lakehouse, a data warehouse tends to have a shorter learning curve and is usually easier for end users with less specialized technical knowledge. With that said, these systems tend to be less flexible and lack operational transparency.
Mobile devices, cloud computing, and the internet of things have significantly accelerated growth in data volume and velocity in recent years. The growing role of big data and associated technologies, like Hadoop and Spark, have nudged the industry away from its legacy origins and toward cloud data warehousing.
Modern data warehouses benefit from decades of continuous improvement for their most suitable use cases in structured analytics and decision support, and they are more flexible and capable than their predecessors. The evolution of data warehouses was motivated by a mix of a need to match capabilities of newer platforms, like data lakes, and evolving data needs, such as governance and security.
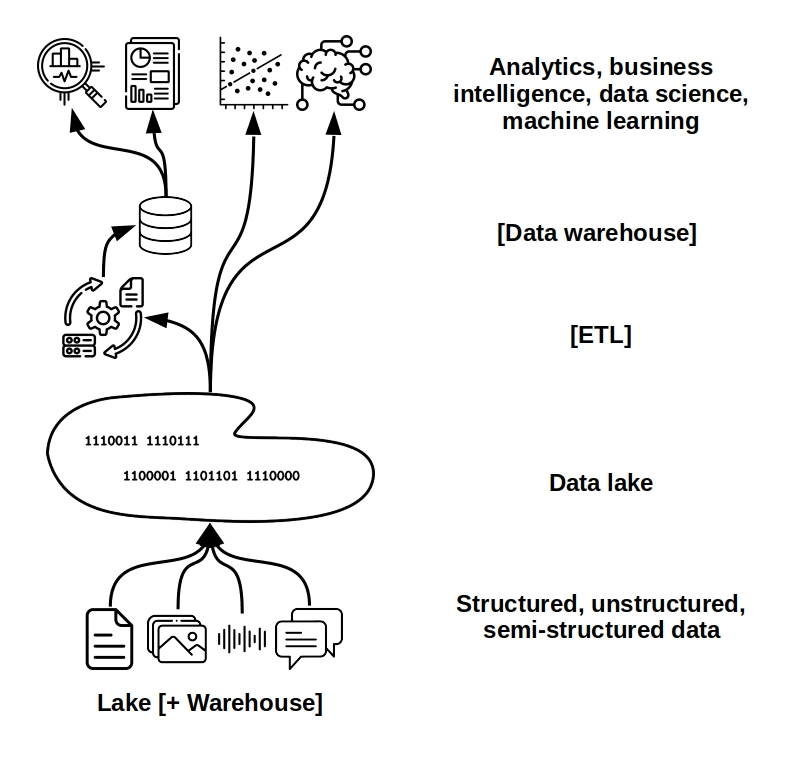
For data science and deep machine learning, data lakes offer a more flexible alternative to traditional data warehouse platforms. Where data warehouses organize primarily structured data in rigid schema with often proprietary data formats, data lakes have been developed for flexible native support of ever-growing volumes of unstructured and semi-structured data.
Like data warehouses, commercial data lake offerings are integrated into the major clouds: Google’s BigLake, Microsoft’s Azure Data Lake, and Amazon’s S3 Data Lakes. Unlike traditional data warehouses, data lakes are typically built on open source tools and frameworks like Delta Lake and Apache Hudi.
A few big tech companies have the in-house expertise to customize their own data lakes. Examples include a sophisticated hybrid approach with incremental ETL developed at Uber and a complex hybrid infrastructure for data lake and warehouse needs built by Netflix.
While a data warehouse requires ETL (extract, transform, load) on data going into storage, ensuring it is structured for fast querying and use in analytics and business intelligence. In a data lake raw data can be stored and accessed directly. ETL is then applied as a separate step either on-demand (lowering performance) or on its way into a data warehouse in a hybrid, multi-platform architecture (increasing complexity).
Data lakes trade the query performance and shorter learning curves of data warehouses for increased flexibility and support for semistructured and unstructured data. The use of open data formats in data lakes means more flexibility for users and less vendor lock-in.
This flexibility also enables data lakes to be more efficient than data warehouses. For example, a data lake can take advantage of a cloud provider’s spot instances to save cost versus on-demand clusters. This can translate into substantial cost savings, as we have found that spot instances can be 90% cheaper than on-demand clusters. Data lakes can also separate storage and on-demand compute costs, whereas warehouses tend to bundle everything together.
On the other hand, a data lake that is poorly optimized can actually be more expensive. Retaining in-house expertise to maintain and optimize a data lake is also a cost that requires consideration. Ultimately the limits of cost and efficiency depend on the particulars of each use case.
Overall, data warehouses date to an era of more rigid and structured data needs, but are still useful for structured data, relational queries, and business analytics. Data lakes are flexible enough to support today’s deep learning and data science, but fall short in infrastructure, governance, and relational analytics. So, why not combine the two to get the best of both worlds?
Some companies have attempted creating their own hybrid architectures that couple a data lake with one or more warehouses, but this entails its own challenges. This approach can be perfectly viable for an organization that wants to modernize slowly, without switching over to a fully modern data platform. But what kind of characteristics would a true hybrid solution, built from the ground up based on today’s needs, have?
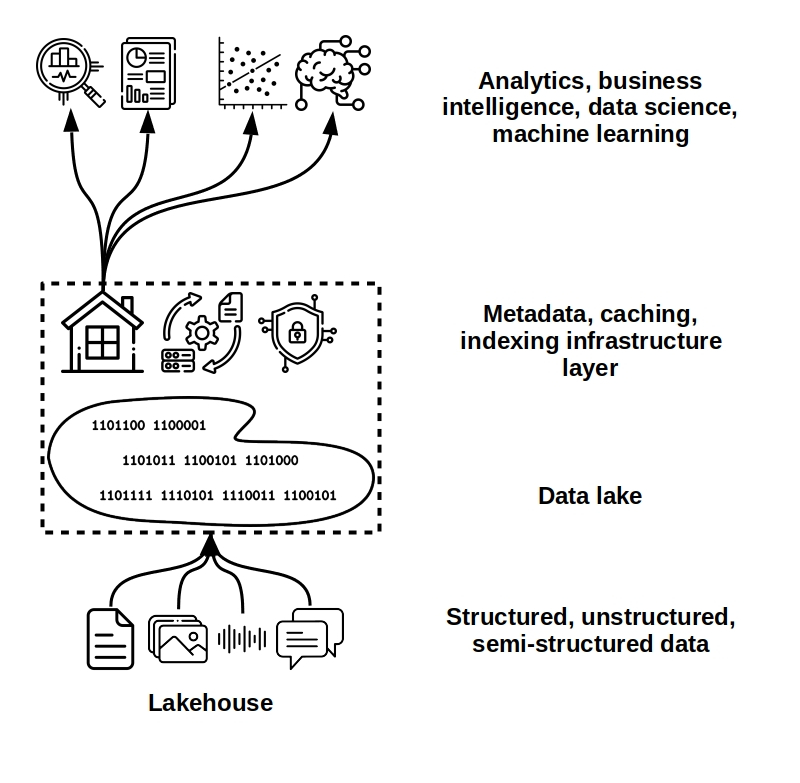
A data lake leaves something to be desired in terms of data governance and infrastructure. Without proper infrastructure and governance, a well intentioned data lake quickly turns into a data “swamp” and “swamps start to smell after a while,” according to the father of the lakehouse, Bill Inmon, in Building the Data Lakehouse.
The data lakehouse concept shares the goals of hybrid architectures, but is designed from the ground up to meet modern needs. Lakehouses maintain the flexibility of a data lake but incorporate an infrastructure layer that adds metadata and indexing, improves governance and ETL, and improves support for traditional queries and relational analytics. Databricks leads the field in lakehouse development and advocacy, and introduced the concept in this 2020 whitepaper.
Unlike a data warehouse, a data lakehouse supports semistructured and unstructured data, and uses open source data formats to eliminate the possibility of vendor lock-in. The lakehouse also works more naturally with Python and R, and provides support for continuous ETL and schema for keeping structured data fresh, enabling business intelligence dashboards and relational queries with languages like SQL. Lastly, the open data formats used by lakehouses reduce the risk of vendor lock-in.
In contrast to the data lake, a lakehouse supports ACID (atomicity, consistency, isolation, and durability) transactions, so the side effects from multiple users accessing and analyzing data simultaneously are avoided. In addition, a lakehouse has improved data versioning, making it possible to follow data lineages from ingestion through transformation and analysis, making for better reliability and trustworthiness.
Infrastructure and governance capabilities of a lakehouse make it easier to stay in compliance with regulations like the Health Insurance Portability and Accountability Act (HIPAA), the California Consumer Privacy Act (CCPA), the EU’s General Data Protection Regulation (GDPR), etc.
Optimize Databricks clusters for cost and performance
| Data Warehouse | Data Lake | Data Lakehouse | |
| Structured data | ✔️ | ✔️ | ✔️ |
| Semi-structured data | ❌ | ✔️ | ✔️ |
| Unstructured data | ❌ | ✔️ | ✔️ |
| Open source foundation? | Proprietary* | Open source | Open source |
| Learning curve | 🧠 | 🧠🧠🧠 | 🧠🧠 |
| Languages supported | Query languages like SQL | Programing languages like Python, R, and Scala | SQL, Python, R, Scala & Java, Go, Etc. |
| Governance | Rigid schema, ACID transactions, ETL at data ingestion | Little enforced governance, post-hoc ETL, [hybrid architectures for data warehouse functionality ]** | Support for ACID transactions, data versioning, metadata/indexing, continuous ETL |
| Ideal use cases | Relational Analytics, Business Intelligence | Data Science, Machine Learning, [Business Intelligence, Relational Analytics]** | Relational Analytics, Business Intelligence, Data Science, Machine Learning and MLOps |
Developed in response to the growing data needs of last century’s businesses, the highly structured and proprietary origins of the data warehouses shows its age. However, data warehouses still offer top notch performance for traditional business intelligence and relational data analytics.
In addition, the learning curve for a data warehouse is typically shallow, and managed warehouse services relieve the end user of some of the technical aspects of data management. But this comes at the cost of flexibility.
Data lakes offer flexible support for modern data needs, open data formats, and the potential for reduced compute costs. But while data science and machine learning workflows are supported, more traditional data analytics, such as SQL queries and business reports, are supported poorly if at all.
Data lakes can be thought of as a less rigidly regulated data management strategy than data warehouses. Although access and application can be distributed, the data lake itself is still centralized. A decentralized alternative to a data lake, a data mesh, retains the strengths and weaknesses of a data lake in a distributed architecture.
DIY hybrid architectures attempt to bring the benefits of lakes and warehouses together, but at some expense of what each data platform is best at alone. A data lakehouse is a true hybrid solution built from the ground up. It retains the best aspects of data warehouses and lakes while incorporating lessons learned and responding to modern data needs. Performance for a lakehouse approaches that of a traditional warehouse for traditional analytics, while supporting direct data access needs of data science workflows and training machine learning models.
The data lakehouse is a powerful paradigm capable of meeting the data needs of the modern enterprise. It has been developed with a modern perspective and decades of accumulated data engineering wisdom. On the other hand, a data lakehouse might leave some aspects unfamiliar to users, and technical maintenance and optimization can be challenging.
For data teams that are already utilizing a data management platform, like Databricks, but are spending countless hours on cluster optimization, missing SLAs, and wasteful spending on compute consider Gradient, an AI cluster optimizations solution. Gradient empowers teams to leverage the full potential of Databricks, with ML-powered automated optimization.
Interested in learning more? Book a customized demo now!
 Kartik Nagappa
Kartik Nagappa