Globally Optimized Data Pipelines On The Cloud — Airflow + Apache Spark


Sync Computing presents a new kind of scheduler capable of automatically optimizing cloud resources for data pipelines to achieve runtime, cost, and reliability goals
Here at Sync, we recently launched our Apache Spark Autoutuner product, which helps people optimize their EMR and Databricks clusters on AWS. Turns out, there’s more on the roadmap for us and we recently published a technical paper our automatic globally optimized resource allocation (AGORA) scheduler, which extends beyond cluster autotuning, and towards the more general concept of resource allocation + scheduling optimization.
In this blog post we explain the high level concepts and how it can help data engineers run their production systems more reliably, hit deadlines, and lower costs — all with a click of a button. We show a simulation of our system on Alibaba’s cluster trace resulted in a 65% reduction in total runtime.
Introduction
Let’s say you’re a data engineer and you manage several production data pipelines via Airflow. Your goal is to achieve job reliability, hit your service level agreements (SLA), and minimize costs for your company. But due to changing data sizes, skew, source code, cloud infrastructure, resource contention, spot pricing, and spot availability, achieving your goals in real-time is basically impossible. So how can Sync help solve this problem? Let’s start with the basics.
The Problem
For simplicity, let’s say your data pipelines are run via Airflow, and each one of your Airflow directed acyclic graphs (DAGs) is composed of several task nodes. For simplicity let’s assume each one of the nodes in the DAG is an Apache Spark job. In the DAG image below in Fig. 1, we see four Apache Spark jobs, named “Index Analysis,” “Sentiment Analysis,” “Airline Delay,” and “Movie Rec.”
You have a deadline and you need this DAG to finish within 800 seconds. How can you achieve that?
One clever way you might think of to try to achieve your goals is to optimize each job separately for runtime. You know 800s is a tight deadline, so you decide to choose configurations for each job that would give you the fastest runtime. There’s no way of figuring out what that might be, so you decide to run a set of experiments: run each job with different configurations and choose the one that gives you the fastest runtime.
Being a data engineer, you could even set up this whole process to be automated. Once you’ve figured out the configurations separately, you can use those configurations to run the DAG with the standard Airflow scheduler. However, what happens in this example is these jobs will be launched serially, maximizing the cluster each time, and it does not meet your deadline. In the figure below we see the number of vCPUs available in a cluster on the y-axis and time on the x-axis.
You tried to optimize each job separately for the fastest runtime, but it’s still not meeting the requirement. What could you do now to accomplish this goal? Just try increasing the cluster size to hopefully speed up the jobs? That could work but how much larger? You could run more experiments, but now the problem bounds are increasing and the growing list of experiments would take forever to finish. Also, changing the resources for an Apache Spark job is notoriously difficult, as you may cause a crash or a memory error if you don’t also change the corresponding Apache Spark configurations.
The Solution
To really see how best you can reallocate resources to hit the 800s SLA, we’ll have to look at the predicted runtime vs. resources curve for each Apache Spark job independently. For the four jobs, the predicted performance plots are shown in Fig. 3 below across 4 different instances on AWS.
We can see that depending on the job and the hardware, the number of nodes and runtime are very different depending on the job.
With this information, we can use AGORA to solve the scheduling problem to properly allocate resources, and re-run the DAG. Now we see that the 800s SLA is achieved, without changing the cluster size, changing Spark configurations, and obeying the DAG dependencies. What AGORA does is interesting, we see the “purple’ job gets massively compressed in terms of resources, with only a small impact on runtime. Whereas the “green” job doesn’t change much because it may blow up the runtime. Understanding which jobs can be “squished” and which cannot is critical for this optimization. In some sense, it’s a game of “squishy Tetris”!
The Catch
Well, that looks great, what is so hard about that? Well, it turns out that scheduling problem is what is known in the math world as an NP-hard optimization problem. Actually solving that problem explodes into a very very difficult problem to solve quickly. With just those 4 jobs, we can see from the graphs below that to solve that schedule it can take over 1000 seconds, via brute force methods. Obviously, nobody wants to wait for that.
The other issue is we need to predict those runtime vs. resources graphs with just a few prior runs. We don’t want to actually re-run jobs 100’s of times just to run it well once. This is where our Gradient product comes into play. With just 1 log, we can predict the cost-runtime performance for various hardware and optimized spark configurations.
At Sync Computing, we’ve solved both issues:
- Scheduling modeling & solve time: We mathematically modeled Apache Spark, cloud resources, and cloud economics to an optimization problem we can solve extremely quickly. More details on the math can be found in the technical paper.
- Predicting performance on alternative hardware: Our Gradient for Apache Spark takes in one log and can predict the performance across various machines — simultaneously accounting for hardware options, costs, spot availability, and Apache Spark configurations. See our case study here.
Goal based optimization
In the simple example above, the priority was to hit an SLA deadline, by reallocating resources. It turns out, we can also set other priorities. One obvious one is cost savings for cloud usage, in which the cost of the instances is prioritized over the total runtime. In this example, we utilized more realistics DAGs, as shown in the image below:
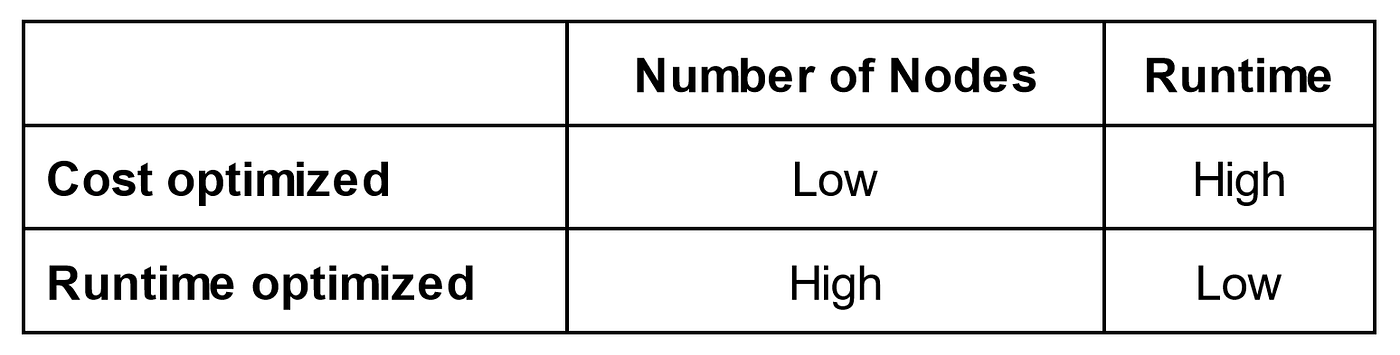
For cost based optimization, what typically happens is fewer resources (less nodes) are used for each job which usually results in longer runtimes, albeit lower costs. Alternatively, we can be runtime optimized, in which more resources are used, albeit at higher costs. The simple table below highlights this general relationship. Of course knowing the exact number of nodes and runtime is highly dependent on the exact job.
When we run our goal based optimization, we show that for DAG1 we can achieve a runtime savings of 37%, or a cost savings of 78%. For DAG2, we can achieve a runtime savings is 45%, or a cost savings of 72% — it all depends on what you’re trying to achieve.
Fig. 8. Optimizing the schedule for DAGs 1 and 2 to minimize cloud costs.
Of course other prioritization can be implemented as well, or even a mix. For example, some subset of the DAGs need to hit SLA deadlines, whereas some other subset need to be cost minimized. From a user’s perspective, all the user has to do is set the high level goals, and AGORA automatically reconfigures and reschedules the cluster to hit all goals simultaneously. The engineer can just sit back and relax.
The Solution at Scale — Alibaba Cluster Trace with 14 million tasks
So what happens if we apply our solution in a real-world large system? Fortunately, Alibaba publishes their cluster traces for academic purposes. The 2018 Alibaba cluster trace includes batch jobs run on 4034 machines over a period of 8 days. There are over 4 million jobs (represented as DAGs) and over 14 million tasks. Each machine has 96 cores and an undisclosed amount of memory.
When we simulate our solution at scale, we demonstrated total runtime/cost reduction of 65%, across the entire cluster. At the scale of Alibaba, 65% reduction over 14 million tasks is a massive amount of savings.
Conclusion
We hope this article illuminates the possibilities in terms of the impact of looking globally across entire data pipelines. Here are the main take aways:
- There are massive gains if you look globally: The gains we show here only get larger as we look at larger systems. Optimizing across low level hardware to high level DAGs reveals a massive opportunity.
- The goals are flexible: Although we only show cost and runtime optimizations, the model is incredibly general and can account for reliability, “green” computing, or any other priority you’d like to encode.
- The problem is everywhere: In this write up we focused on Airflow and Apache Spark. In reality, this general resource allocation and scheduling problem is fundamental to computer science itself — Extending to other large scale jobs (machine learning, simulations, high-performance computing), containers, microservices, etc.
At Sync, we built the Gradient for Apache Spark, but that’s just the tip of the iceberg for us. AGORA is currently being built and tested internally here at Sync with early users. If you’d like a demo, please feel free to reach out to see if we can help you achieve your goals.
We’ll follow up this article with more concrete customer based use-cases to really demonstrate the applicability and benefits of AGORA. Stay tuned!
 Noa Shavit
Noa Shavit