Developing Gradient Part II

How Gradient save you money on Databricks and EMR

Introduction: Using Gradient in a Workflow
Gradient, the latest product release from Sync Computing, helps customers manage the infrastructure behind their recurring Apache Spark applications. Gradient gives infrastructure recommendations for each job to lower the cost of their Production jobs while hitting their target SLA’s. We’ve been hard at work on this project for a long time and we’re excited for people to use it and realize real cost savings in their Apache Spark jobs running on EMR or Databricks!
The key feature of Gradient is a Project, which in Databricks manages the lifecycle of a single Job. With the integration of Sync’s Python library, each Job run produces:
- An Apache Spark eventlog
- A “Cluster Report” that includes Databricks and EC2 API response data about that run and its associated cluster
These outputs then get fed into Gradient’s recommendation engine which performs runtime and cost prediction for that same job if it were to run on different hardware. Within Gradient’s recommendation engine there are two key steps: (1) runtime prediction modeling, and (2) cost estimation modeling. These two steps are repeated for a variety of potential hardware configurations, and then one that yields the lowest cost given some time constraint is recommended for the job run.
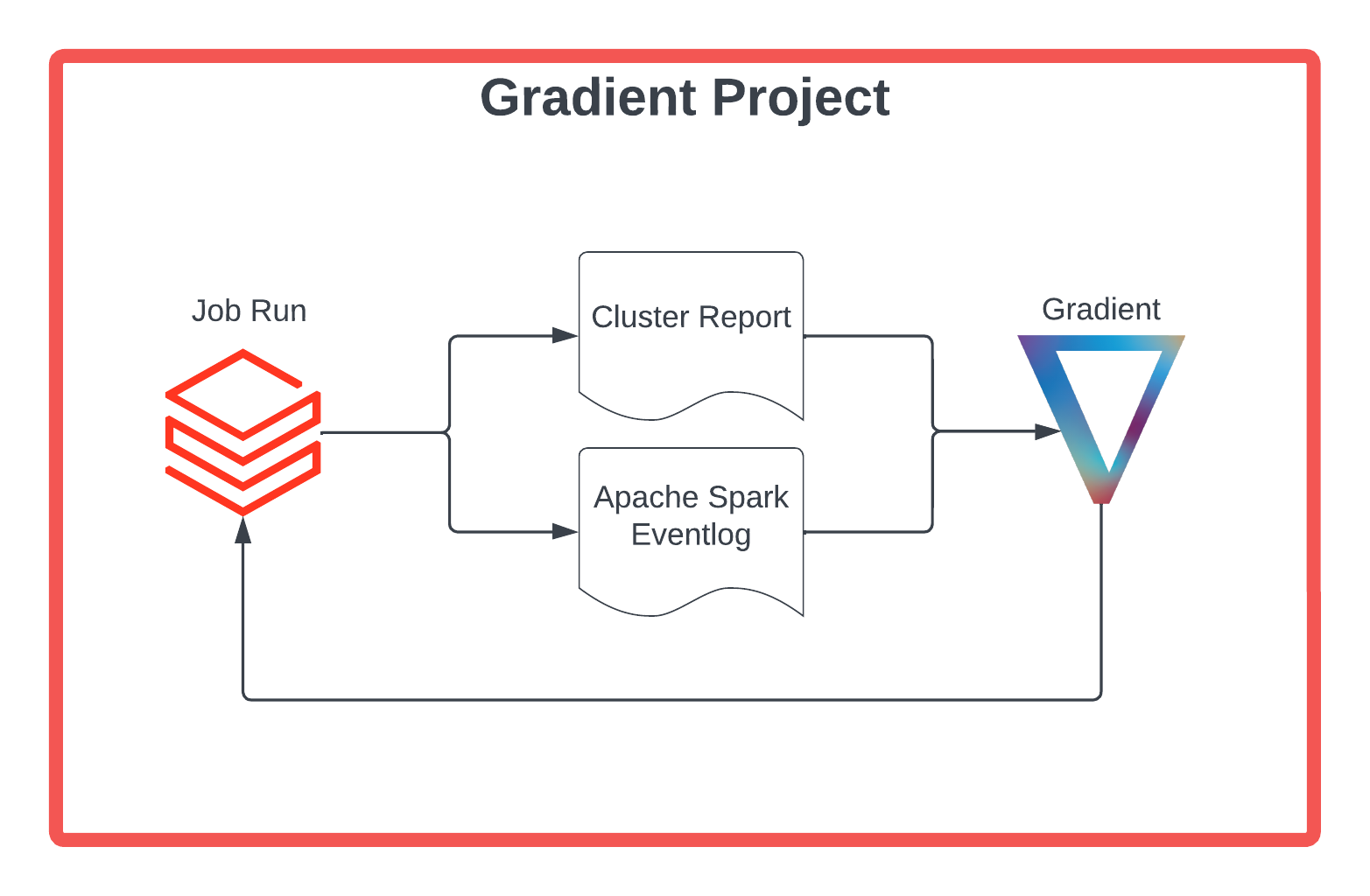
Figure: Diagram of a Gradient Project. After each Job Run a cluster report and Eventlog are produced which get fed into Gradient’s recommendation engine. The output of this process is a new cluster recommendation, one that should reduce cost while maintaining a runtime requirement, that informs the subsequent Job run.
Internal Testing
In a separate blog post [link to Part I] we discuss in some detail the internal testing process we used to develop Gradient. A huge benefit to internal testing is that we have access to the cost-actual data of each Job we run via Databricks and AWS cost and usage reporting. This data is critical in assessing whether or not Gradient behaves as it should from a customer’s perspective. In other words, do customers still save money in spite of imperfect runtime prediction and cost estimation? The answer, we found, is yes!
In the following figure we show a snapshot of data we generated that gave us great confidence in the solution we developed for Gradient. The figure displays a histogram of the percent change in cost between an initial “parent run” (with random hardware configuration), and a subsequent “child run” informed by Gradient’s recommendation engine. In total, 80% of runs showed a cost reduction, and the median cost reduction was 30%.
It’s worth emphasizing that these results are the single shot improvements going from an initial cold-start run to the first recommendation produced by Gradient. Given how complex predicting runtime is, these are excellent results, and it’s not surprising that 20% of the runs increased in cost (a less than ideal outcome). That said, it’s the feedback loop that really unlocks the capability of Gradient. Every time your Job runs more data is added to your project, and that history of runs will be used to improve the recommendation quality of future recommendations. It’s a sure bet that when you spin up your first Job there’ll be a Sync engineer assessing the quality of your recommendations!

Figure: Internal testing results show after 1 iteration through Gradient, a cost difference of jobs before and after using Gradient’s recommendation engine. Cost was reduced in 80% of runs, with a median reduction of 30% when compared to the parent run cost.
External Savings
When it comes to demonstrating value, nothing beats a positive user experience. Early customer interactions have yielded huge savings and positive experiences from a number of different companies. Wanna see their story using Gradient? Check out some of the blogs they’ve written!
- Matt Weingarten at Disney got huge savings on his EMR jobs.
- Deniz Parmaksiz of Insider Engineering also got big savings using our product
- A champion at Duolingo also reduced their Spark costs!
Conclusion
Since we first got started, Sync has felt confident that we’re tackling a real issue that’s pervasive in the cloud infrastructure world. Making infrastructure decisions and being uncertain about how to reduce costs is a ubiquitous story when we talk to folks. With Gradient we feel we finally tackled a real solution to this problem. A solution that will make the lives of developers around the world easier, enabling them to focus their efforts on more important tasks, all while saving companies money on their Apache Spark workloads.
 Kartik Nagappa
Kartik Nagappa
 Noa Shavit
Noa Shavit