Everything You Need To Know About Azure Databricks Pricing 2024
Everything You Need To Know About Azure Databricks Pricing 2024
When trying to determine Databricks pricing, one of the most important aspects to consider is the cost of your cloud provider. This means one of three companies: Microsoft Azure, Amazon AWS, or Google Cloud. All three cloud service providers are extremely popular, and there’s no finite answer to which is best. Most companies choose one

Jeffrey Chou
05 Dec 2023
![]()
Blog
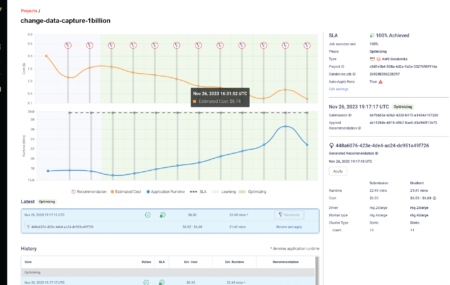
Gradient New Product Update Q4 2023
Gradient New Product Update Q4 2023
Today we are excited to announce our next major product update for Gradient to help companies optimize their Databricks Jobs clusters. This update isn’t just a simple UI upgrade… We upgraded everything from the inside out! Without burying the lead, here’s a screenshot of the new project page for Gradient above. Back in the last
Jeffrey Chou
27 Nov 2023

Blog, News
5 Lessons learned from testing Databricks SQL Serverless + DBT
5 Lessons learned from testing Databricks SQL Serverless + DBT
Databricks’ SQL warehouse products are a compelling offering for companies looking to streamline their production SQL queries. However, as usage scales up, the cost and performance of these systems become crucial to analyze. In this blog we take a technical deep dive into the cost and performance of their serverless SQL warehouse product by utilizing
Jeffrey Chou
17 Oct 2023

Blog, Case Study
What’s the difference between Databricks’s Overwatch and System Tables tools?
What’s the difference between Databricks’s Overwatch and System Tables tools?
Databricks recently released System Tables, to help users understand and monitor their usage. They also had the older and more skunk works project called Overwatch, which also provides usage and infrastructure information. So what’s the difference between the two? When should I use either one? Let’s dive in! Introduction Databricks as a whole is a
Jeffrey Chou
02 Oct 2023
![]()
Blog
The Easy and Comprehensive Guide To Understanding Databricks Pricing: How It Works and How To Reduce Your Cost
The Easy and Comprehensive Guide To Understanding Databricks Pricing: How It Works and How To Reduce Your Cost
Databricks is a popular unified analytics platform and a go-to solution for many organizations looking to harness the power of big data. Its collaborative workspaces have become the industry standard for data engineering and data science teams and an ideal environment for building, training and deploying machine learning and AI models at scale. However—as with
Jeffrey Chou
28 Sep 2023
![]()
Blog
New Gradient quick-start notebooks- Optimize your Databricks jobs in minutes
New Gradient quick-start notebooks- Optimize your Databricks jobs in minutes
Since we launched Gradient to help control and optimize Databricks Jobs, one piece of feedback from users was crystal clear to us: “It’s hard to set up” And we totally agreed. By nature, Gradient is a pretty deep infrastructure product that needs not only your Spark eventlogs but also cluster information from your cloud provider.

Pete Tamisin
22 Sep 2023
![]()
Blog