Best Practices to Manage Databricks Clusters at Scale to Lower Costs


Managing Databricks clusters efficiently is a critical challenge for many organizations, especially as they scale on the platform. As the amount of data organizations process grows rapidly, so do compute costs. Most organizations tackle this by having their data engineers manually optimize clusters, which quickly becomes a bottleneck as the organization scales from dozens to hundreds of jobs or more.
At the recent Databricks Data + AI conference, Sync co-founder and CEO, Jeff Chou, shared data-driven tactics and real-world examples of companies that are seeing significant savings on their Databricks Jobs spend through these cluster optimizations.
Keep in mind that every workload is unique and what might work for some might not work for others. This is why we provide a combination of optimization tactics for engineers to see what works for their jobs. Read on for the key takeaways, or watch the video below.
Common pitfalls and effective practices for optimizing your Databricks compute spend
Based on our research and conversations, we’ve identified six main areas where companies often face challenges. These include the use of spot vs. on-demand instances, Photon and autoscaling, all-purpose clusters, serverless compute vs classic clusters, and EBS optimization.
Here are the most common pitfalls and best-practices:
- Optimizing cluster instances: Selecting appropriate driver and worker instance types is crucial. Many companies use generic configurations, leading to inefficiencies. A more tailored approach can significantly reduce compute costs.
- Photon and autoscaling: While Photon technology and autoscaling can enhance performance, their benefits are highly workload-dependent. With Photon costing 2X per DBU and autoscaling costing 37% more than fixed clusters, the best practice here is to A/B test your jobs with and without Photon and autoscaling applied to ensure these features reduce your job’s compute costs rather than increase them.
- Elastic Block Storage (EBS) optimization: EBS settings can have a substantial impact on performance. Although often overlooked, optimizing these settings can lead to significant improvements in job runtime and cost.
- Appropriate use of All-Purpose Compute (APC) clusters: APC clusters are shared resources and can be much more expensive than job-specific clusters. Ensuring that workloads are matched to the appropriate cluster type can prevent unnecessary expenses.
- Understanding the risks of spot instances: While spot instances can offer cost savings, they come with risks, particularly for distributed workloads like Spark. The potential for worker revocation can lead to increased costs, performance issues, and even job failures.
- Serverless computing: Serverless solutions simplify cluster management by eliminating the need for manual tuning. This approach can reduce overhead and improve efficiency, especially for ad-hoc and interactive workloads. However, there is a tradeoff between the convenience of serverless and the lack of control over the configuration of your data infrastructure. In addition, serverless compute isn’t necessarily cheaper- more about that later.
Real-world impact
Our flagship product, Gradient, is a best-practice machine that automates many of these best practices, as well as others not mentioned. By leveraging advanced machine-learning algorithms, Gradient optimizes cluster configurations and manages resources dynamically, seamlessly adapting to changes in data pipelines (including data size variations). As a result, organizations see up to 50% cost savings and get back 10 hours/week per data engineer that no longer has to manually tune compute clusters.
Since its launch, Gradient has helped multiple organizations significantly reduce their Databricks Jobs spend, while obeying strict runtime SLAs. Companies have reported cost savings ranging from 20% to 63% on their Databricks jobs, depending on the extent they use Gradient.
Serverless compute vs. optimized classic clusters
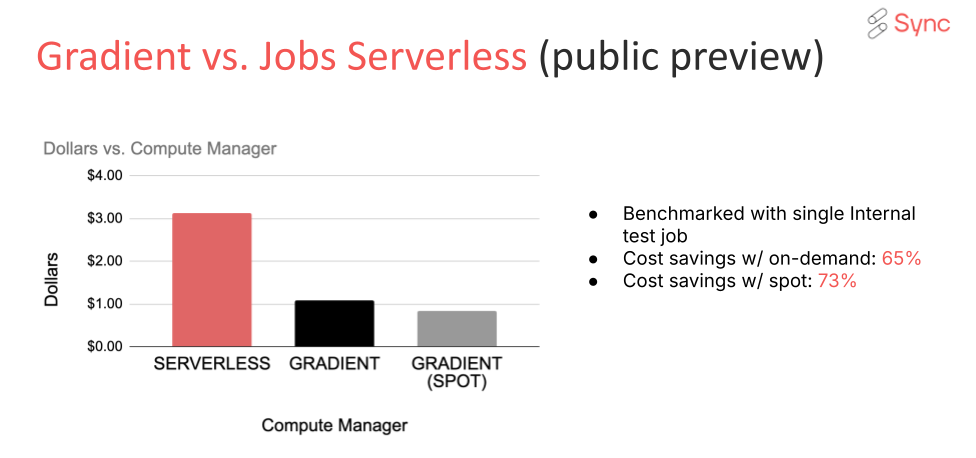
With Databrick’s recent launch of serverless compute, this seems to be the question of the hour. We analyzed the cost and performance of running the same Databricks Jobs on serverless computing and optimized classic clusters, and here’s what we learned:
- Startup time: Serverless clusters have significantly faster startup times compared to classic clusters, which can lead to improved productivity and reduced waiting times for data engineers and scientists.
- Cost efficiency: While serverless clusters can be more cost-effective for short, bursty workloads due to their pay-as-you-go model, optimized classic clusters may offer better cost efficiency for long-running, stable workloads. In fact, we found that optimized classic clusters outperformed serverless compute by 60%!
- Resource allocation: Serverless clusters automatically handle resource allocation, removing the need for manual configuration. This can be particularly beneficial for teams with varying workloads and less expertise in cluster management.
- Scaling: Serverless clusters provide automatic scaling, which can be advantageous for handling unpredictable workloads. However, for predictable, consistent workloads, optimized classic clusters with pre-configured scaling policies may be more efficient.
- Performance: The performance of serverless clusters can vary based on the underlying infrastructure and workload characteristics. Optimized classic clusters, on the other hand, can be fine-tuned to achieve consistent performance. If consistent performance and costs are important to you, serverless might not be the best choice.
- Maintenance: Serverless clusters reduce the maintenance burden by abstracting away the underlying infrastructure management. This allows teams to focus more on data processing and analysis rather than cluster upkeep. This is a major advantage, but it comes at the expense of losing control of your cluster configuration.
- Flexibility: Serverless clusters offer greater flexibility in terms of scaling and resource allocation, making them suitable for dynamic workloads. However, classic clusters, while less flexible, can be optimized for specific use cases to maximize performance and cost efficiency.
- Security: Both serverless and classic clusters offer robust security features, but the choice between them may depend on specific organizational requirements and compliance needs.
- Use cases: Serverless clusters are ideal for ad-hoc, interactive, and exploratory workloads, while optimized classic clusters are better suited for production workloads that require predictable performance and cost control.
These are our initial findings from analyzing a number of jobs on serverless and optimized classic compute clusters. As the feature matures, and the vendor implements feedback from the field, we will be sure to see improved performance. Ultimately, though, every job is unique, and what might work for one might not for another. Our overall recommendation is to A/B test your optimizations to understand what works for your jobs.
Conclusion
Effective management of Databricks Jobs clusters is essential for controlling costs and maximizing performance of your data infrastructure. By following these best practices and leveraging an automated solution like Gradient, organizations can achieve significant savings in costs and engineering time. They can also increase team productivity and happiness by freeing data engineers from the soul-crushing task of cluster optimization.
We hope you find these tips and tactics helpful. By implementing these insights, your organization can navigate the complexities of Databricks cluster management and unlock new efficiencies while reducing compute costs.
We know that this stuff is confusing, and we’re here to help! If you’d like to schedule a deep dive into your specific data pipelines and use-case, please book a meeting with us here.
 Kartik Nagappa
Kartik Nagappa