How it works
A look under the hood of Gradient:
The world’s first AI optimization
engine for your data infrastructure
High-performance computing
optimization engine
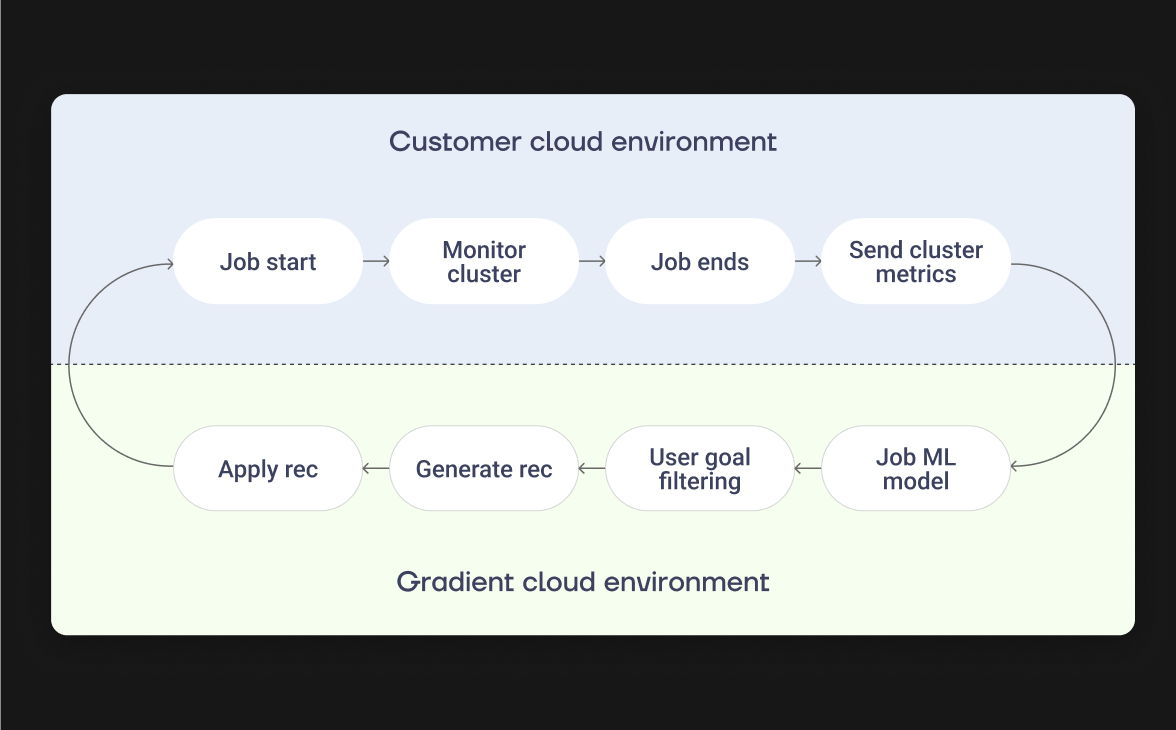
Gradient is an AI compute optimization engine that improves the costs and
runtimes of data pipelines in cloud environments
Data-driven modeling
Gradient pairs each job with a machine-learning model that is fine-tuned based on historical Spark event logs. The model uses that data to predict resource configurations, Spark metrics, and compute costs, taking into account factors like instance types, resource demands, and dependencies.
Statistical trends
Gradient’s core model is trained using statistical data about your jobs. This info is used to identify patterns and determine the optimal configuration to meet your desired cost, runtime, or SLAs hit rate. This is done even in the midst of noise such as data size variation, new code updates, or spot market.
Stability-minded
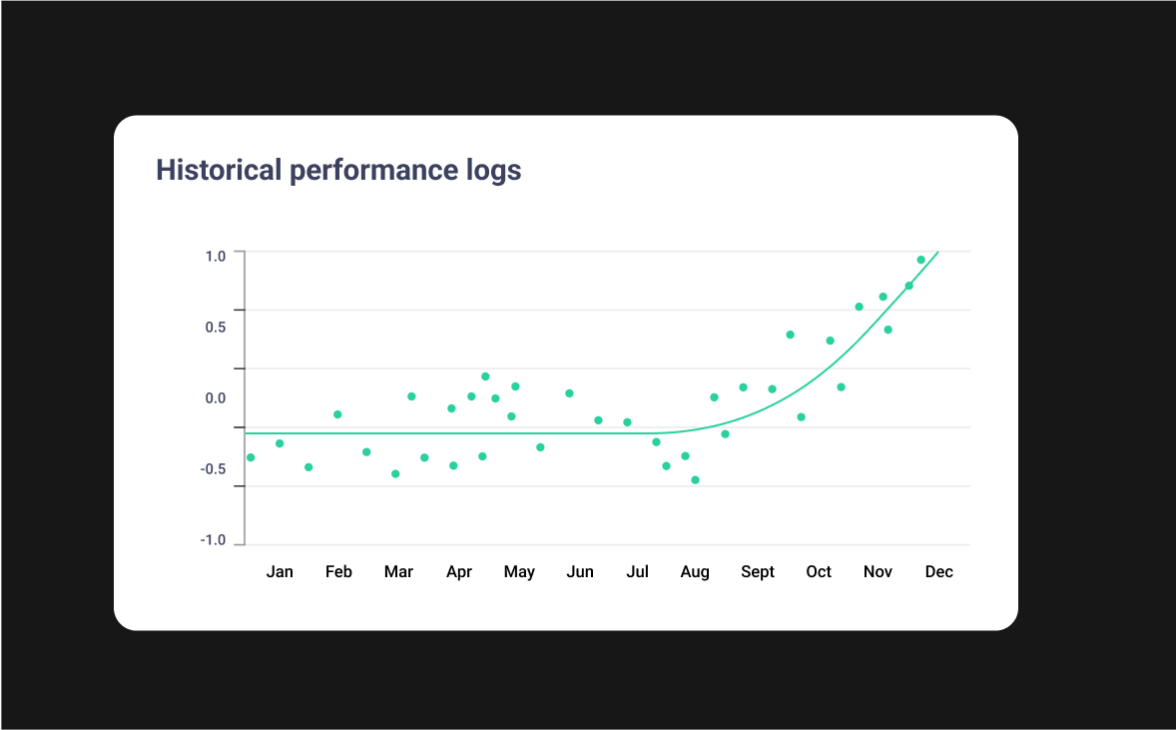
iterative optimization
Gradient takes an iterative approach to optimization to ensure successful runs. Recommending small changes at first, it gradually increases the scope of its recommendations based on the impact the previous optimizations have had on job cost and performance.
Job monitoring
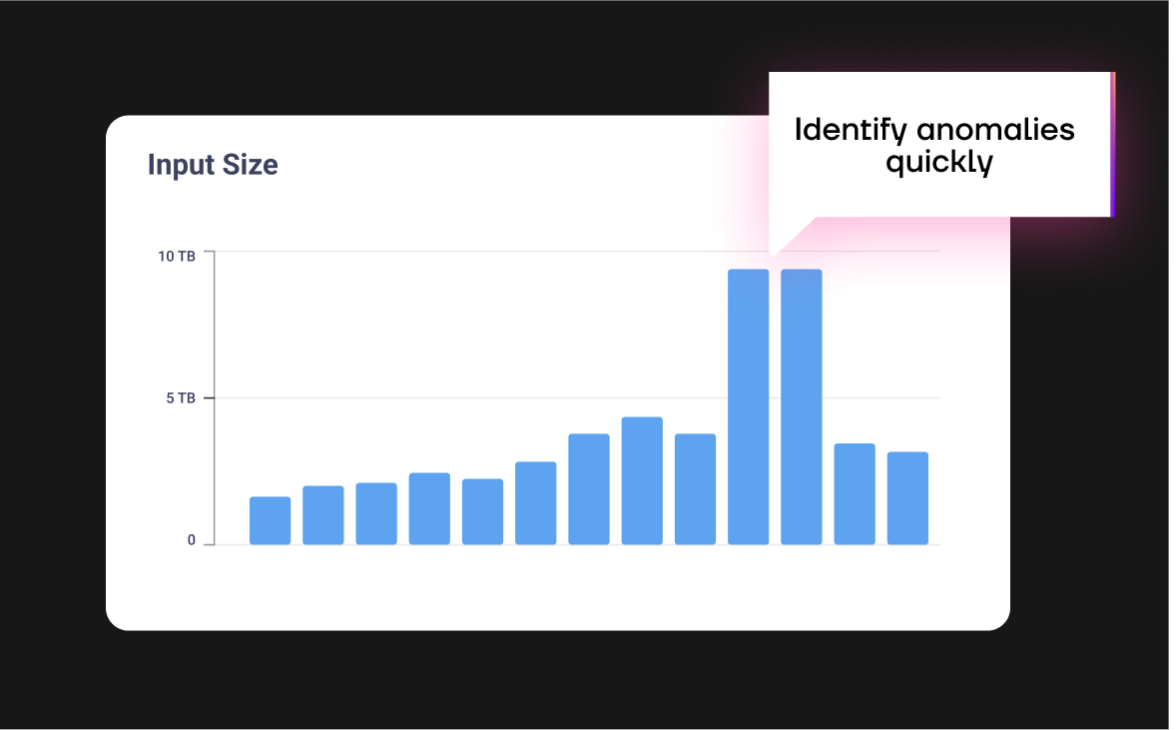
and observability
Gradient continuously monitors your job’s costs and Spark metrics to identify and adapt to anomalies. This data is available in the app to help data engineers identify root causes and jobs that require attention.
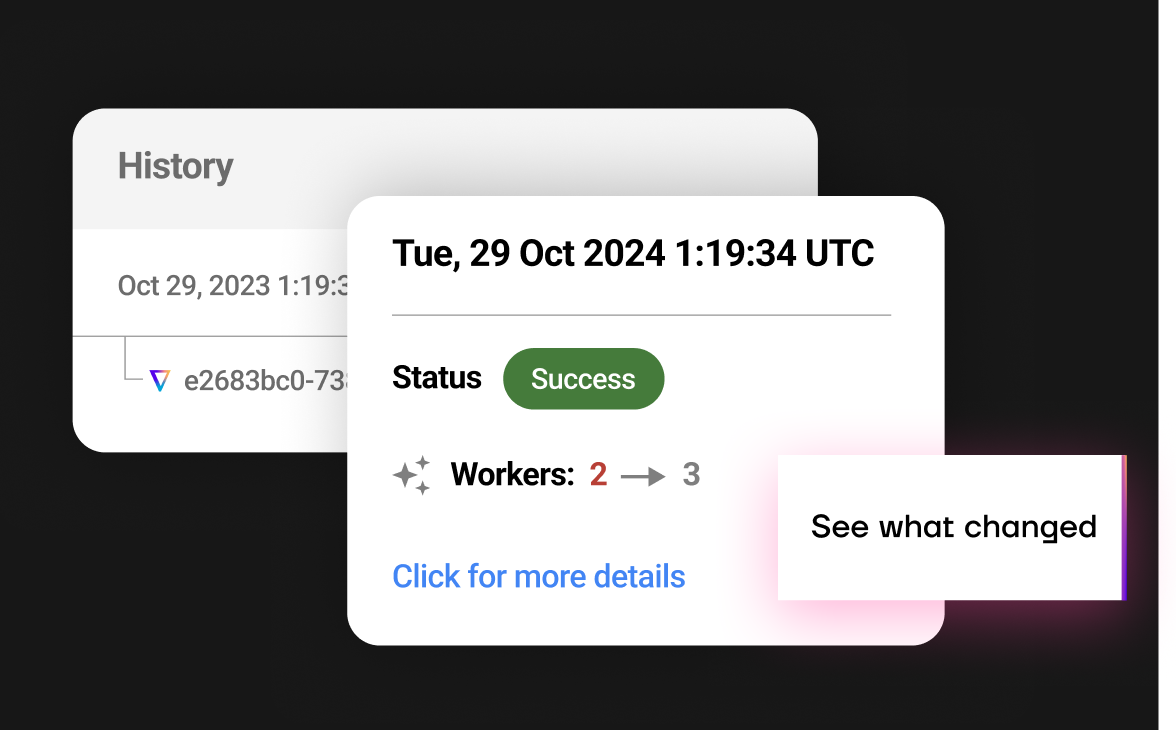
Self-improving models
Gradient uses a self-learning closed loop feedback system to ensure its performance improves over time. This system also allows it to adapt seamlessly to changes in workload patterns and cloud environments, becoming more accurate and efficient with each run.
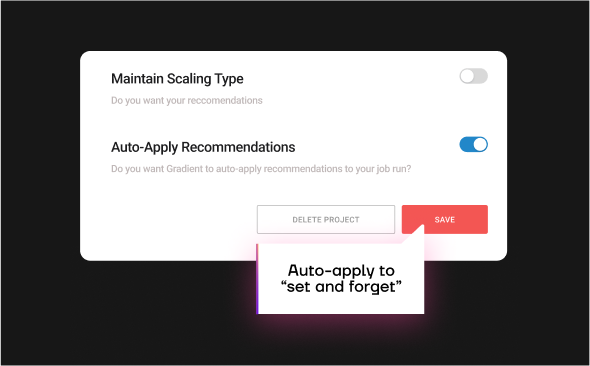
Co-pilot or full automation
Easily switch between co-pilot mode for guided optimization and full automation with a single click. Tailor the level of control to your team’s needs and comfort level.
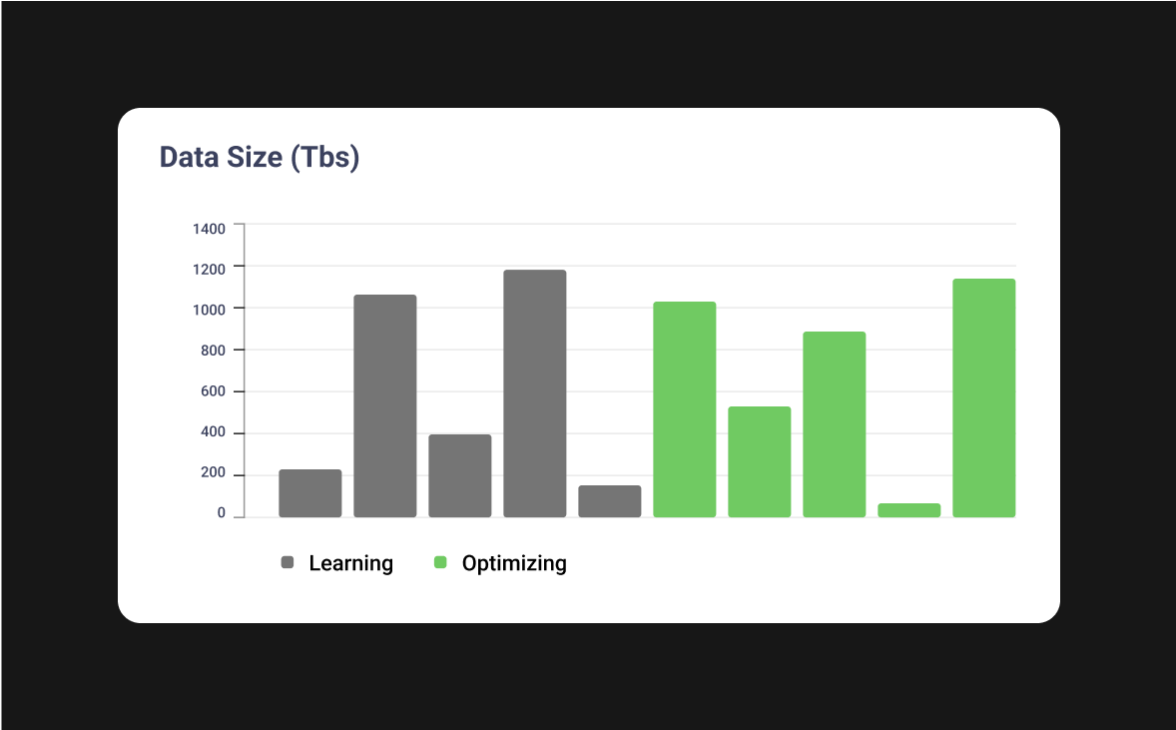
No pipeline too complex
Gradient works with any data pipeline, even complex ones with varying data sizes, cyclic data patterns, DAG dependencies, etc. Gradient’s API-first approach allows for full customization to your needs.
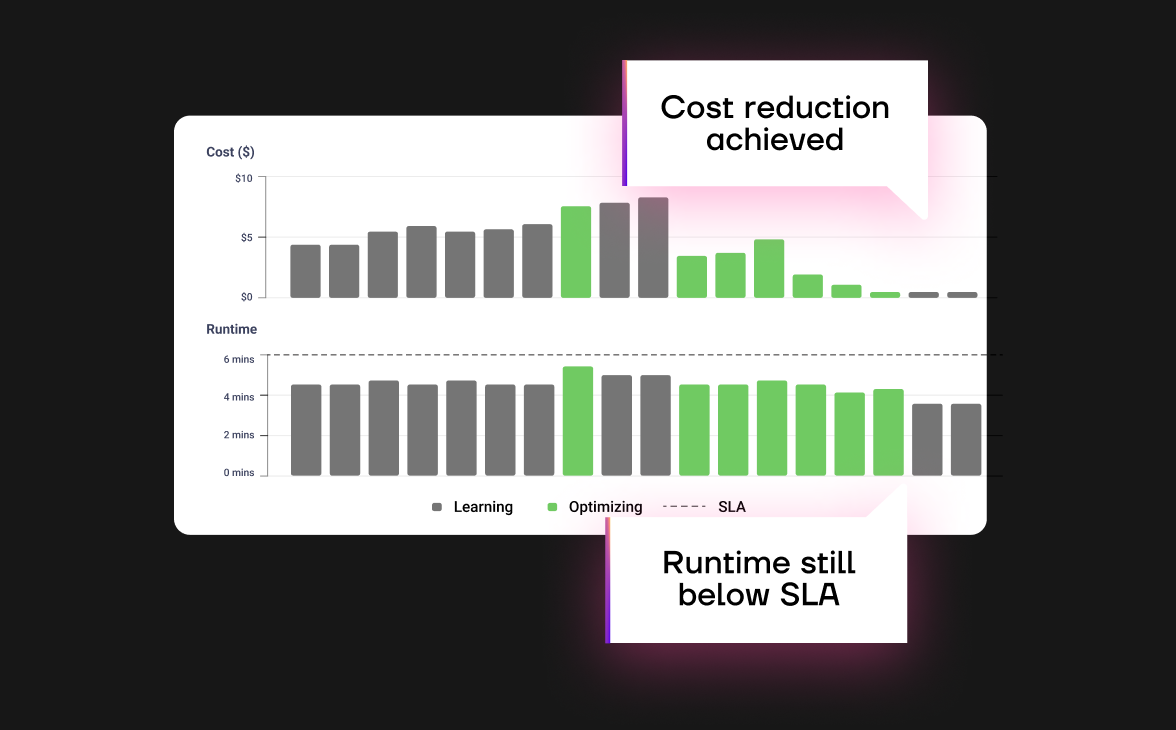
Goal-based optimization
Input your runtime SLA for Gradient to optimize your compute clusters to meet that SLA at the cheapest cost. Or if you just want the lowest compute costs possible, Gradient will optimize your clusters for the lowest costs.

I’d be surprised if there was any data team on the planet that wouldn’t save money and time from using Gradient.
Jesse Lancaster, CTO, Forma.ai





Visibility, security, and convenience
Enterprise-ready compute management solution
Fine-grained reporting
Gain full visibility into job costs and performance. Get all the granular information as well as overall spend, total savings, and ROI.
Compliant and secure
Gradient is SOC2 type II certified. And it automatically logs every recommendation and change it makes for easy compliance and auditability.

Works with your stack
Supports AWS, Azure, GCP (soon), and NVIDIA GPUs. Integrates with data orchestration/transformation services, such as Airflow, ADF, and dbt.
Explore additional capabilities
Get started today
Learn how Gradient can help you controls runtimes and
reduce compute costs