
Book a free 30-min consultation
For a comprehensive review of your Databricks workspace by an expert.
Databricks’ DLT offering showcases a substantial improvement in the data engineer lifecycle and workflow. By offering a pre-baked, and opinionated pipeline construction ecosystem, Databricks has finally started offering a holistic end-to-end data engineering experience from inside of its own product, which provides superior solutions for raw data workflow, live batching and a host of other benefits detailed below.
Since its release in 2022 Databricks’ Delta Live Tables have quickly become a go-to end-to-end resource for data engineers looking to build opinionated ETL pipelines for streaming data and big data. The pipeline management framework is considered one of most valuable offerings on the databricks platform, and is used by over 1,000 companies including Shell and H&R block.
As an offering DLT begins to look similar to the DBT value proposition, and with a few changes (namely, jinja templating), DLT may be poised to expand more into what has traditionally been considered DBT’s wheelhouse. DLT is also positioned to begin consuming workloads that were previously handled by multiple separate orchestration, observability, and quality vendors.
In our quest to help customers manage, understand, and optimize their Databricks workloads, we sought out to understand the value proposition for both customers, and for Databricks. In this post, we break down DLT as both a product offering as well as it’s ROI for customers.
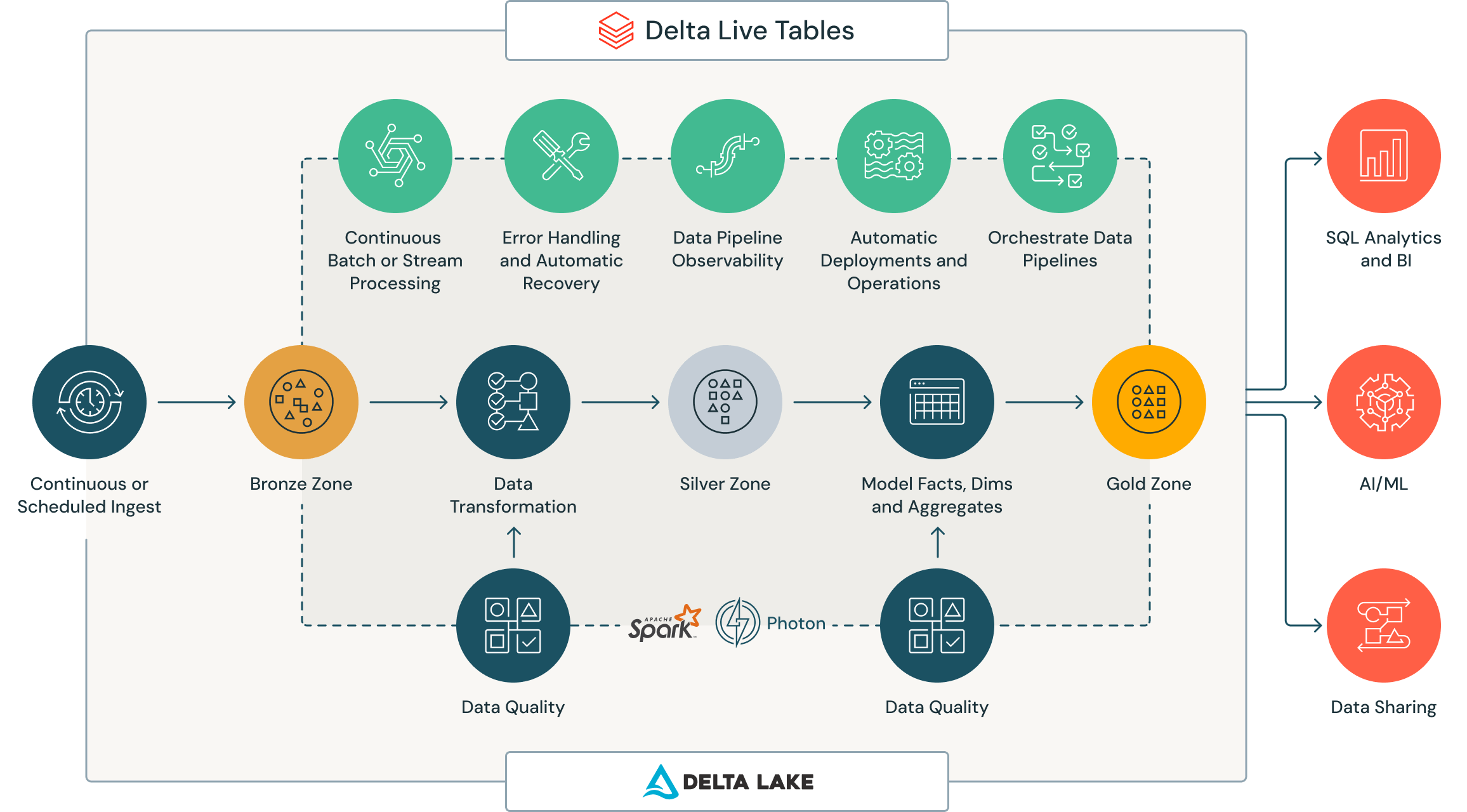
Delta Live Tables, or DLT, is a declarative ETL framework that dramatically simplifies the development of both batch and streaming pipelines. Concretely though, DLT is just another way of authoring and managing pipelines in databricks. Tables are created using the @dlt.table() annotation on top of functions (which return queries defining the table) in notebooks.
Delta Live Tables are built using Databricks foundational technology such as the Delta Lake and Delta File format. As such, they operate in conjunction with these two. However, whereas these two focus on the more “stagnant” portions of the data process, DLT focuses on the transformation piece. Specifically, the DLT framework allows data engineers to describe how data should be transformed between tables in the DAG.
Delta Live Tables are largely used to allow data engineers to accelerate their construction, deployment, and monitoring of a data pipeline.
The magic of DLT, though, is most apparent when it comes to datasets that both involve streaming data and batch processing data. Whereas, in the past, users had to be keenly aware of and design pipelines for the type of the “velocity” (batch vs. streaming) of data transformed, DLT allows users to push this problem to the system itself. Meaning, users can write declarative transformations and let the system figure out how to handle the streaming or batch components. Operationally, Delta Live Tables add an abstraction layer over Apache Spark (or at least Databricks’ flavor of Spark). This layer provides visibility into the table dependency DAG, allowing authors to visualized, what can rapidly become inter-table dependencies. .
The DAG may look something like this:
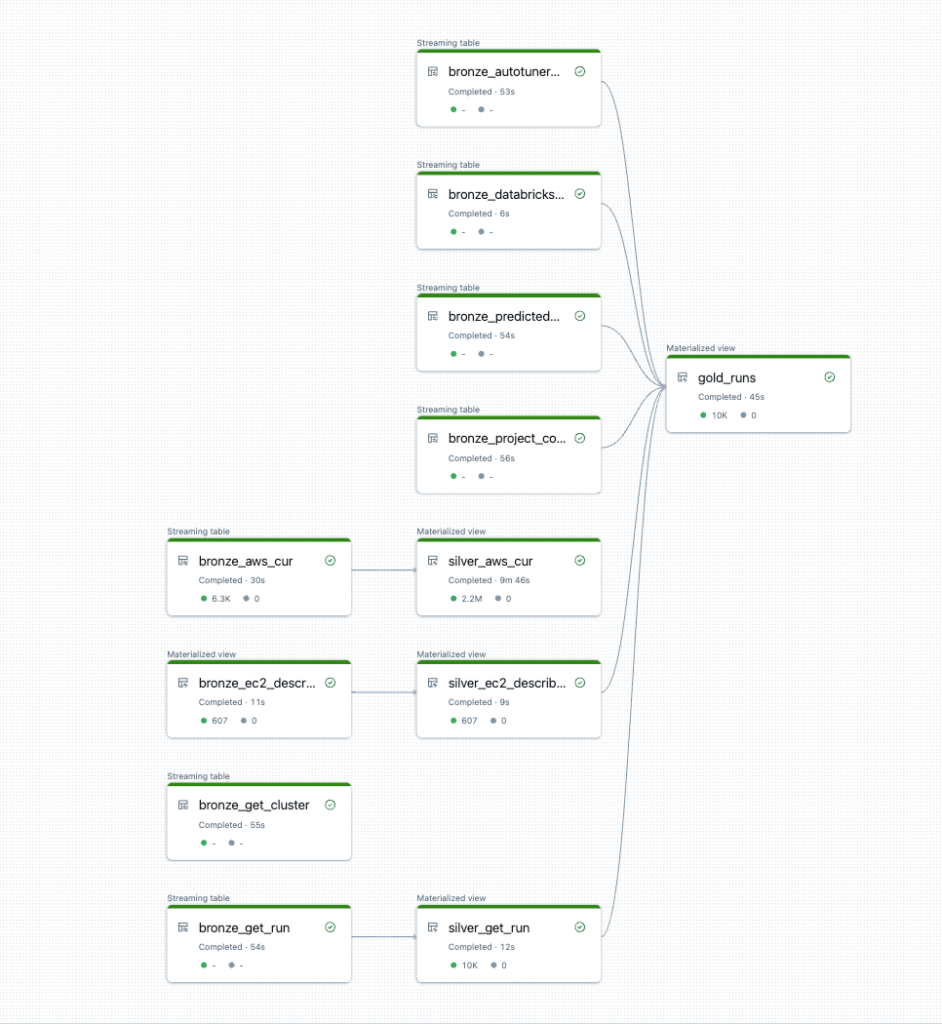
Table dependency visualization is just the beginning. DLT provides a comprehensive suite of tools on top of these pipelines that are set up by default. This can include tools such as data quality checks, orchestration solutions, governance solutions, and more.
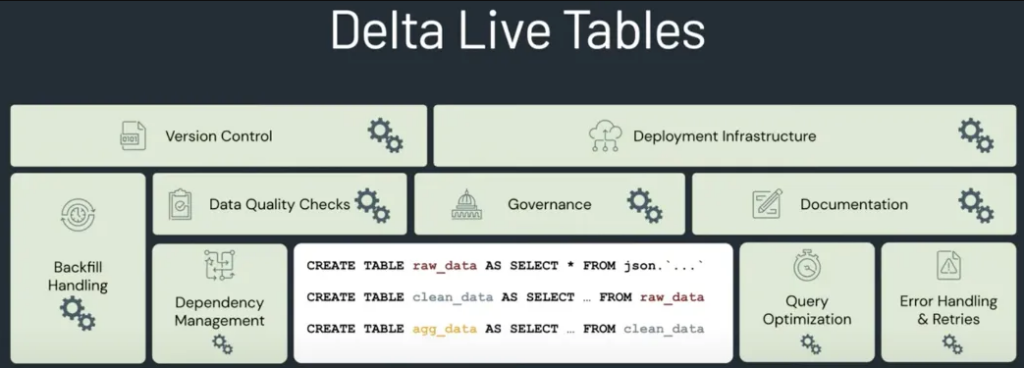
When executed properly, DLT helps with total cost-of-ownership, data accuracy and consistency, speed, and pipeline visibility and management. There are many who actually say that DLT is Databricks’ foray into the world of DBT, hoping to cannibalize DBT’s offering. To the question of how this may all play out, we’ll just wait and see.
The word “Delta” appears a lot in the Databricks ecosystem, and to understand why, it’s important to look back at history. In 2019, Databricks publicly announced the Delta Lake, a foundational element for storing data (tables) into the Databricks Lakehouse. Delta Lake popularized the idea of a Table Format on top of files, with the goal of bringing reliability to data lakes. As such, Delta Lake provided ACID transactions, scalable metadata handling, and unified streaming/batch processing to existing Data Lakes in a Spark API compatible way.
Tables that live inside of this Delta Lake are written using the Delta Table format and, as such, are called Delta Tables. Delta Live Tables focus on the “live” part of data flow between Delta tables – usually called the “transformation” step in the ETL paradigm. Delta Live Tables (DLTs) offer declarative pipeline development and visualization.
In other words, Delta Table is a way to store data in tables, whereas Delta Live Tables allows you to describe how data flows between these tables declaratively. Delta Live Tables is a declarative framework that manages many delta tables, by creating them and keeping them up to date. In short, Delta Tables are a data format while Delta Live Tables is a data pipeline framework. All are built on the data lakehouse infrastructure of Delta Lake.
Read More: Data Warehouse, Lake, and Lakehouse: Strengths and Weaknesses
For a comprehensive review of your Databricks workspace by an expert.
The core of DLT is the pipeline— the main unit of execution used to configure and run data processing workflows with Delta Live Tables. These pipelines link data sources to target datasets, through what’s known as a Directed Acyclic Graph (DAG), and are declared in Python or SQL source files. Delta Live Tables infers the dependencies between these tables, ensuring updates occur in the correct order.
Each pipeline configuration is defined by its settings, such as notebook, running mode, and cluster configuration. Before processing data with Delta Live Tables, you must configure a pipeline.
As an aside, for the developers reading this, for some reason the Databricks SDK defines a Pipeline as a List of Clusters, which either may be a preview for what to expect in new features or an oversight. We’ll find out soon.
Delta Live Table pipeline supports three types of datasets: Streaming tables, Materialized Views and Views. Streaming tables are ideal for ingestion workloads, and pipelines that require data freshness and low latency. They are designed for data sources that are append-only.
Supported views can either be materialized views where the results have been precomputed based on the update schedule of the pipeline in which they’re contained—or views, which compute results from source datasets as they are queried (leveraging caching optimizations when available). Delta Live Tables do not publish views to the catalog, so views can only be referenced within the pipeline in which they’re defined. Views are useful as intermediate queries that should not be exposed to end users or systems. Databricks describes how each is processed with the following table:
| Dataset Type | How are records processed through defined queries? |
| Streaming Table | Each record is processed exactly once. This assumes an append-only source. |
| Materialized Views | Records are processed as required to return accurate results for the current data state. Materialized views should be used for data sources with updates, deletions, or aggregations, or for change data capture processing (CDC). |
| Views | Records are processed each time the view is queried. Use views for immediate transformations and data quality checks that should not be published to public datasets. |
After defining your pipeline settings, you can declare your datasets in DLT using either SQL or Python. These declarations can then trigger an update to calculate results for each dataset in the pipeline.
Given the existence of two options to create views on top of data, there must be some situations where one should be preferred over the other. The choice of View or Materialized View primarily depends on your use case. The biggest difference between the two is that Views, as defined above, are computed at query time, whereas Materialized Views are precomputed. Views also have the added benefit that they don’t actually require any additional storage, as they are computed on the fly.
The general rule of thumb when choosing between the two has to do with the performance requirements and downstream access patterns of the table in question. When performance is critical, having to compute a view on the fly may be an unnecessary slowdown, even if some storage is saved by computing the table on-the-fly, in which case, Materialized Views may be preferred. The same is true when there are multiple downstream consumers of a particular View. Having to compute the exact same view, on the fly, for multiple tables is inefficient and unnecessary. In this case, persisting the Materialized View may be preferred.
However, there are multiple situations where users just need a quick view, computed in memory, to reference a particular state of a transferred table. Rather than materializing this table, which again, is only needed for an operation in the same transformation, creating a View is more straightforward and efficient.
Databricks also recommends using views to enforce data quality constraints or to transform and enrich datasets that drive multiple downstream queries.
There are many benefits to using a Delta Live Table, including simpler pipeline development, better data quality standards, and support for unified real time and batch analytics.
One of the large benefits of Delta Live Tables is the ability to use Change Data Capture while streaming data. Change Data Capture refers to the tracking of all changes in a data source so they can be captured across all destination systems. This allows for a level of data integrity and consistency across all systems and deployment environments which is a massive improvement.
With Delta Live Tables, data engineers can easily implement CDC with new Apply Changes into the API (either with Python or SQL). The capability lets ETL pipelines easily detect source data changes and apply them to data sets throughout the lakehouse.
Importantly, Delta Live Tables support Slowing Changing Dimensions (SCD) both type 1 and type 2. This is important because SCD type 2 retains a full history of values, which means even in your data lakehouse, where compute and storage are separate, you can retain a history of records—either on all updates or on updates to a specified set of columns.
In SDC2, when the value of an attribute changes, the current record is closed, a new record is created with the changed data values, and this new record becomes the current record. This means if a user entity in the database moves to a different address, we can store all previous addresses for that user.
This implementation is of great importance to organizations that require maintaining an audit trail of changes.
As with all things Databricks, the cost of Delta Live Tables depends on the compute function itself (as well as cost variance by region and cloud provider). On AWS, DLT compute can range from $0.20/dbu for DLT Core Compute Photon all the way up to $0.36/dbu for DLT Advanced Compute. However keep in mind these prices can be up to twice as high when applying expectations and CDC, which are among the chief benefits of Delta Live Tables.
From an efficiency perspective, DLT results in a reduction in total cost of ownership. Automatic orchestration tests by Databricks have shown total compute time to be reduced to as much as half with Delta Live Tables–ingesting up to 1 billion records for under $1. Additionally, Delta Live integrates the orchestrator and Databricks into a single console, which reduce the cost of maintaining two different systems to maintain two solutions.
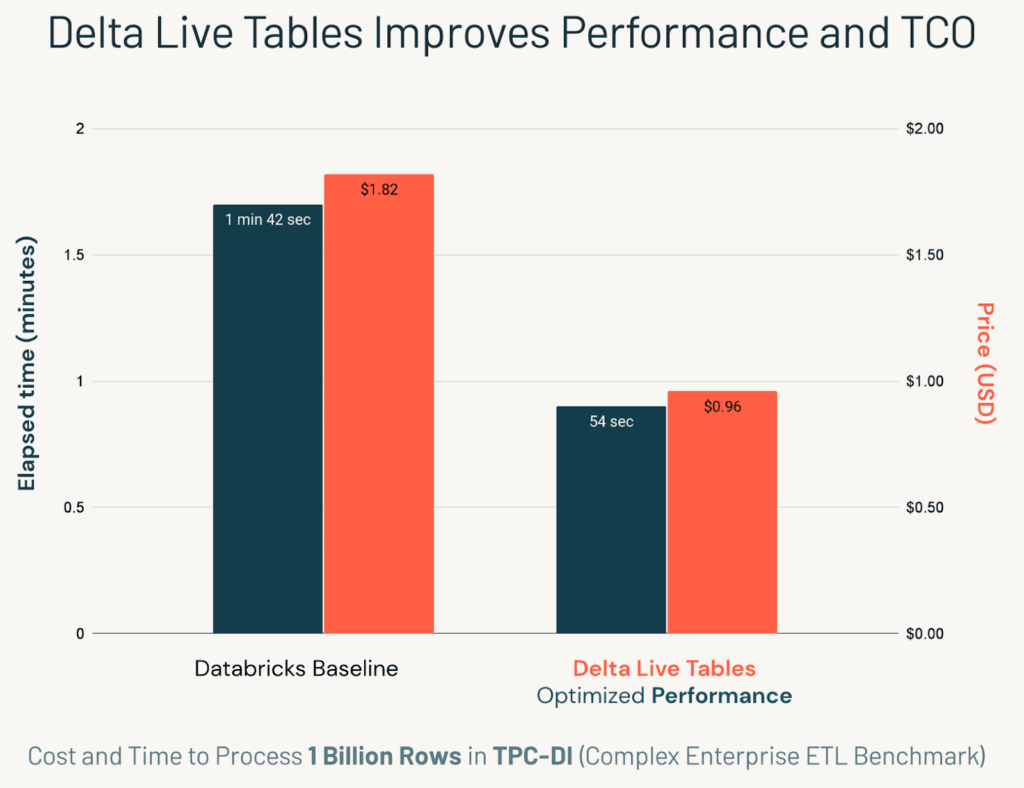
However, users should also be cautioned that without proper optimization, Delta Live Tables can result in a large increase in virtual machine instances, which is why its crucial to always maintain your auto scaling resources.
For a comprehensive review of your Databricks workspace by an expert.
 Kartik Nagappa
Kartik Nagappa
 Noa Shavit
Noa Shavit