Why Your Databricks Cluster EBS Settings Matter

How choosing the right EBS settings can reduce your Databricks cluster cost by 80%

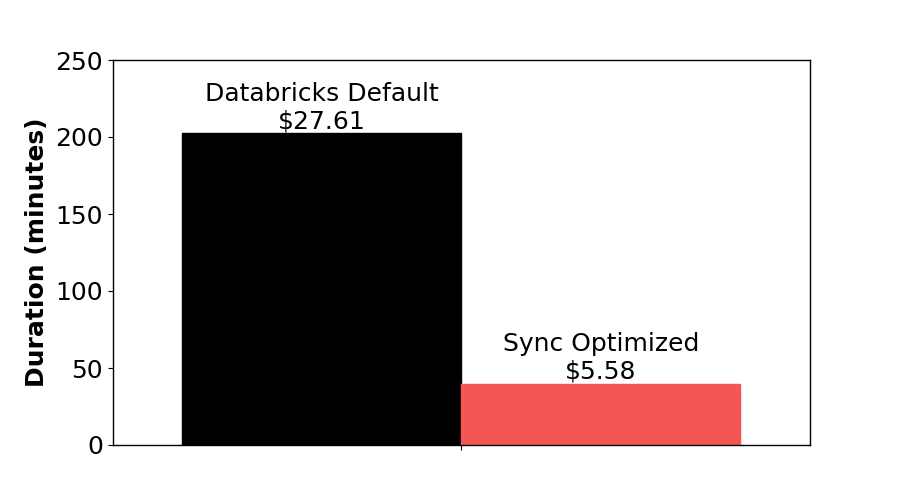
Choosing the right hardware configuration for your Databricks jobs can be a daunting task. Between instance types, cluster size, runtime engine, and beyond, there are an enormous number of choices that can be made. Some of these choices will dramatically impact your cost and application duration, others may not. It’s a complicated space to work in, and Sync is hard at work in making the right decisions for your business.
In this blog post, we’re going to dig into one of the more subtle configurations that Sync’s Gradient manages for you. It’s subtlety comes from being squirreled in the “Advanced” settings menu, but the setting can have an enormous impact on the runtime and cost of your Databricks Job. The stark example depicted in Figure 1 is the result of Sync tuning just this one setting. That setting — really a group of settings — are the EBS volume settings.
EBS on Databricks
Elastic Block Storage (EBS) is AWS’s scalable storage service designed to work with EC2 instances. An EBS volume can be attached to an instance and serves as disk storage for that instance. There are different types of EBS volumes, the three of which are relevant to Databricks:
- st1 volumes are HDD drives used in Databricks Storage Autoscaling
- gp2 volumes are SSDs, user selects the Volume count and Volume Size
- gp3 volumes are similar to gp2, but you may pay for additional throughput and IOPS separately
Apache Spark may utilize disk space, including for disk caching, disk spillage, or as intermediate storage between stages. Consequently, EBS volumes are required to run your Databricks cluster if there is no disk-attached (NVMe) storage. However, Databricks does not require a user to specify EBS settings. They exist, squirreled away in the Advanced menu of cluster creation, but if no selection is made then Databricks will automatically choose settings for you.
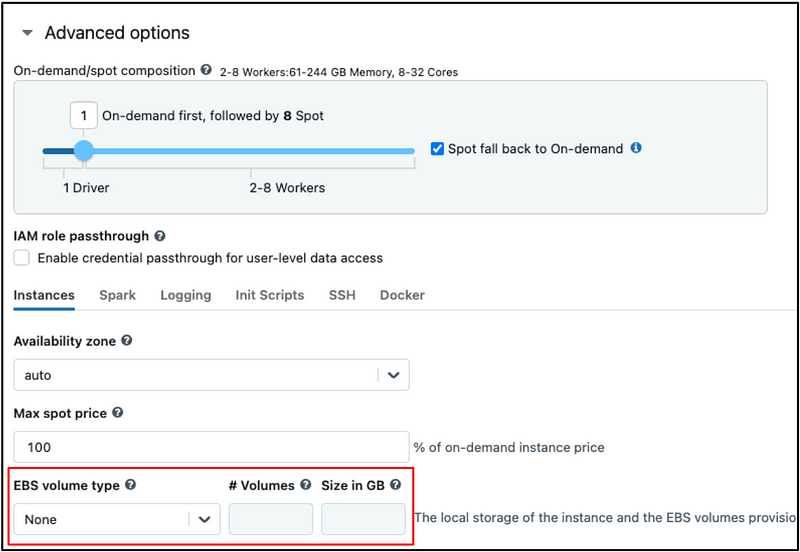
The automatic EBS settings depend on the size of the instance chosen, with bigger instances getting more baseline storage according to AWS’s best practices. While these baseline settings are sufficient for running applications, they are often suboptimal. The difference comes down to how EBS settings impact the throughput of data transfer to and from the volumes.
Take for example the gp2 volume class, where the volume IOPS and throughput are direct functions of the size of the volume. The bigger the volume size, the faster you can transfer data (up to a limit). There’s additional complexity beyond this, including bandwidth bursting and instance bandwidth limits.
So how does Sync address this problem?
Laying the Groundwork
Sync has approached this problem the same way we’ve approached most problems we tackle — mathematically. If you get way down in the weeds, there’s a mathematical relationship between the EBS settings (affecting the EBS bandwidth), the job duration, and the job cost.
The following formula shows the straightforward relationship between the EBS settings (S), the application Duration [hr], and the various charge rates [$/hr]. For clarity we write the Duration only as a function of S, but in reality it depends on many other factors, such as the compute type or the number of workers.
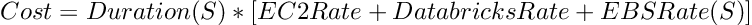
At first glance this equation is straightforward. The EBS settings impact both the job duration and the EBS charge rate. There must be some EBS setting where the decrease in duration outweighs the increase in charge rate to yield the lower possible cost.
Figure 3 exemplifies this dynamic. In this scenario we ran the same Databricks job repeatedly on the same hardware, only tuning the EBS settings to change each instance’s effective EBS throughput. An instance’s EBS throughput is the sum of the throughputs of the attached EBS volumes (ThroughputPerVolume*VolumesPerInstance), up to the maximum throughput allowed by the instance (MaxInstanceThroughput). This leads to a convenient “Normalized EBS Throughput” defined as ThroughputPerVolume*VolumesPerInstance/MaxInstanceThroughput, which we use to represent the instance EBS bandwidth.
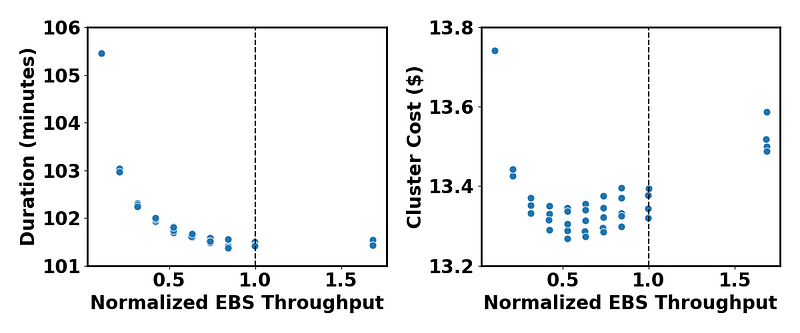
The plot on the right shows the cost for each point in the left plot. Notably, there’s a cost-optimum at a normalized throughput of ~0.5, well below the instance maximum. This is a consequence of the delicate balance between the cost rate of the EBS storage and its impact on duration. The wide vertical spread at a given throughput is due to the intricate relationship between EBS settings and throughput. In short, there are multiple setting combinations that will yield the same throughput, but those settings do not have the same cost.
Sync’s Solution
The most notable feature in Figure 3 is the smooth and monotonically decreasing relationship between duration and throughput. This is not entirely unexpected, as small changes in throughput ought to yield small changes in duration, and it would be surprising if increasing the throughput also increased the runtime. Consequently, this space is ripe for the use of modeling — provided you have an accurate enough model for how EBS settings would realistically impact duration (wink).
The downside to modeling is that it requires some training data, which means a customer would have to take deliberate steps to collect the data for model training. For GradientML we landed on a happy medium.
Our research efforts yielded a simple fact: immediately jumping to EBS settings that efficiently maximize the worker instance EBS throughput will yield a relatively small increase in the overall charge rate but in most cases results in a worthwhile decrease in run duration. When we first start managing a job, we bump up the EBS settings to do exactly this.
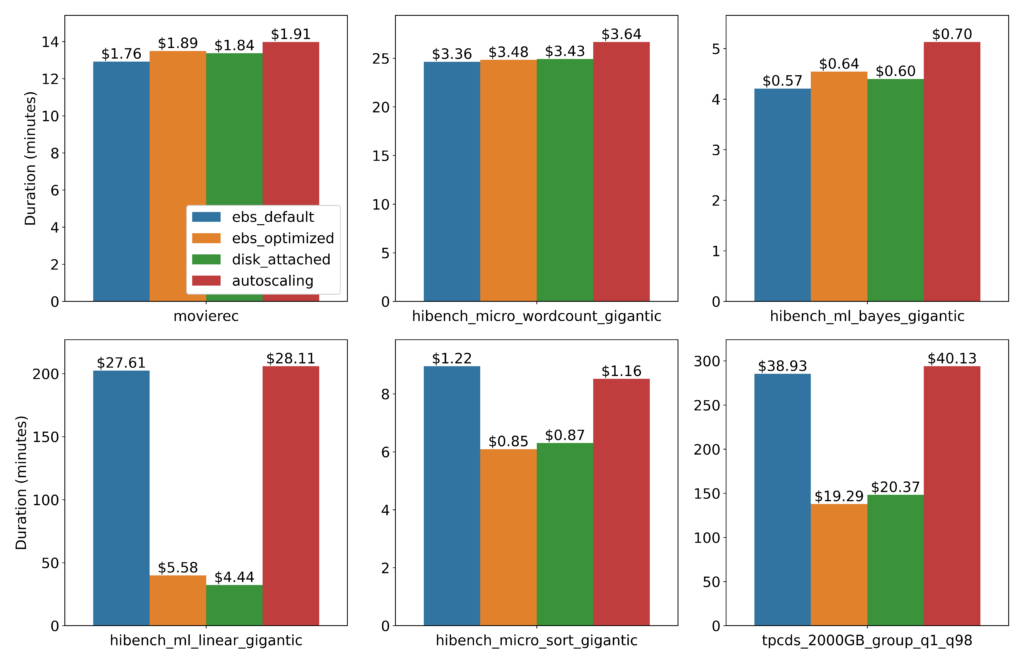
We explore the consequences of this logic in Figure 4, which depicts six different jobs where we compare the impact of different EBS settings on cost and runtime. Every job uses the same cluster consisting of one c5.24xlarge worker. In addition to the “default” and “optimized” settings discussed thus far, we also tested with autoscaled storage (st1 volumes, relatively slow HDDs), and disk-attached storage (one c5d.24xlarge worker instead, this is lightning fast NVMe storage).
The top row consists of jobs which are insensitive to storage throughput, but we see that maximizing the EBS settings did not meaningfully impact cost. In these cases data transfer to and of from storage had a negligible impact on the duration of the overall application, and so the duration was insensitive to the EBS bandwidth.
The bottom row consists of jobs where this data transfer does meaningfully impact the application duration, and are therefore more sensitive to the throughput. Coincidentally, the disk-attached runs did not show any meaningful cost reduction over the EBS-optimized runs, though this is most certainly not a universal trend.
Conclusion
With the abstraction that is cloud computing, even the simplest offerings can come with a great deal of complexity that impacts the duration and cost of your application. As we’ve explored in this blog post, choosing appropriate EBS settings for Databricks clusters is an excellent illustration of this fact. Fortunately, the smooth relationship between duration and an instance’s EBS throughput lends itself to the powerful tools of mathematical modeling — the kind of thing that Sync eats and breaths. We’ve employed this expertise not only in the analysis in this blog, but in our compute management product GradientML which manages the compute decisions in Databricks clusters, and automatically implements these optimizations on your behalf.
Related: Choosing the right Databricks cluster: Spot vs. on-demand, APC vs. Job Compute
 Kartik Nagappa
Kartik Nagappa
 Noa Shavit
Noa Shavit