Adding an AI agent to your data infrastructure in 2025

Learn how Gradient reimagines compute management through ML powered optimization.

Imagine a world where you could simply tell your data infrastructure what you want it to achieve, rather than meticulously configuring every detail. This is precisely what Jeff Chou, Co-founder and CEO of Sync, discussed in the latest daily.dev webinar. This innovative concept is being made real through Gradient, the AI agent for data infrastructure from Sync.
Tune into Jeff below to learn how Gradient can help you save up to 50% on compute, or read on for key points.
The resource allocation problem
Cloud resource allocation is one of the toughest challenges at the heart of modern computing. These days, when a data engineer wants to submit a job on the cloud they need to specify the compute resources for that job. While that might not sound like a heavy lift, cluster configuration involves determining the instance type, cluster size, number of nodes, memory, and a bunch of other low-level configurations.
Manual cluster tuning is time-consuming and error-prone. It relies on a trial-and-error process of finding the right configuration to support the job. Once this is achieved, the configuration typically stays that way until the job is flagged for review, e.g. it begins to fail, is one of the more expensive jobs, or runtime/cost anomalies are detected.
Thankfully, there is a better way. One that also transforms data infrastructure from static to dynamic using AI automation. We call it “Declarative Computing.”
Introducing Declarative Computing
Declarative computing is a paradigm that enables data engineers to focus on business goals rather than on resource allocation. Instead of manually tuning clusters, engineers can specify the desired outcome – job runtime or cost, for example – and that will determine what the cluster looks like.
This approach simplifies the process for users, enabling teams to regain the engineering hours that would have otherwise been spent spinning up and tuning clusters. It also leads to more efficient resource utilization resulting in cost savings and improved efficiency.
Learn more: What is Declarative Computing?
We built Gradient, an AI agent for data infrastructure, based on the principles of Declarative Compute. It leverages advanced machine learning algorithms to choose the best cluster configurations for your data pipelines, based on your goals.
Simply declare your objectives and Gradient will automatically find the optimal configuration to minimize costs, meet critical runtime SLAs, or achieve target accuracy metrics for AI models. Gradient ensures your configuration is always optimal, by continuously monitoring and adapting to changes in your data pipelines.
How Gradient works
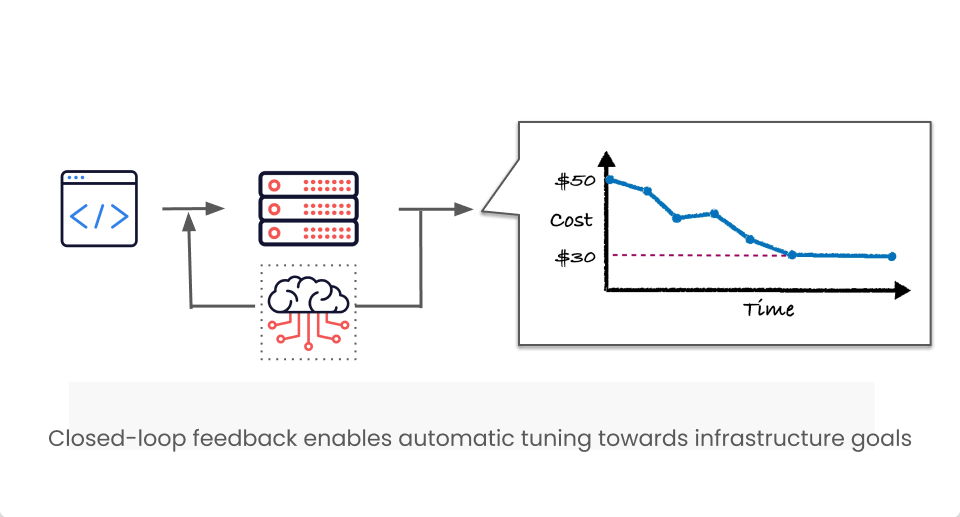
Gradient operates on a closed-loop feedback system, which is what enables it to automatically adapt to changes in production workloads. After each job run, cost and performance information are fed back into Gradient’s ML models. Based on this data and cloud configuration information, the model adjusts its projections and recommendations for optimizations, until the optimal configuration is found for each job.
Gradient starts by making small changes to configuration and assessing their impact on both job costs and performance. Each optimization is based on the impact of the previous ones. Gradient continuously monitors data pipelines so that it can seamlessly adapt to changes or anomalies. As a result, it averages thousands of optimizations per workload every month, far beyond what any data engineer can do by hand. The AI agent enables a single engineer to optimize thousands of jobs.
Key features and capabilities:
1. Goal-based optimizations: By default, Gradient will optimize your jobs for minimal costs. But you can input your desired runtime SLA, and Gradient will configure your jobs to meet them at the lowest price.
2. Continuous improvements: Gradient seamlessly adapts to changing conditions, such as fluctuating data sizes, or sudden spikes in demand, ensuring your data pipelines are always as efficient and cost effective as possible.
3. Built for scale: Gradient excels at scale, when you are managing hundreds of jobs in production. Start out with a co-pilot that recommends optimizations that an engineer can review and click to apply, or turn on autopilot mode in a click for optimization at scale.
Real-world impact
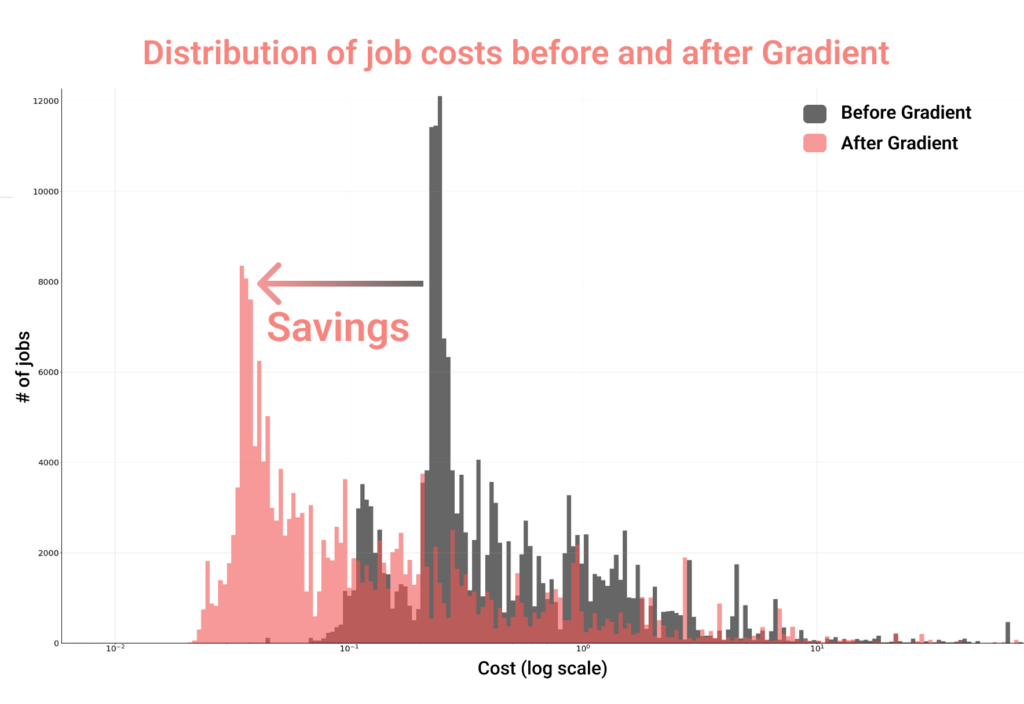
Organizations of different industries and backgrounds have achieved considerable cost savings with Gradient. In fact, across the millions of core-hours Gradient has managed for customers, we typically see cost savings in the 30-60% range for production workloads.
You can see a couple of interesting data points in the graph above. This graph charts out the distribution of job costs customers have seen before and after implementing Gradient. Note that:
- The average job has seen cost savings
- The customers with the most jobs saw the most significant cost savings. In fact, there is a 87% difference between the costs of the most expensive jobs before and after Gradient.
Related: Databricks compute comparison: Classic Jobs vs Serverless Jobs vs DBSQL
Addressing the serverless question
Databricks launched its serverless compute offering last year and it has been promoting it as a cost efficient, managed solution. However, something to be aware of in general is that serverless offerings tend to come at a premium. It is the cost of convenience. You will no longer spend time configuring your data infrastructure that is managed by the data cloud.
In our latest benchmark study, we compared the performance of Gradient optimized classic clusters with those of Databricks serverless options. Some of our findings might surprise you:
- Optimized classic clusters were substantially cheaper than serverless alternatives
- In some cases, cost savings of up to 5x were observed with classic clusters
- Overall the cost of Gradient optimized Classic < DBSQL < Jobs serverless
These findings highlight that while serverless has its place, companies operating at scale and prioritizing cost-efficiency may find significant value in Gradient’s optimization capabilities.
It’s also worth noting that serverless is still in its early days, so we expect costs to come down over time. That said, we still expect it will be a premium feature, used by companies that are willing to pay for the convenience of a managed infrastructure.
Looking ahead: The future of AI in Infrastructure

As we start the new year and look beyond, our targets are set on expanding Gradient. Expanding from Databricks to other data platforms like Snowflake, AWS EC2, Lambda, Kubernetes, and even GPUs in the cloud.
In the years to come, we hope to see more AI agents in infrastructure management. For the most part, infrastructure management is still mostly static. There is no reason to not leverage machine-learning and AI agents to make it dynamic. We hope to see more projects in this field.
Conclusion
Declarative computing, best embodied by Gradient, represents a massive leap forward in how we think about data infrastructure management. Letting engineers declare business outcomes rather than allocate resources, will unlock the next levels of efficiency and cost-effectiveness in cloud computing.
As we move into an era where AI agents become increasingly integrated into our infrastructure, Gradient will be integral to helping enterprises navigate the modern data ecosystem. The ability to automatically optimize and adapt to changing conditions will be key to staying competitive in a rapidly evolving technological landscape. Not to mention the ability to optimize at scale.
Interested in learning more about Gradient? Book your personalized demo!
 Kartik Nagappa
Kartik Nagappa