Integrating Gradient with Terraform

Balancing Infrastructure as Code with AI-powered optimization

Infrastructure as Code (IaC) has revolutionized how we manage cloud resources, with Terraform emerging as the leading tool for this approach. The ability to define, version, and automate infrastructure through code has transformed operations from manual, error-prone processes into systematic, repeatable workflows. However, cluster configurations defined in Terraform are typically over-provisioned to guarantee performance and stability, leading to unnecessary costs. Optimizing these clusters to dynamically match workload requirements while meeting business constraints around cost and SLAs requires continuous, iterative cluster tuning.
This creates an interesting challenge: how do we maintain the benefits of Infrastructure as Code while allowing for dynamic optimization? The key lies in carefully modifying Terraform’s drift detection capabilities.
The challenge of manual cluster optimization
Traditionally, teams face a common anti-pattern when managing Spark clusters: manual intervention in cluster configurations. This typically manifests as:
- Engineers making direct changes to cluster sizes based on performance observations
- Emergency resource adjustments during peak workload periods
- One-off modifications that never make it back into the infrastructure code
- Inconsistent configurations across different environments
These manual interventions create drift between the actual infrastructure state and what’s defined in code, leading to runaway costs, confusion, inconsistency, and potential failures during future deployments. Thankfully, Terraform’s drift detection can be used to counter this anti-pattern and reset infrastructure back to its original configuration.
Enter Gradient: AI for your data infrastructure
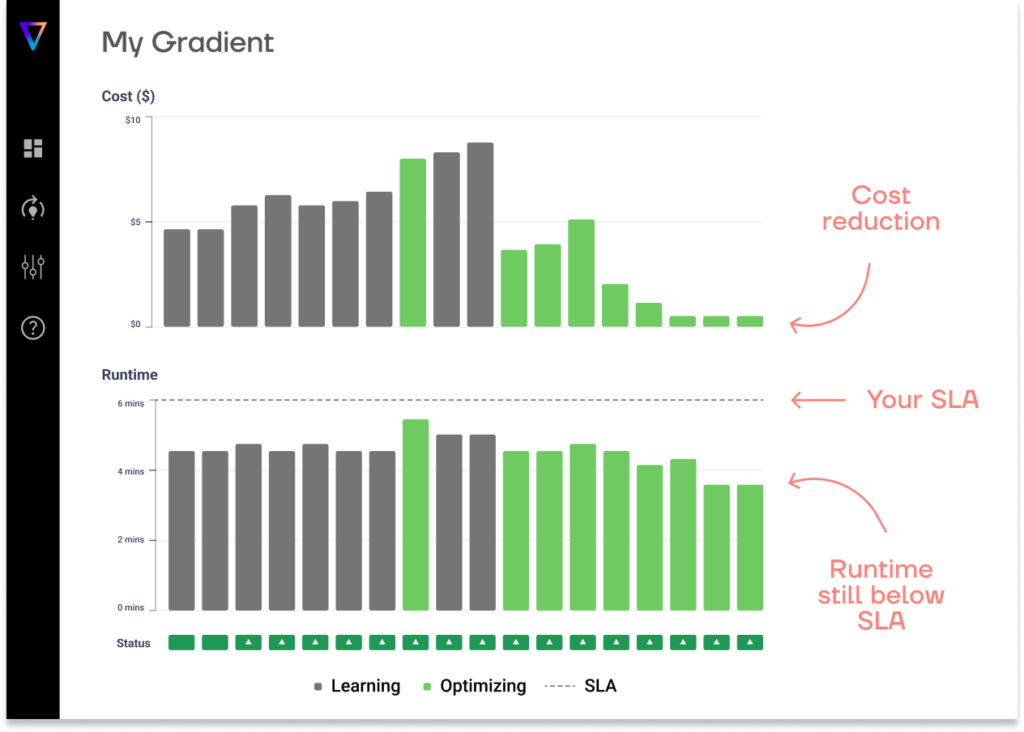
Gradient transforms manual cluster tuning into automated, code-driven workflows that aligns with Terraform best practices. Instead of relying on human judgment and manual adjustments, Gradient provides AI-powered infrastructure recommendations that continuously optimize Spark workload performance to meet cost and runtime requirements.
Lean how Gradient continuously optimizes Spark jobs for costs and performance.
Modifying Terraform for Gradient integration
Here’s where things get interesting: While Terraform’s drift detection is designed to prevent unwanted infrastructure changes, this default behavior needs a simple tweak to work with Gradient. By default, Terraform will detect Gradient’s optimizations as drift and attempt to revert them to the original configuration – so we’ll use Terraform’s built-in lifecycle configuration to allow Gradient’s AI-powered optimizations to work their magic.
To avoid this situation, the drift detection needs to be adjusted. Follow these three key steps to integrate Gradient with Terraform:
- Set up Databricks webhook notifications: Include Workspace and Job Configuration in your Terraform plan
- Tweak Terraform drift detection: Configure Terraform to ignore recommendation fields when detecting drift
- Automate compute optimization: Enabling Gradient to auto-apply AI-powered cluster optimizations directly to your Databricks Jobs
Setting up Databricks webhook notifications
First, set up a webhook notification destination that Gradient will use to monitor job starts:
resource "databricks_notification_destination" "sync_webhook" {
display_name = "Notification Destination"
config {
generic_webhook {
url = "https://example.com/webhook"
username = "username" # Optional
password = "password" # Optional
}
}
}Next, configure your Databricks jobs to use this webhook:
resource "databricks_job" "example_job" {
name = "example job"
# ... other configurations ...
webhook_notifications {
on_start {
id = databricks_notification_destination.sync_webhook.id
}
}
}Managing Terraform drift with Gradient
There are two approaches to handling drift detection with Gradient:
Option 1: Ignore entire cluster configuration
resource "databricks_cluster" "single_node" {
cluster_name = "Single Node"
spark_version = data.databricks_spark_version.latest_lts.id
node_type_id = data.databricks_node_type.smallest.id
autotermination_minutes = 20
spark_conf = {
"spark.databricks.cluster.profile" : "singleNode"
"spark.master" : "local[*]"
}
custom_tags = {
"ResourceClass" = "SingleNode"
}
lifecycle {
ignore_changes = all
}
}Option 2: Ignore specific gradient-managed configurations
resource "databricks_cluster" "example_cluster" {
cluster_name = "example-cluster"
spark_version = "7.3.x-scala2.12"
node_type_id = "i3.xlarge"
num_workers = 2
custom_tags = {
"sync:project-id" = "<insert-project-id>"
}
lifecycle {
ignore_changes = [
num_workers,
node_type_id
# Note: Gradient also modifies EBS volumes
]
}
}Automating compute optimization
Gradient offers two approaches for applying AI-powered recommendations for compute optimization:
- Autopilot/Auto-Apply Feature: Enable this through the “Edit settings” button in the Gradient project page. When enabled, AI-powered recommendations are automatically applied after each job run. Note that this feature only works with Databricks Workflows and is not available for DatabricksSubmitRunOperator, or the Databricks Jobs API 2.1.
- Copilot/Programmatic Integration: Use the Gradient Python library to retrieve and apply recommendations:
sync.api.projects.get_latest_project_config_recommendation(project_id: str)Best practices for Gradient-Terraform integration
- Choose the right drift management strategy
- Consider using specific ignore_changes rather than ignoring all changes
- Document which configurations are managed by Gradient’s AI optimization
- Regularly review ignored configurations to ensure they align with Gradient’s current capabilities
- Webhook configuration management
- Store webhook credentials securely
- Monitor webhook health and connectivity
- Implement proper error handling for webhook failures
- Version control
- Track your baseline configurations in version control
- Document Gradient’s optimization boundaries
- Maintain a changelog of any manual overrides
- Monitoring and governance
- Implement monitoring for both Terraform and Gradient changes
- Set up alerts for unexpected configuration changes
- Regularly audit optimization patterns
Related reading: Gradient’s advanced monitoring and insights
Conclusion
Integrating Gradient with Terraform represents an evolution in infrastructure management – combining the reliability and repeatability of Infrastructure as Code with the intelligence of AI-powered optimization. By configuring Terraform to work alongside Gradient, teams can maintain the benefits of IaC while leveraging automated, AI-driven optimization for their Spark workloads.
Remember: the goal isn’t to abandon infrastructure governance, but to create a controlled space where AI-powered optimization can occur within well-defined boundaries. This approach ensures that your infrastructure remains both well-managed and optimally configured for performance.
Interested in learning more?
Book a time to meet with the team to discuss your data needs!
 Jeffrey Chou
Jeffrey Chou
 Noa Shavit
Noa Shavit