Sync Computing Joins NVIDIA Inception to Expand to GPU Management


We’re thrilled to announce that Sync Computing has joined NVIDIA Inception, a program designed to nurture startups revolutionizing industries with technological advancements. This collaboration marks a significant milestone in our journey to extend our compute infrastructure management solution from CPUs to also include GPUs for data and AI workloads.
Read on to learn how we can help you optimize your compute infrastructure, using advanced machine-learning models developed in MIT.
The challenge of compute optimization
In today’s data-driven world, organizations are increasingly relying on cloud infrastructure to process vast amounts of data. However, managing and optimizing these resources can be a daunting task, often requiring specialized knowledge and significant time investment. This is where Gradient by Sync comes in, offering a revolutionary approach to compute optimization.
At Sync, we’re dedicated to solving one of the most pressing challenges in modern cloud computing: optimizing infrastructure for complex data and machine learning workloads. We built Gradient to empower organizations to optimize compute resources at scale, whether they are on CPUs or on GPUs on the cloud. Gradient takes the guesswork out of compute optimization and helps you find the right balance between improving job performance and lowering compute costs.
The power of declarative computing
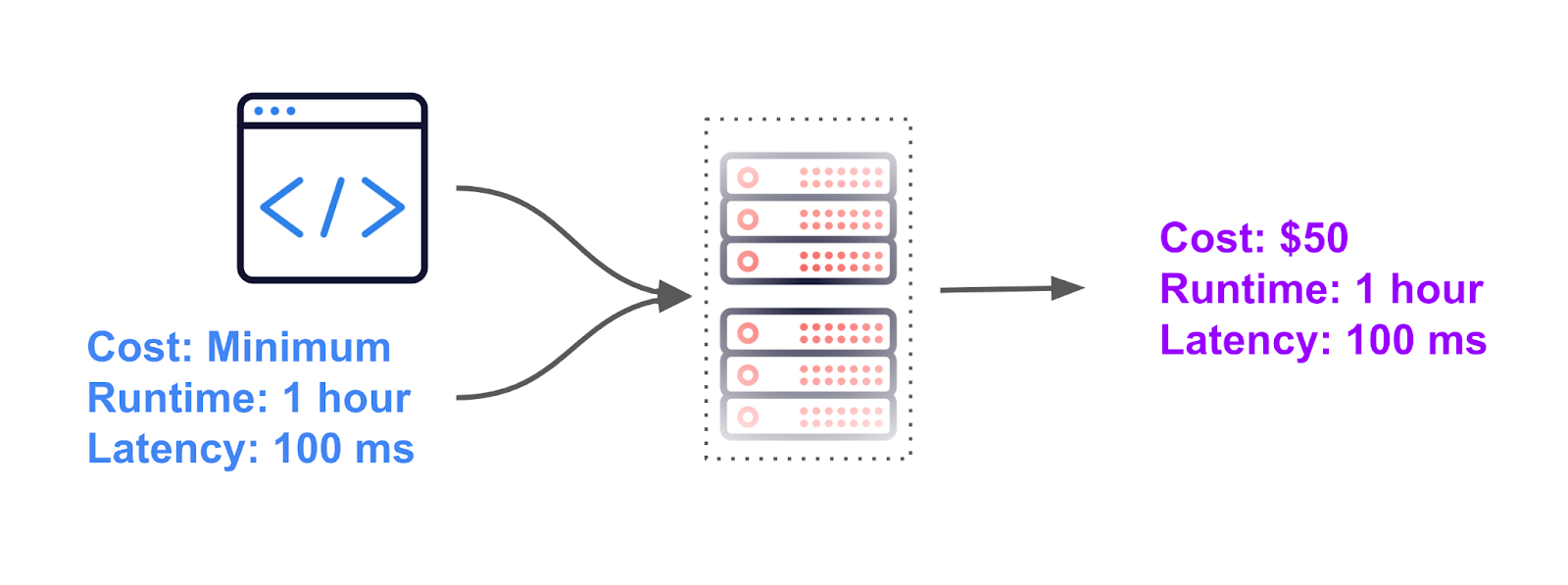
Central to our approach is the concept of “declarative computing.” With declarative computing, users specify what they want to achieve rather than how to achieve it. In the context of cloud infrastructure, it enables organizations to define their desired outcomes, such as cost savings or shorter runtimes, without needing to understand the complexities of compute resource allocation and optimization.
Gradient delivers the following benefits by applying this approach to cloud computing:
1. Simplification: By abstracting away low-level details, Gradient makes complex systems more accessible and manageable. And by focusing only on the metrics we’ve found to impact workload cost and performance, Gradient helps engineers level-up their compute optimization skills.
2. Optimization: Gradient automatically determines the most efficient way to achieve your declared goals. By default, the system will work towards cost savings, but you can input your desired runtime SLA and Gradient will ensure you meet it at the lowest price point.
3. Adaptability: Gradient continuously monitors and optimizes your workloads, so it can seamlessly adapt and alert you of changes to your data pipelines.
4. Scalability: Gradient was built for optimization at scale. Turn on autopilot mode to enable a single engineer to manage 1000s of jobs. You can always switch back to co-pilot mode in a click. In this mode you can review Gradient’s optimization recommendations and apply them with a click.
Declarative computing in action
Let’s consider a practical example: Imagine you’re a data engineer tasked with optimizing a large-scale data processing job on a cloud platform. Traditionally, you might spend hours or even days tweaking various parameters such as cluster instance types, cluster sizes, and resource allocations until you were satisfied with your configuration. You’d then move on to the next task, and revisit this configuration once a quarter.
We’ve found that 9 out of 10 of these “good enough” configurations are over provisioned and/or misconfigured. This is because the way things currently are, you really do need to be an expert to effectively manage your data processing infrastructure.
With a declarative approach, you abstract away all of this complexity and simply specify your requirements:
Cost: Minimum
Runtime: < 1 hours
Latency < 100msThe system then automatically determines the most efficient configuration to meet these requirements, considering factors such as pipeline trends, available resources, and historical performance data.
Today, Gradient helps organizations manage CPU-based product workloads in Databricks. It has helped customers manage more than 3 million core hours to date. We’ve helped security, education, finance, media, analytics, AI, and healthtech companies save up to 50% on their compute costs and regain 1000s of engineering hours with automation. We can do the same for you – drop us a line to learn how.
Synergy with NVIDIA Inception
Joining NVIDIA Inception will accelerate Sync Computing’s expansion from CPU-based workloads to GPU workloads in the machine-learning and AI compute space. The program will provide us with valuable resources and expertise to enhance our GPU optimization capabilities. Additionally, NVIDIA Inception will offer us the opportunity to collaborate with industry-leading experts and other AI-driven organizations.
We’re excited to be part of NVIDIA Inception. This program will be instrumental in helping us further develop our technology to meet the growing demand for efficient GPU-accelerated data and AI processing. We look forward to leveraging NVIDIA’s expertise to deliver even more value to our customers. – Jeff Chou, Sync Co-founder and CEO
Extending to GPUs
GPUs have become increasingly important in the world of data processing and machine learning. Their parallel processing capabilities make them ideal for handling the complex computations required in these fields. Through the NVIDIA Inception program, Sync aims to extend their flagship product Gradient, to optimize GPU-based workloads to help companies meet performance and cost goals at scale.
Advancing cloud compute optimization
By combining a declarative computing approach with the resources provided by NVIDIA Inception, Gradient aims to push the boundaries of cloud infrastructure optimization. Our goal is to create a future where managing complex compute environments is as straightforward as declaring your desired outcomes.
Imagine a world where cloud resources automatically adapt to your changing needs, where scaling up or down happens seamlessly based on your declared performance and budget requirements. This is the future we’re working towards with Gradient, and our participation in NVIDIA Inception brings us one step closer to realizing this vision.
The road ahead

As we embark on this exciting journey with NVIDIA Inception, we have the following objectives in mind:
1. Extend to GPU optimization: We’re working on extending Gradient to apply to GPU workloads for data processing, machine learning, and AI production jobs.
2. Expand support to additional platforms and services: While we currently focus on Databricks Jobs compute, we aim to expand into additional Databricks services as well as support a wider range of data platforms.
3. Foster relationships: We’re actively seeking design partners who want more out of their GPU clusters to discuss and test innovative solutions for compute optimization across environments.
Drop us a line to learn more.
Conclusion
As Gradient continues to evolve, we remain committed to simplifying cloud infrastructure management and optimization for data engineers and organizations worldwide. The challenges of cloud computing are ever-evolving, but with our innovative approach and the support of NVIDIA Inception, we’re well-positioned to make a major leap forward towards our company vision.
We believe that the future of cloud computing lies in intelligent, automated systems that can understand and adapt to the needs of users without requiring deep technical expertise. By abstracting away the complexities of cloud infrastructure, we’re not just optimizing resources – we’re empowering organizations to focus on what really matters: innovation, growth, and delivering value to their customers.
Join us on this exciting journey as we redefine what’s possible in cloud optimization. If you’re looking to maximize the efficiency of your CPU and GPU infrastructure, we’re here to help.
Book a time to speak with the team about your challenges.
 Kartik Nagappa
Kartik Nagappa