Rising above the clouds


[The future of computing will be determined not by individual chips, but by the orchestration of many]
The Technological Imperative
Cloud computing today consists of an endless array of computers sitting in a far off warehouse and rented out by the second. This modality has altered the way we harness computing power, and created a ripe new opportunity to keep up with our exploding demand for more. Gains that were previously defined by cramming more and more power into a single chip can now be achieved by stitching many of them together.
At the same time, our unfettered access to these resources and the exponential growth of data used to feed them have created an unsustainable situation: demand for compute is growing much faster than our ability to meet it.
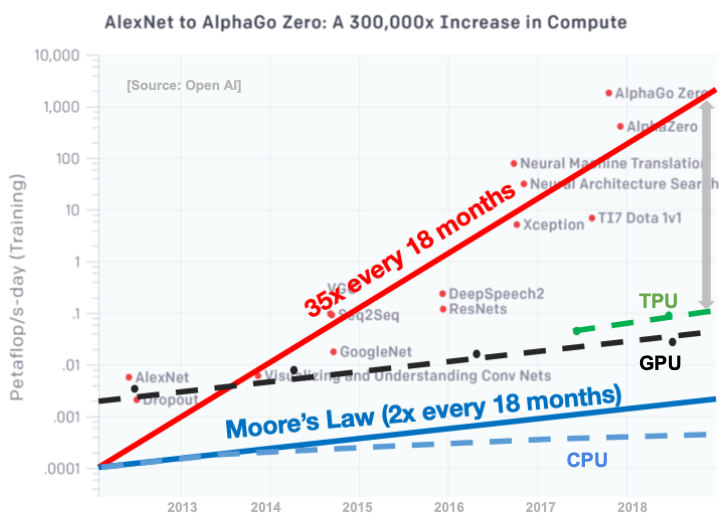
Products like Google’s TPU pods, Nvidia’s DGX, or the Cerebras wafer-scale engine, are noble attempts to address this growing divide. These systems, however, are only half the battle. As they grow larger and more complex, the need to intelligently orchestrate the work running on them grows as well. What happens when only fractions of a workload need the extreme (and extremely expensive!) compute? How do I know which task goes on which chip and when?
The future of computing is undoubtedly distributed, but is saddled with the prospect of diminishing returns. So much effort is spent on boosting our compute resources with comparatively little spent on understanding how best to allocate them. Continuing down this path will leave our computing grid dominated by this ever-growing inefficiency.
The Business Imperative
As cloud adoption rises, these inefficiencies have landed squarely onto corporate balance sheets as a recurring operating expense. Not a small one either. According to a report by Andreessen Horowitz, over $100 Billion is spent each year on cloud services and growing, over 50% of which (we believe) is wasted. The top 30 data infrastructure startups have raised over $8 billion of venture capital in the last 5 years at an aggregate value of $35 billion, per Pitchbook. In addition, the engineering cost of delayed development time and lack of skilled talent further contribute to wasted resources not spent on driving revenue for businesses. While the cloud unleashed a torrent of software innovation, businesses large and small are struggling mightily to find this waste and control their ballooning bills.
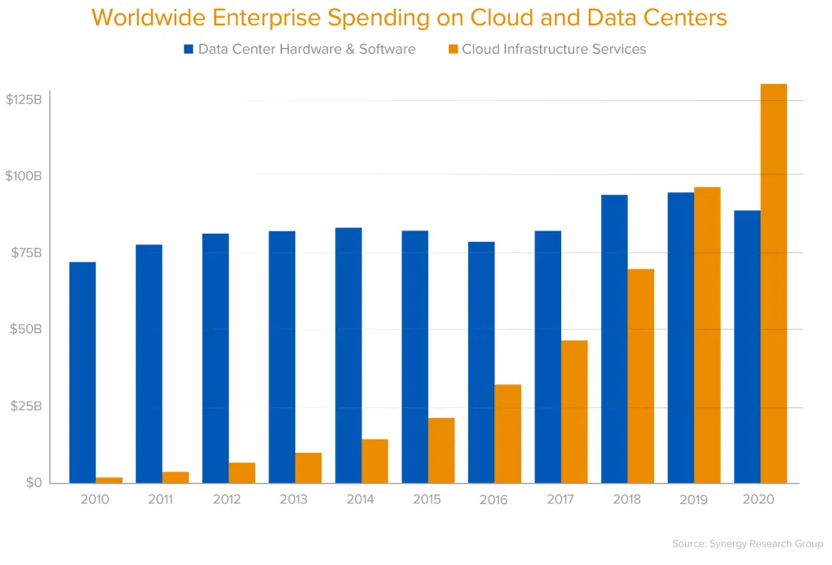
This collision between development speed and the complexity of infrastructure has created a fundamental conundrum in the industry:
How does an engineer launch jobs on the cloud
both easily and efficiently?
Sync Computing is tackling this problem head on. How? Here are a few key pillars:
Step 1) Scale to the cloud based ONLY on the things you care about: cost and time
One of the biggest gaps in today’s cloud computing environment is a simple mechanism to choose computers for a given workload based on metrics which matter to end users. AWS alone offers a continuously evolving menu of around 400 different machines with hundreds of settings and fluctuating prices, and few customers have the time and resources to identify which ones are best for their workload. With unlimited resources available at our fingertips, the most common question asked by customers remains: “Which do I choose?” The seemingly innocuous decision can have a huge impact. The exact same workload run on the wrong computer can run up to 5x slower, cost 5x more, or in some cases crash entirely.
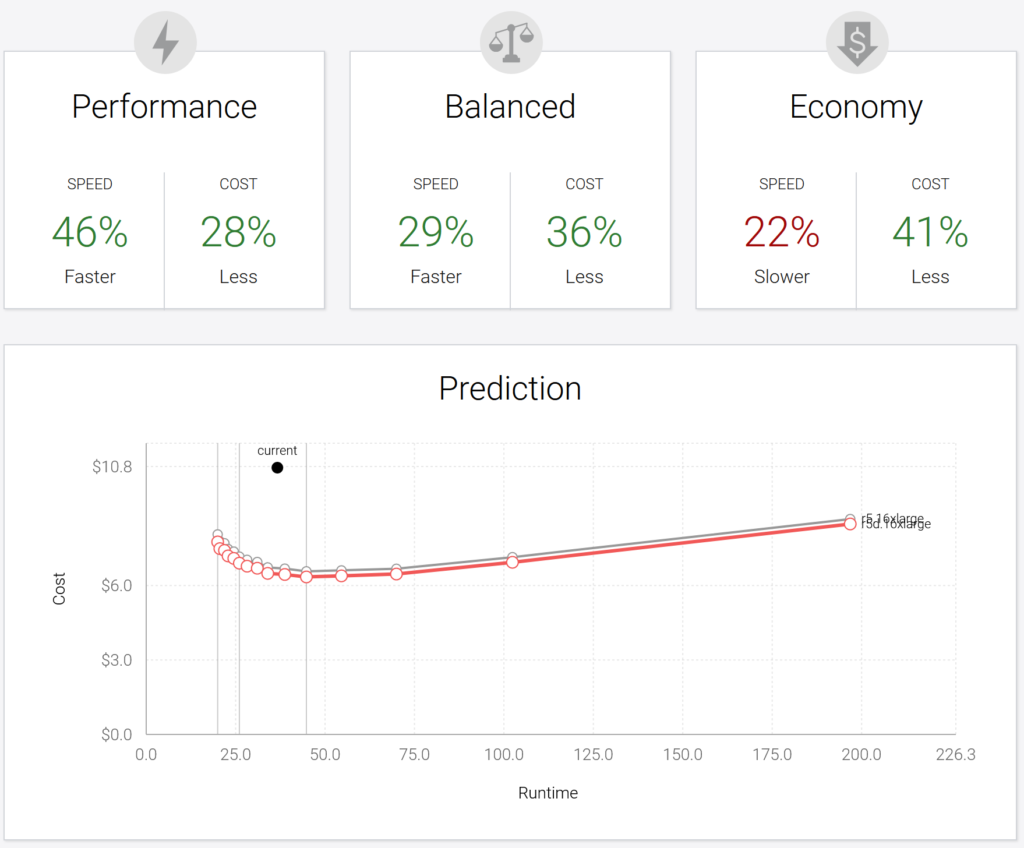
Sync Computing is building a solution to this dilemma, providing users choices based only on the metrics which matter to them most: cost and time.
Interested in seeing how this is helping drive real value right now? Click here
Step 2) Orchestrate the work to meet your goals
With the cost/runtime goals set, matching these goals with the multitude of infrastructure options becomes impossibly hard.
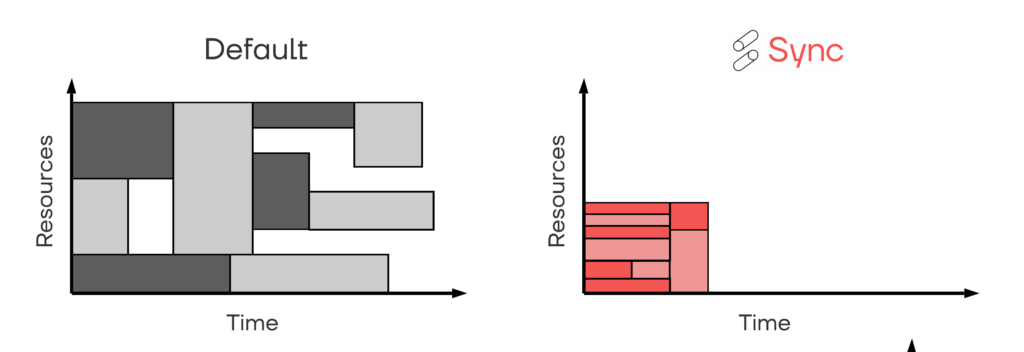
Modern workloads consist of thousands of tasks distributed across hundreds of machines. Sifting through the innumerable combinations of tasks to machines while meeting strict cost and runtime constraints is an intractable mathematical optimization problem. Today’s computing systems are designed to avoid the problem entirely, opting to accept the inefficiency and unpredictability resulting from poor choices.
Sync Computing is developing the world’s first distributed scheduling engine (DSE) designed specifically for this challenge. At its heart is a unique processor capable of finding the best way to distribute work in milliseconds rather than hours or days. The ability to make these calculations in real time and at relevant scale serves as the key to unlocking an untapped well of additional computing power, and as workloads continue to grow, will become a cornerstone for future computing environments.
A New Paradigm
It is high time for a new working model for how we interact with computers, one that is centered around users, and Sync Computing is building the technology required for this shift.
Our mission is to build a dramatically more transparent, more efficient cloud, and propel the next generation of computing innovations.
 Noa Shavit
Noa Shavit
 Jeffrey Chou
Jeffrey Chou