
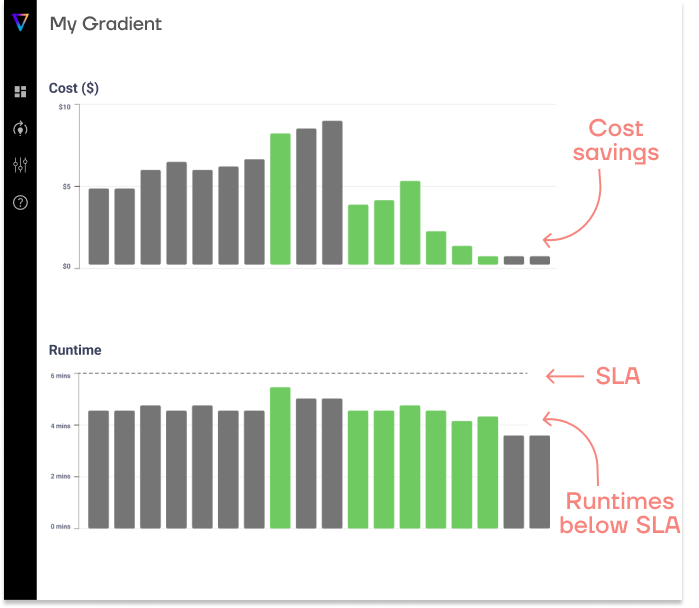
Save up to 50% on compute!
Save on compute while meeting runtime SLAs with Gradient’s AI compute optimization solution.

According to Wavestone’s 2024 Data and AI Leadership Executive Survey, about 82.2% of data and AI leaders report that their organizations are increasing investments in data and analytics. As companies increasingly rely on big data, the significance of efficient data processing solutions and optimal configuration of clusters become even more crucial.
Choosing the correct cluster type for your Databricks Jobs requires considering factors like workload, budget, and performance needs. In this post, we explore the types of clusters in Databricks, ideal use cases for each, and strategies for maximizing their efficiency while lowering the costs of your data infrastructure.
A cluster is a group of virtual machines (VMs), computation resources, and configurations that work together as a joint computing environment. In Databricks, these compute resources are used to run notebooks and data pipelines. Databricks leverages the customer’s existing cloud infrastructure. By integrating Databricks with a cloud provider, such as Azure or AWS, users are able to utilize their current cloud resources while leveraging Databricks’ powerful data processing capabilities.
Clusters are designed to process large amounts of data in parallel, improving both speed and planning. Each node in a cluster is a machine that handles a portion of the overall data processing task, allowing multiple tasks to run simultaneously so the workload completes faster. Some examples of data workloads these clusters execute include machine-learning jobs, ad-hoc analytics, streaming analytics, and ETL processes.
In Databricks, clusters can be modified to meet the specific needs of your data workloads. The right configuration, from the size of the cluster to the market (i.e. spot vs on-demand), can significantly affect performance, scalability, and cost efficiency.
Let’s dive into the various types of clusters, pricing options, and best practices to help you choose the best cluster configuration for your Databricks Jobs.
In Databricks, clusters consist of two primary types of nodes: workers and a driver.
Choosing the right configuration of worker and driver nodes can be complex due to the vast amount of options available. You also need to take into account the cluster size – more about that later. Lastly, factors such as workload requirements, performance needs, and cost considerations must be taken into account when selecting node types and sizes.
To ensure you are only paying for the resources you need, Gradient offers AI-powered cluster optimization. Gradient assists users in configuring clusters by providing insights and recommendations for optimization based on specific workload characteristics. These recommendations can be reviewed and applied in a click, or fully automated for scale.
Save on compute while meeting runtime SLAs with Gradient’s AI compute optimization solution.
Each cluster has the following attributes:
Generally, clusters can be accessed through two primary pricing models: Spot instances and on-demand clusters. The right choice depends largely on your workload requirements and your budget.
As a rule of thumb, we do not recommend running crucial production jobs on spot instances, as they might be interrupted or even terminated without notice.
Spot instances leverage unused capacity from cloud providers, such as AWS and Azure. These instances are typically much cheaper than on-demand clusters, saving up to 90% of the cost compared to on-demand pricing. The trade-off is that the cloud provider can terminate these instances without notice, or pull away resources (workers) causing the jobs to stall or even fail.
On-demand clusters, on the other hand, provide guaranteed availability of resources and are ideal for mission-critical production workloads that cannot afford interruptions. With on-demand clusters, you pay for the resources you use, but you’re assured that the computing power will be available whenever you need it. These clusters are the most reliable option for production environments and time-sensitive tasks.
Related case study:
Learn how an AdTech company saved 300 eng hours and $10K with Gradient
Databricks cluster node types are designed for specific use cases, with the two main categories being All-Purpose Compute and Job Clusters.
All-purpose compute (APC) clusters are designed to support interactive tasks, such as exploratory data analysis, development, and real-time model training. These clusters stay running until manually terminated, providing continuous access to computing resources for tasks that require flexibility and responsiveness. They can also be used as a shared resource, which makes them ideal for research and exploratory processes.
Jobs compute clusters, unlike all-purpose compute clusters, are provisioned specifically to execute automated, batch workloads. Once the job is complete, the cluster is automatically terminated, making this type of cluster cost-effective for scheduled tasks and periodic data processing jobs. In fact, we found that APC clusters can cost up to 50% more than Job clusters, for the same batch workload.
Selecting the right cluster size is one of the most important aspects of configuring your Databricks cluster. Unfortunately, the data cloud doesn’t make it easy. There is a wide variety of cluster size options and combinations available. Some are optimized for storage, others for memory, compute, GPU acceleration, or general purpose.
The size of the cluster should depend on the complexity of the workload and the amount of data being processed. However, we’ve found that more often than not an engineer will spin up a cluster that is “large enough” to support a workload, prioritizing reliability over cost efficiency. The issue is that once the cluster is configured and the job starts running, the configuration will not likely be reviewed soon, unless the job is one of the expensive ones, or it starts to fail. This situation at scale could cost an organization dearly.
Getting a better understanding of the options available is the first step to combating the issue.
Best for: Testing, learning, and small-scale data processing
Advantages: Cost-effective, easy to manage, and shared resources (allowing for significant increase in speed over distributed computing in cases where latency to shared resources matters).
Limitations: Limited processing power, cannot handle large datasets or complex workloads, not designed for shared use.
Best for: Development, testing, and small-scale data processing.
Advantages: More affordable, easier to manage.
Limitations: Limited processing power, and possible memory constraints.
Best for: Production workloads, and medium-sized datasets.
Advantages: A good balance of performance and cost.
Limitations: Higher operational costs compared to smaller clusters.
Best for: Big data processing and complex analytics.
Advantages: High scalability and performance for large datasets and intensive workloads.
Limitations: Higher cost, requires careful resource management to avoid inefficiencies.
Save on compute while meeting runtime SLAs with Gradient’s AI compute optimization solution.
Databricks offers serverless compute, a recent enhancement that eliminates cluster management for workloads with a managed solution. Serverless compute automatically provisions, scales, and terminates resources, simplifying workload management.
With that said, serverless offerings tends to be premium features built for organizations that are willing to pay for the convenience. And while Databricks serverless compute is still early on and we can expect costs to decline with time, it will most likely remain a premium feature.
Learn more the cost of serverless compute vs Databricks optimized clusters.
Databricks offers a couple advanced features built to help users optimize their compute.
Photon is Databricks’ next-generation query engine that improves workload performance by utilizing native vectorized execution. With Photon, you can significantly reduce query times and improve overall performance, however, it is more expensive, typically costing 2x a DBU. Photon will probably be faster than non-photon, but whether or not it’s cheaper will depend on how much faster it is relative to the cost increase.
Autoscaling automatically adjusts the size of your cluster based on workload demand, ensuring that you have the resources to complete your job. But are you overprovisioning? This is something autoscaling doesn’t help with. We compared Gradient optimized job clusters to job clusters running autoscaling and found that Gradient outperformed autoscaling for cost by roughly 40%.
| Feature | All-Purpose Compute | Jobs Compute |
| Purpose | 💬 Interactive tasks | 🤖 Automated batch jobs |
| Lifecycle | 🖐️ Manual start/stop | 🌫️ Ephemeral |
| Access | 👥 Multi-user | 👤 Single-use |
| Use Cases | 🔍 Data exploration and prototyping | 📊 ETL and model training |
| Resource Configuration | 🔄 Flexible | 🎯 Job-specific |
| Cost Efficiency | 💸 Higher cost | 💵 Cost-effective |
| Interactivity | ⚡ High | 💤 Low |
All-purpose clusters are designed for flexibility and collaboration, making them ideal for interactive tasks such as data exploration and development. They remain active until manually terminated, allowing multiple users to work simultaneously on the same cluster. This setup is particularly beneficial for teams that require ongoing access to computational resources.
In contrast, Jobs Compute clusters are optimized for running automated, batch workloads. These clusters are ephemeral, created specifically for a job and terminated once the job is completed. This makes them a cost-effective choice for scheduled tasks like ETL processes and model training, where interactivity is not required.
By configuring resources according to job specifications, organizations can achieve greater efficiency and save costs. This is precisely what Gradient helps organizations with, automatically ensuring their data infrastructure is as efficient as possible.
Choosing the right cluster configuration for your data pipelines in Databricks is a critical decision that can impact the performance, cost, and reliability of your data infrastructure. By understanding the different cluster types, pricing models, and configuration options available, you can make informed decisions that line up with your organization’s needs. When configuring a cluster for Databricks, remember to consider your workload characteristics, business requirements, and technical constraints.
Whether you’re using spot clusters for cost efficiency, on-demand clusters for reliability, or optimizing your setup with advanced features like Photon and autoscaling, Databricks provides your with granular options to manage your data processing workloads. They might even be too granular for most users.
If you find the sheer volume of options confusing, or simply don’t have the time for the trial and error process of tuning a cluster to your needs, we can help. Gradient is a purpose-built compute optimization system. It uses advanced, self-improving algorithms to offer 100% custom cluster optimizations based on the unique characteristics of your data pipelines and requirements.
Interested in seeing Gradient in action?
 Kartik Nagappa
Kartik Nagappa