New Gradient quick-start notebooks- Optimize your Databricks jobs in minutes

Our new quick-start notebooks make testing Gradient crazy easy, to help people quickly optimize their Databricks Jobs at scale.

Since we launched Gradient to help control and optimize Databricks Jobs, one piece of feedback from users was crystal clear to us:
“It’s hard to set up”
And we totally agreed. By nature, Gradient is a pretty deep infrastructure product that needs not only your Spark eventlogs but also cluster information from your cloud provider.
As a near term solution – we built an easy to use notebook that you run in your Databricks environment that will do all of the setup with a single click.
See the new Gradient quick-start guide here
Easy as 1-2-3-4
- Create a Sync Account
- Create a project in Gradient
- Run the “Gradient setup” notebook
- Review and test the recommendation with the “Apply Recommendation” notebook
For users who orchestrate their jobs with Databricks Workflows, this notebook helps to automate the setup process making it easier for people to get started quickly.
The “Gradient Setup” Notebook
This notebook is run locally in your Databricks environment, so no credential information is shared with Sync minimizing any security issues. At a high level this notebook does the following:
- User inputs the job-id of the desired Job they would like to test Gradient on
- Downloads the necessary file from Sync’s open source Github
- Creates Databricks secrets with your credentials
- Clones your job to make testing safer
- Adds an init script & environmental variables to the job cluster
- Appends a new task with a new single node cluster after the selected job to auto-submit logs
Below is a screenshot of the top cell of the notebook entry point where you replace the 6 values below which help point the notebook towards the job you want to optimize as well as your Gradient project.

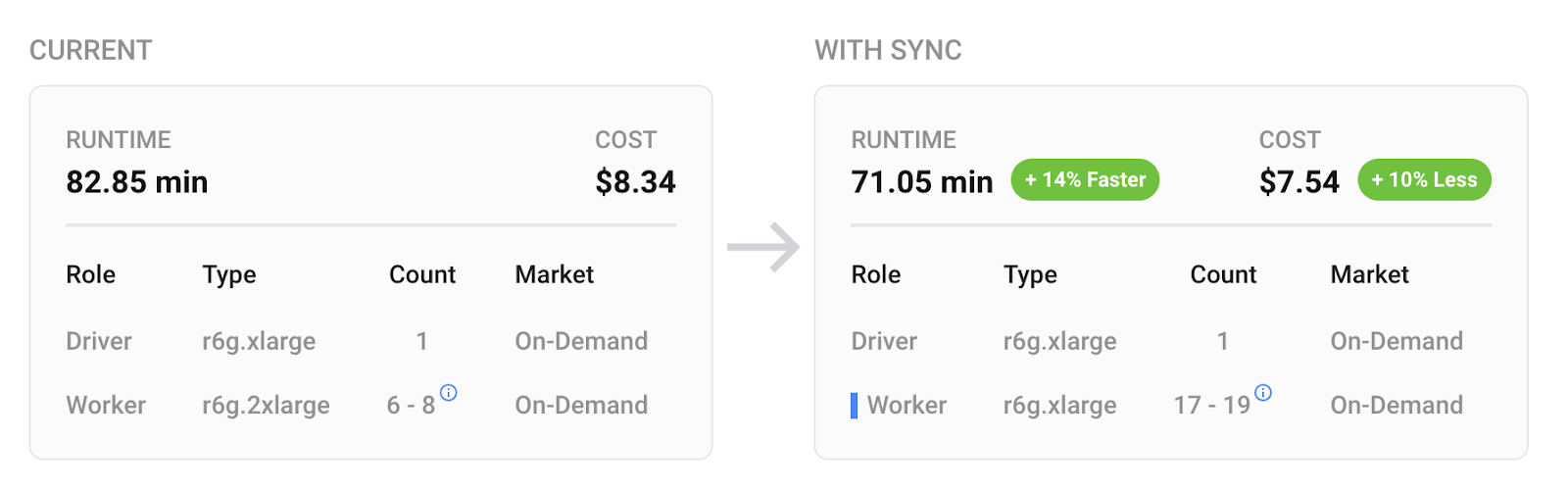
Once this notebook is run, users can go into the Gradient UI to see their shiny new recommendation. Users can also configure their optimization goals to hit different SLA runtimes.
The “Apply Recommendation” notebook
To easily apply the recommendation, we provide another notebook which performs the following:
- User inputs the job-id of the desired Job they would like to update
- Retrieves the recommendation from Gradient
- Updates the cluster configurations detailed in the recommendation
Users can simply copy and paste the same input configuration text block and click “run notebook” to finish.

After this, simply re-run your newly configured job and verify the and after performance!
Prerequisites
One major prerequisite for the notebook, and Gradient in general, is permissions to retrieve cluster information from your cloud provider. This permission is granted via instance profiles.
For some small companies, creating an instance profile on AWS is pretty straight forward. For larger companies, it may involve working with your devops or security teams!
For more details check out our docs on permissions.
Try it now!
Follow our quick-start guide here to try Gradient for free
Questions or feedback?
If you have any questions or feedback, please don’t hesitate to reach out to us via Intercom or email us at: support@synccomputing.com
 Kartik Nagappa
Kartik Nagappa
 Noa Shavit
Noa Shavit