Developing Gradient Part I

Building data insights from scratch

Introduction
Sync recently introduced Gradient, a tool that helps data engineers manage and optimize their compute infrastructure. The primary facet of Gradient is a Project which groups a sequence of runs of a Databricks job. After each run, the Spark eventlog and cluster information is sent to Sync. That accumulated project data is then fed into our recommendation engine, which gives back an optimized cluster configuration to make the next run of your job run at lower cost while keeping you on target for your SLA.
If that sounds like a challenging product to develop, then you’d be right! In fact, much of the challenge comes from getting the data needed to create the predictive engine, and we thought that this story and our strategy for tackling it was worth sharing.
In this blog post we give some insight into the development process of Gradient, with focus on the internal testing infrastructure that enabled the early development and validation of the product.
The Challenge
In the early days of development, the Gradient team was in a really tight spot. You see, at its heart, Gradient is a data insights product that requires a feedback loop of job runs and recommendations that get implemented in subsequent runs. You need this feedback loop to both assess the performance of the product and have a hope at improving the quality of recommendations.
However, injecting yourself into a workflow is a tall order for customers who are rightly protective of their data pipelines, especially when the request comes from a young company with an unproved track record (even if our team – being real here – is totally awesome). Consultant-like interactions were mildly successful, but the update cycle was often a week or more, much too slow to have a hope of making meaningful progress. It was obvious then that at the start, we needed a solution that could get us a lot of data for many different jobs and many different cluster configurations … and didn’t source from customers.
The Solution
So how did we design, test, and validate our recommendation engine? We built infrastructure that would operate a Gradient Project using our own applications as a source. This system would select a Databricks Job (e.g. a TPC-DS query), create a Project, choose an initial “cold start” cluster configuration, and then cyclically run the job using Gradient’s recommendations to inform subsequent runs. Effectively we became a consumer of our own product.
We also built an orchestrator that could run these Projects at scale using a variety of hardware configurations and applications. After selecting a few configurations, a team member could be spinning up hundreds of Projects with data available for analysis the next day.
At the foundation of the whole system is a bank of jobs that ensures we capture a variety of workloads in our testing, mitigating as much bias as possible from our data. And in a stroke of genius we named this testing project the Job Bank.

Figure: Job Bank diagram. A Spark application is selected from the Job Bank vault and an initial hardware configuration is selected. After an initial run of the job, the results are passed into Gradient which then informs the subsequent run. Many instances of this process are orchestrated together so testing can occur at scale.
The Job Bank enabled two key vectors for performance assessment and improvement.
- Having a parent run, its recommendation, and the informed child run allow us to assess the runtime prediction accuracy. Our data science team can then dig into these results, looking for scenarios where we perform better or worse. Naturally, this informs modeling and constraints to improve the quality of our recommendations.
- Since all of these jobs are run internally at Sync, we have full access to the cost and usage reports from both AWS and Databricks. Not only does this allow us to validate our cost modeling, but it lets us assess Gradient’s performance using cost-actual data which can be considered independently from our prediction accuracy. Look out for more details on cost performance in an upcoming blog!
The benefits of having a system like this were apparent almost immediately. It helped us uncover bugs and new edge cases, improve the engineering, and gave us clear direction in improving the runtime prediction accuracy. Most importantly, it enabled us to develop the recommendation engine into a state that we feel confident will provide customers reliable job management and real cost savings.
Some example data generated with the Job Bank is shown below. The general process to generate this data was
- Cold-start by selecting a Spark application and running it with an initial hardware configuration.
- Submit the resulting run data to Gradient and get a recommendation.
- Generate a child run using the recommended hardware configuration.
The plot shows the runtime prediction error (predicted runtime minus child runtime) for about 20 unique applications with 3-5 cold-starts each. The error is plotted against the change in instance size from the parent to the child. In this particular visualization, we can see that predicted error is correlated with how much the instance size changes. These kinds of insights help us determine where to focus our efforts in improving the algorithm.
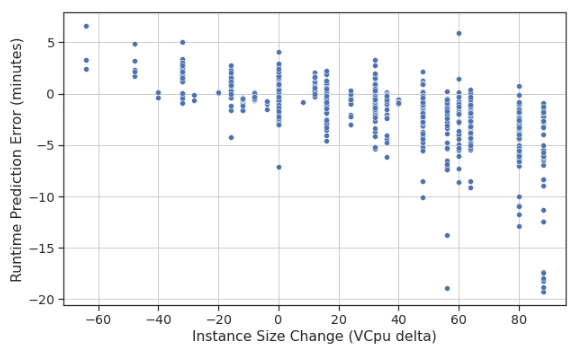
Figure: Example runtime prediction accuracy data generated using Job Bank. Each point is the runtime prediction error calculated by differencing a predicted runtime with the actual runtime using the predicted configuration.
Looking Forward
In the world of data it’s customer data that rules. As our user base grows and we have more feedback from those users, our internal system will become less relevant and it’s the customer recommendation cycles that will drive future development. After all, the variety of jobs and configurations that we might assess in the Job Bank is negligible compared to the domain of jobs that exist out in the wild. We look forward with eagerness and excitement to seeing how best we can improve Gradient in the future with customers at the center of mind.
 Noa Shavit
Noa Shavit
 Jeffrey Chou
Jeffrey Chou