
Save up to 50% on compute!
Save on compute while meeting runtime SLAs with Gradient’s AI compute optimization solution.

Databricks is a quickly evolving platform with several compute options available for users, leaving many with a difficult choice. In this blog post, we look at three popular options for scheduled jobs using Databricks own’ TPC-DI benchmark suite.
By the way, kudos to the Databricks team for creating such a fantastic test package. We highly encourage anybody here to use it for their own internal testing. Just to re-iterate, these workloads were not created by us, nor modified in any way. We’re big compute efficiency nerds here at Sync, so we appreciate all contributions in this space.
The goal of this blog post is to help readers understand the pros, cons, and performance tradeoffs of the various Databricks compute options, so they can make the best choice for their workloads.
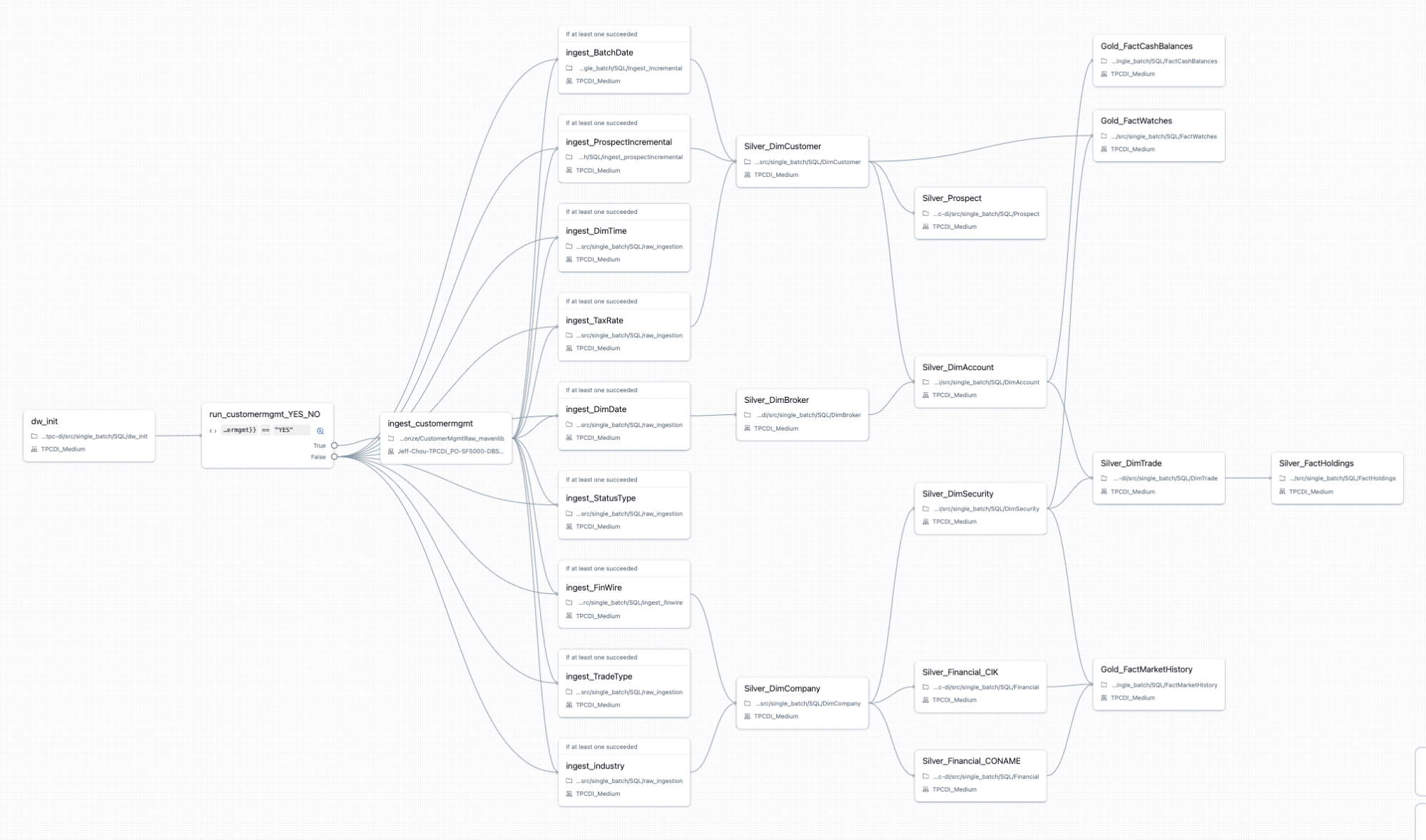
At a high level, the TPC-DI benchmark is an industry standard benchmark for data integration, and mimics many real world workloads that users utilize in their jobs and workflows. Below is a screenshot of the DAG that is created for the entire benchmark:
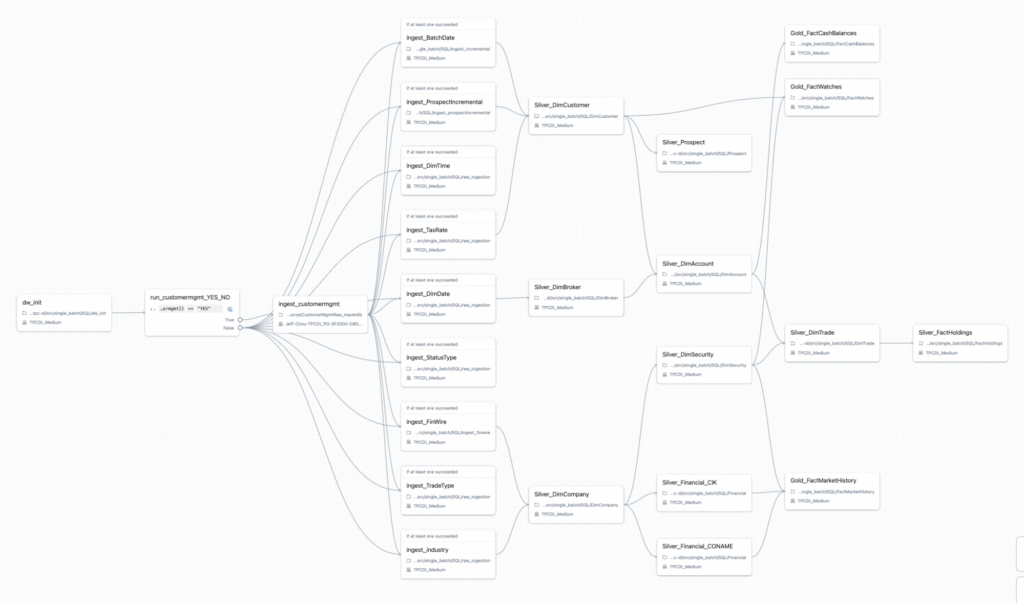
One of the main knobs to tune for the TPC-DI benchmark is the “Scale Factor” (SF), which changes the size of the data that is processed. The table below translates the SF to actual raw data size for comparison.
We focused on 3 scale factors:
| Scale Factor | Total Raw Data |
| 100 | 9.66 GB |
| 1000 | 97 GB |
| 5000 | 485 GB |
In this study, we’ll compare the running TPC-DI on 3 different Databricks compute products:
For those who want to dive into the details, here’s the full table with all of the details of the experiments and raw numbers:

At a high level, these were some of the choices we made in regards to some of the settings:
1) Classic Jobs compute – We only tuned the number of workers here, and used the same recommended instance types. We tuned the optimal cluster size and allowed a max runtime about 40% longer than the other compute platforms, which is consistent with the experience we see with users. In addition, we used all on-demand clusters.
2) Serverless Jobs Compute – We didn’t tune or change anything here, since there’s nothing to change!
3) DBSQL Serverless – We used the recommended warehouse sizes from the notebook
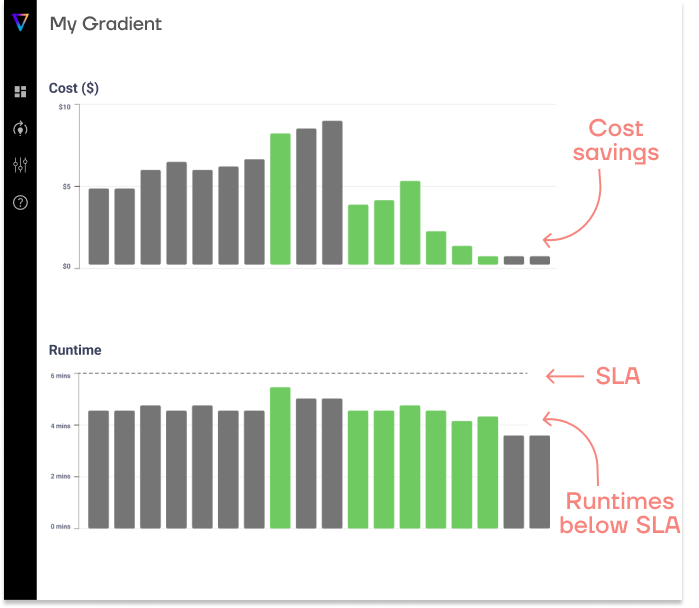
You can see the cost graph across all 9 experiments below. The cost represents the total cost of DBUs and cloud costs (AWS in this case). Several observations can be made:

For completeness, here are the corresponding runtimes for all 9 experiments. As we mentioned above, we tuned the classic cluster to run slightly longer if it meant a cheaper cost. We tried to keep it to “reasonable” increases in runtime.
Overall, DBSQL and Jobs Serverless were about the same in terms of runtime.

How do I find the optimal Classic cluster?
The big tradeoff with Classic clusters is you have to know what to pick. This is the dark art of Spark and experienced engineers. Usually people just do some trial and error analysis with a few different configs to get a rough idea of an optimal cluster size. They then typically only revisit the configuration once a quarter at best, while data pipelines change much more rapidly.
At Sync, we built a tool that automatically finds the best cluster for each of your jobs at scale. We call it Gradient. If you’re running Databricks jobs at scale and just can’t manually tune all of those clusters to lower costs, feel free to check us out to see if Gradient can help improve your Databricks efficiency automatically.
Save on compute while meeting runtime SLAs with Gradient’s AI compute optimization solution.
Why were DBSQL warehouse costs so much lower than Serverless Jobs costs?
Their runtimes were the same, so that means that the DBU consumption rate of both are quite different.
In fact, the DBU rate of a large SQL warehouse is 40 DBUs/hr. Since the runtimes were about the same but the end costs were almost 2x, we can roughly estimate that the jobs serverless DBU rate is about 80 DBUs/hr.
This is a pretty surprising finding (and is not the official DBU rate of Jobs Serverless), and is only based on our loose back of the envelope calculations. However, it does highlight the discrepancy between these different products and how the wrong choice can lead to exorbitant costs.
How did the query level performance change?
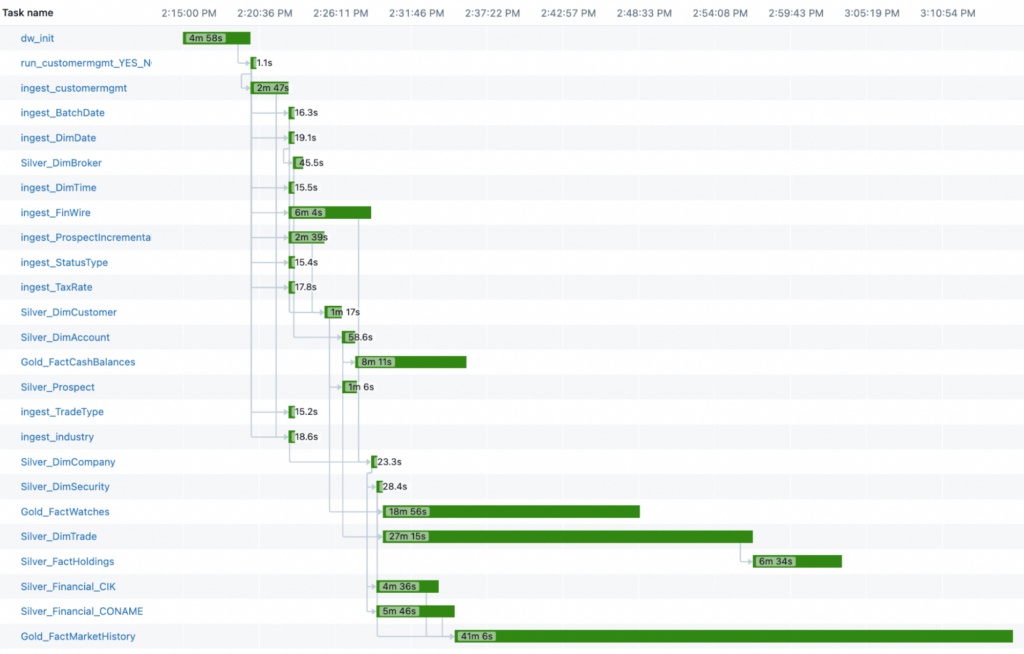
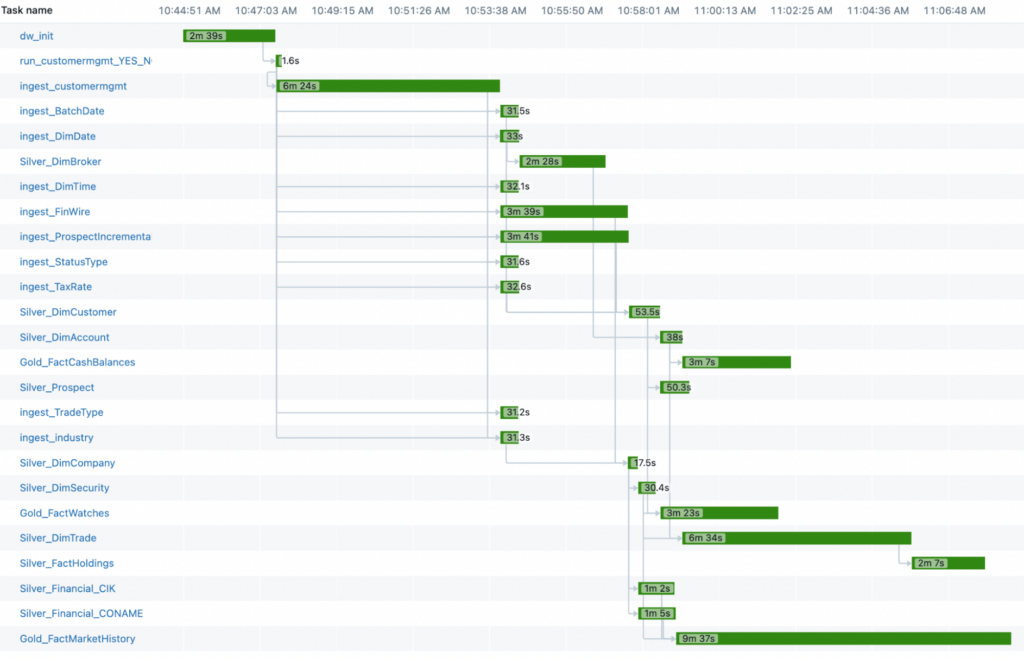
It’s interesting to break open the timeline view of the queries to see how the different compute platforms behave. Different queries ran at different runtimes with the different platforms.
One big difference is the “ingest_customermgmt” task was actually a “classic cluster” for all 3 (probably due to some limitations of serverless). This requires a spin up time of the classic cluster which delayed the serverless options. For the classic cluster, this step was very fast, since the whole compute is on classic.
The other observation is the distribution of the “long tasks” and whether or not there were dependencies. Meaning, you may have a long running task but it actually is in parallel with all other tasks so it’s fine that it’s slow. However, if one task is the core dependency for all other tasks (such as the “ingest_customermgmt” task), then a single long running task in your DAG can really hurt your performance.
Classic Jobs
Serverless Jobs

DBSQL
Hopefully this detailed study of the TPC-DI benchmark on Classic Jobs vs Serverless Jobs vs SQL Warehouse helps communicate how different your performance will be on Databricks, depending on which compute platform you select. At a high level the main dependencies are:
If you’re at a company where your core backend is scaled on Databricks, then this level of optimization may be a critical step to help lower your total cost of goods sold (COGS).
However, if you’re at a company just exploring Databricks and costs aren’t a concern, then I recommend just sticking to serverless compute for the convenience.
If you’re interested in understanding what’s right for your company’s Databricks usage, feel free to book a time that works for you here!
We’d love to chat.
 Kartik Nagappa
Kartik Nagappa
 Noa Shavit
Noa Shavit
{kind=link}