
As is the case with many concepts in technology, the term Serverless is abusively vague. As such, discussing the idea of “serverless” usually invokes one of two feelings in developers. Either, it’s thought of as the catalyst for this potential incredible future, finally freeing developers from having to worry about resources or scaling concerns, or it’s thought of as the harbinger of yet another “we don’t need DevOps anymore” trend.
The root cause of this confusion has to do with the fact that the catch-all term “Serverless” actually compromises two large operating models: functions and jobs. At Sync – we’re intimately familiar with optimizing jobs, so when our customers gave us feedback to focus a portion of our attention on serverless functions, we were more than intrigued.
The hypothesis was simple. Could we extend our expertise and background in optimizing Databricks large scale/batch compute workloads to optimizing many smaller batch compute workloads.
Serverless Functions
First, let’s see how we got here.
One of the most painful parts of the developer workflow is “real world deployment.” In the real world, deploying code that was written locally to the right environment and to work in the same way was extraordinarily painful. Libraries issues, scaling issues, infrastructure management issues, provisioning issues, resource selection issues, and a number of other issues plagued developers. The cloud just didn’t mimic the ease and simplicity of local developer environments.
Then Serverless functions emerged. All of a sudden, developers could write and deploy code in a function with the same level of simplicity as writing it locally. Then never had to worry about spinning up an EC2 instance or figuring out what the material differences between AMI and Ubuntu are. They didn’t have to play with docker files or even have to do scale testing. They wrote the exact same Python or NodeJS code that they wrote locally in a Cloud IDE and it just worked. It seemed perfect.
Soon, mission critical pieces of infrastructure were supported by double digit line python functions deployed in the cloud. Enter: Serverless frameworks. All of a sudden, it became even easier to adopt and deploy serverless functions. Enterprises adopted these functions like hotcakes. Many deployed in the hundreds or even thousands of these functions.
Why We Care
At Sync, our focus since our inception has been optimizing large scale compute jobs. Whether through Spark, EMR, or Databricks, the idea of introspecting a job and building a model through which we can understand and optimize that job, is our bread and butter. As we continued our development, multiple customers began asking for support of serverless technologies. Naturally, we assumed they were talking about Serverless Job functionality (which many were), but there was a substantial portion focused on Serverless Function functionality.
So we set out to answer a simple question: Are Serverless Functions in their current form working for the modern enterprise?
The answer, as it happens, is a resounding no.
Industry Focus
In 2022, an IBM blog post titled “The Future Is Serverless” was published, which cited the “energy-efficient and cost-efficient” nature of serverless applications as a primary reason that the future will be serverless. They make the – valid – case that reserving cloud capacity is challenging and consumers of cloud serverless functions are better served by allowing technologies such as KNative to streamline the “serverless-ification” processes. In short, their thesis is that complex workloads, such as those run in Kubernetes, are better served by Serverless offerings.
In 2023, Datadog released their annual “State of Serverless” post, where they show the continued adoption of Serverless technologies. This trend is present across all of the 3 major cloud vendors.
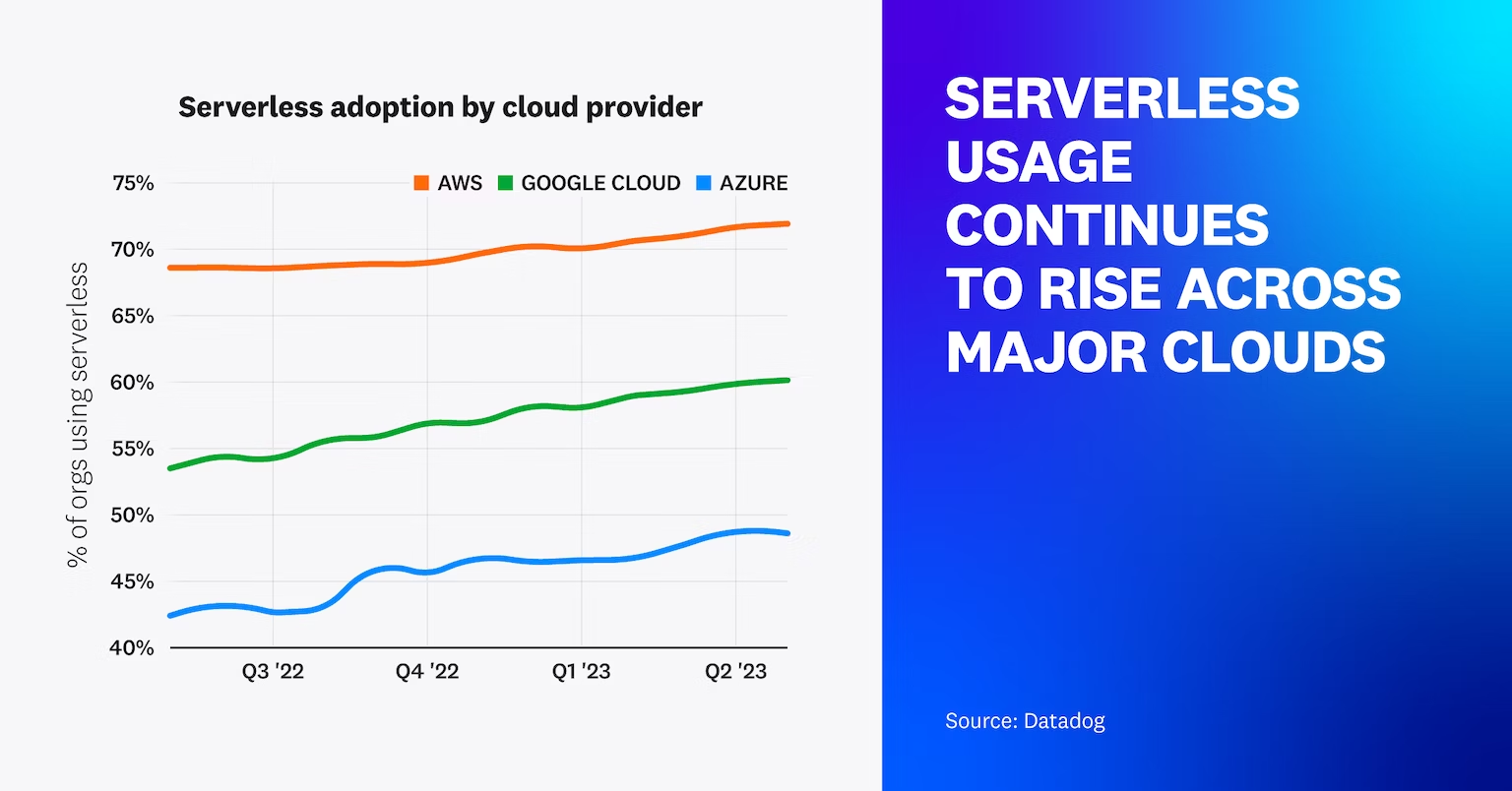
https://www.datadoghq.com/state-of-serverless/
The leader of the pack is AWS Lambda. Lambda has traditionally been the entry point for developers to deploy their Serverless workloads.
But hang on, 40%+ of Lambda Invocations happen in NodeJS? NodeJS is not traditionally thought of as a distributed computing framework, nor is it generally used for some large scale orchestration of computate tasks. But it seems to be dominating the Lambda serverless world.
So, yes, IBM argues that Serverless is great for scaling distributed computation tasks, but what if that’s not what you’re doing with Serverless?
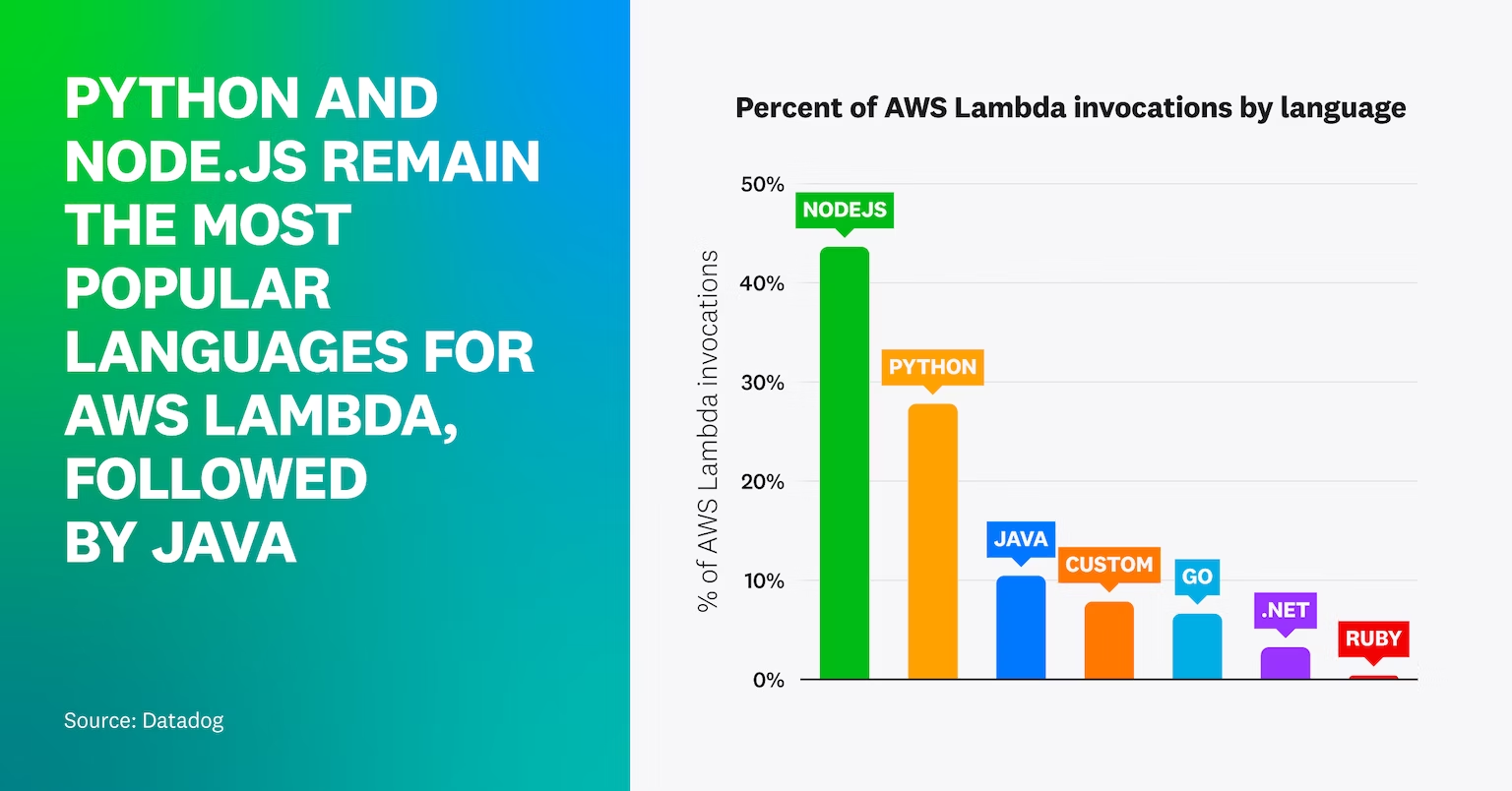
https://www.datadoghq.com/state-of-serverless/
What Serverless Solved
Before we get into the details of what’s missing, let’s talk about where things are currently working.
Where Things Work 1: Uptime Guarantees
One of the critical, but most frustrating pieces of the developer lifecycle is uptime requirements. Many developers hear the term five-nines, and shudder. Building applications that have specific uptime guarantees is not only challenging, it’s also time-intensive. When large scale systems are made up of small, discrete pieces of computation, the problem can become all the more complex.
Luckily, the Lambda SLAs guarantee a fairly reasonable amount of uptime, right out of the box. This can save otherwise substantial developer efforts of scoping, building, and testing highly available systems.
Where Things Work 2: Concurrency + Auto Scaling
Introspecting a large scale system isn’t easy. Companies like DataDog and CloudFlare run multi-billion dollar businesses off of this exact challenge. In an environment where requests can burst unexpectedly, creating and designing systems that scale based on spot user demand is also difficult.
One of the most powerful aspects of a serverless or hosted model (such as AWS Lambda), is the demand-based auto-scaling capabilities offered by the infrastructure. These effects are compounded, especially when the functions themselves are stateless. This effectively eliminates developers having to care about the operational concerns of autoscaling. There are unquestionably still the cost concerns, serverload concerns, and others, but serverless function offerings give developers a good starting point.
Problem 1: Developer Bandwidth
In a typical Serverless Function deployment, the initial choice of configuration tends to be the perpetual choice of configuration.
Wait, hang on, “initial choice of configuration”? Meaning, users still have to manually select their own configuration? It turns out, yes, users still need to manually pick a particular configuration for each serverless function they deploy. It’s actually a bit ironic – with the promise of true 0-management jobs, users are still required to intelligently select resource configuration.
If an engineer deploys and accidently overspecs a serverless function initially, it’s fairly unlikely that they will ever revisit the function to optimize it. This is generally the case for a few reasons:
- Time – Most engineers don’t have the time to go back and ensure that functions they have written weeks, months, or even years ago are operating under the ideal resources. This largely feeds into #2.
- Incentives – Engineers are not incentivized by picking the optimal resource configuration for their jobs. They’d rather have the job be guaranteed to work, while spending a bit more of their company’s compute budget.
- Employee Churn – Enterprises have inherent entropy and employees are oftentimes transient. People start jobs and people leave jobs. The knowledge generally leaves with them. When other engineers inherently previous work, they are significantly more incentivized to just ensure it works, rather than ensure that it works optimally.
Problem 2: Serverless Still Requires Tuning
Lambda is predicated on a simple principle – the resource requirements for workloads that take less than 15 minutes to run, can be pretty easily approximated. Lambda makes it easy for developers to set-and-forget, offering only one knob for them to worry about.
That knob is memory. Using Lambda, you can configure the memory allocated to a lambda function as a value between 128 MB and 10,240 MB. Lambda will automatically decide how much vCPU to allocate to you based on the memory setting.
This… sounds great. “I only have to pick one lever and, and all of a sudden, I get everything else figured out for me? That’s perfect!” If that were the end of the story, I would get to finish this post right now.
Instead, life is all about tradeoffs – generally correlated tradeoffs. In this case, it’s cost and performance. As an engineer, it’s easy for me to pick the largest memory setting available to me just to ensure my Lambda function works, regardless of what its actual resource requirements are. Once it works, why would I ever touch it again?
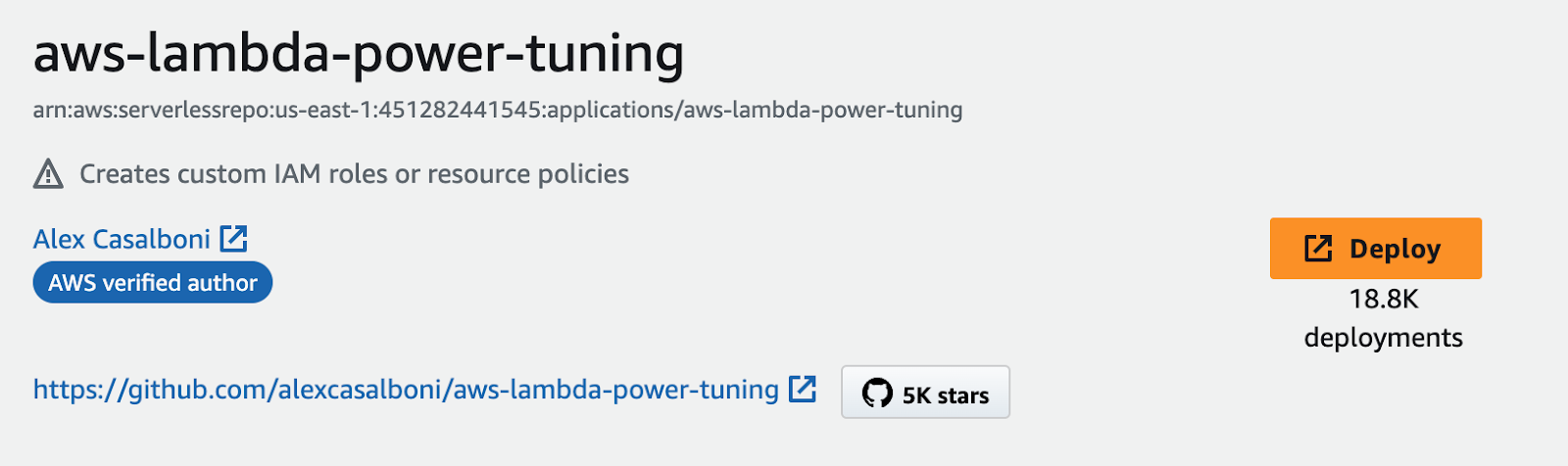
Well, it turns out that picking large, frequently uncorrelated-to-necessary-resources values isn’t the most cost effective thing to do. So much so, in fact, that an AWS Solutions Engineer built and open sourced a tool to help users actually find the correct memory levels for their Lambda functions. The tool uses AWS Step Functions to walk users down to the minimum necessary level. It’s been so popular that it has 5K stars on GitHub… and 18.8K
deployments.
Clearly, the one-knob-rules-all solution isn’t working.
Problem 3: Serverless Is Hard to Introspect
The scale and growth testing that plagued engineers for decades before the rise of Serverless, was unfortunately not in vain. Understanding how users will be interacting with an application, in terms of number of requests or compute load gives engineers a powerful understanding of what to expect when things go live.
In the Serverless Function architecture, engineers don’t think about these considerations and push the burden onto the infrastructure itself. As long as the infrastructure works – it’s unlikely that an already oversubscribed engineer would spend time digging into the performance or cost characteristics of the Serverless function.
Absent home-rolled solutions, there are few tools that allow for the detailed observability of a single serverless function. Furthermore, there are usually hundreds if not thousands of serverless functions deployed. Observability across a fleet of functions is nearly impossible.
Furthermore, the primary mechanism folks can use for per-function observability is AWS CloudWatch. Cloudwatch logs events for each lambda invocation and stores a few metrics. The major problem though, is that just collecting this information in CloudWatch has been observed to be more expensive than Lamba itself. In fact, there are full articles, posts, and best practices around just managing the costs associated with Lambda CloudWatch logs.
Problem 4: No Auto-Optimization
The year 2023 brought on a material shift in the mentality of “compute” consumers. Enterprises that were previously focused on growth at all costs shifted their focus to efficiency. Vendors in the generic Cloud, Snowflake, and Databricks ecosystem popped up at increasing rates. Most had a simple goal – provide high level visibility into workloads.
They provided interactive charts and diagrams to show ongoing cost changes… But they didn’t provide the fundamental “healing” mechanisms. It would be like going to the doctor, having them diagnose a problem, but provide no recourse.
Consistent with their focus on efficiency, enterprises had a few options. Larger ones deployed full teams to focus on this effort. Smaller ones that didn’t have the budget or manpower turned to observability tools… nearly all of which fell short, as they missed the fundamental optimization component.
Providing detailed visibility across a few, large scale jobs is considered table stakes for many observability providers, but for some reason providing that same level of visibility across many, small scale jobs, in an efficient and easy to optimize way hasn’t become standard.
Conclusion
We’re in a fairly unique period as an industry. Job visibility, tuning, introspection, and optimization have reemerged as key pieces of the modern tech stack. But most focus on the whales, when they should be focusing on the barracudas.
If these problems resonate with you – drop us a line at info@synccomputing.com. We’d love to chat.