
April showers bring May product updates! Take a look at Sync’s latest product releases and features. 💐
The Sync team is heading to San Francisco for the Databricks Data+AI Summit 2024! We’ll be at Booth #44 talking all things Gradient with a few new surprise features in store.
Want to get ahead of the crowd? Book a meeting with our team before the event here.

Download our Databricks health check notebook
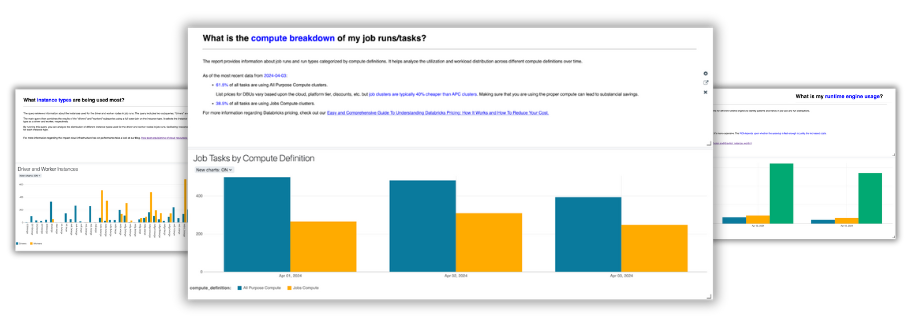
Have you taken advantage of our fully customizable health check notebook yet?
With the notebook, you’ll be able to answer questions such as:
⚙️ What is the distribution of job runs by compute type?
⚙️ What does Photon usage look like?
⚙️ What are the most frequently used instance types?
⚙️ Are APC clusters being auto-terminated or sitting idle?
⚙️ What are my most expensive jobs?
The best part? It’s a free tool that gives you actionable insights so you can work toward optimally managing your Databricks jobs clusters.
Head here to get started.
Apache Airflow Integration
Apache Airflow for Databricks now directly integrates with Gradient. Via the Sync Python Library, users are able to integrate Databricks pipelines when using 3rd party tools like Airflow.
To get started simply integrate your Databricks Workspace with Gradient via the Databricks Workspace Integration. Then, configure your Airflow instance and ensure that the syncsparkpy library has been installed using the Sync CLI.
Take a look at an example Airflow DAG below:
from airflow import DAG
from airflow.decorators import task
from airflow.operators.python import PythonVirtualenvOperator
from airflow.providers.databricks.operators.databricks import DatabricksSubmitRunOperator
from airflow.utils.dates import days_ago
from airflow.models.variable import Variable
from airflow.models import TaskInstance
from sync.databricks.integrations.airflow import airflow_gradient_pre_execute_hook
default_args = {
'owner': 'airflow'
}
with DAG(
dag_id='gradient_databricks_multitask',
default_args=default_args,
schedule_interval = None,
start_date=days_ago(2),
tags=['demo'],
params={
'gradient_app_id': 'gradient_databricks_multitask',
'gradient_auto_apply': True,
'cluster_log_url': 'dbfs:/cluster-logs',
'databricks_workspace_id': '10295812058'
}
) as dag:
def get_task_params():
task_params = {
"new_cluster":{
"node_type_id":"i3.xlarge",
"driver_node_type_id":"i3.xlarge",
"custom_tags":{},
"num_workers":4,
"spark_version":"14.0.x-scala2.12",
"runtime_engine":"STANDARD",
"aws_attributes":{
"first_on_demand":0,
"availability":"SPOT_WITH_FALLBACK",
"spot_bid_price_percent":100
}
},
"notebook_task":{
"notebook_path":"/Users/pete.tamisin@synccomputing.com/gradient_databricks_multitask",
"source":"WORKSPACE"
}
}
return task_params
notebook_task = DatabricksSubmitRunOperator(
pre_execute=airflow_gradient_pre_execute_hook,
task_id="notebook_task",
dag=dag,
json=get_task_params(),
)
##################################################################
notebook_taskAnd voila! After implementing your DAG, head to the Projects dashboard in Gradient to review recommendations and make any necessary changes to your cluster config.
Take a look at our documentation to get started.